
Latest recommendations

| Id | Title | Authors | Abstract | Picture▼ | Thematic fields | Recommender | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
11 Sep 2023
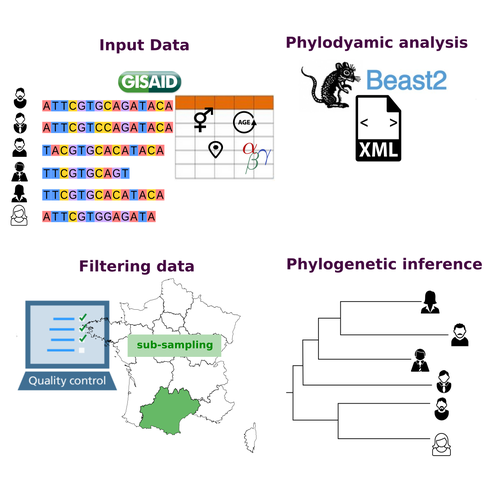
COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequencesA pipeline to select SARS-CoV-2 sequences for reliable phylodynamic analysesRecommended by Emmanuelle Lerat based on reviews by Gabriel Wallau and Bastien BoussauPhylodynamic approaches enable viral genetic variation to be tracked over time, providing insight into pathogen phylogenetic relationships and epidemiological dynamics. These are important methods for monitoring viral spread, and identifying important parameters such as transmission rate, geographic origin and duration of infection [1]. This knowledge makes it possible to adjust public health measures in real-time and was important in the case of the COVID-19 pandemic [2]. However, these approaches can be complicated to use when combining a very large number of sequences. This was particularly true during the COVID-19 pandemic, when sequencing data representing millions of entire viral genomes was generated, with associated metadata enabling their precise identification. Danesh et al. [3] present a bioinformatics pipeline, CovFlow, for selecting relevant sequences according to user-defined criteria to produce files that can be used directly for phylodynamic analyses. The selection of sequences first involves a quality filter on the size of the sequences and the absence of unresolved bases before being able to make choices based on the associated metadata. Once the sequences are selected, they are aligned and a time-scaled phylogenetic tree is inferred. An output file in a format directly usable by BEAST 2 [4] is finally generated. To illustrate the use of the pipeline, Danesh et al. [3] present an analysis of the Delta variant in two regions of France. They observed a delay in the start of the epidemic depending on the region. In addition, they identified genetic variation linked to the start of the school year and the extension of vaccination, as well as the arrival of a new variant. This tool will be of major interest to researchers analysing SARS-CoV-2 sequencing data, and a number of future developments are planned by the authors. References [1] Baele G, Dellicour S, Suchard MA, Lemey P, Vrancken B. 2018. Recent advances in computational phylodynamics. Curr Opin Virol. 31:24-32. https://doi.org/10.1016/j.coviro.2018.08.009 [2] Attwood SW, Hill SC, Aanensen DM, Connor TR, Pybus OG. 2022. Phylogenetic and phylodynamic approaches to understanding and combating the early SARS-CoV-2 pandemic. Nat Rev Genet. 23:547-562. https://doi.org/10.1038/s41576-022-00483-8 [3] Danesh G, Boennec C, Verdurme L, Roussel M, Trombert-Paolantoni S, Visseaux B, Haim-Boukobza S, Alizon S. 2023. COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences. bioRxiv, ver. 7 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.06.17.496544 [4] Bouckaert R, Heled J, Kühnert D, Vaughan T, Wu C-H et al. 2014. BEAST 2: a software platform for Bayesian evolutionary analysis. PLoS Comput Biol 10: e1003537. https://doi.org/10.1371/journal.pcbi.1003537 | COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences | Gonché Danesh, Corentin Boennec, Laura Verdurme, Mathilde Roussel, Sabine Trombert-Paolantoni, Benoit Visseaux, Stephanie Haim-Boukobza, Samuel Alizon | <p style="text-align: justify;">Phylodynamic analyses generate important and timely data to optimise public health response to SARS-CoV-2 outbreaks and epidemics. However, their implementation is hampered by the massive amount of sequence data and... | | Bioinformatics, Evolutionary genomics | Emmanuelle Lerat | 2022-12-12 09:04:01 | ||
23 Aug 2022

A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomicsGoat ancient DNA analysis unveils a new lineage that may have hybridized with domestic goatsRecommended by Laura Botigué based on reviews by Torsten Günther and 1 anonymous reviewerThe genomic analysis of ancient remains has revolutionized the study of the past over the last decade. On top of the discoveries related to human evolution, plant and animal archaeogenomics has been used to gain new insights into the domestication process and the dispersal of domestic forms. In this study, Daly and colleagues analyse the genomic data from seven goat specimens from the Epipalaeolithic recovered from the Direkli Cave in the Taurus Mountains in southern Turkey. They also generate new genomic data from Capra lineages across the phylogeny, contributing to the availability of genomic resources for this genus. Analysis of the ancient remains is compared to modern genomic variability and sheds light on the complexity of the Tur wild Capra lineages and their relationship with domestic goats and their wild ancestors. Authors find that during the Late Pleistocene in the Taurus Mountains wild goats from the Tur lineage, today restricted to the Caucasus region, were not rare and cohabited with Bezoar, the wild goats that are the ancestors of domestic goats. They identify the Direkli Cave specimens as a lineage separate from the A modified D statistic, Dex, is developed to examine the contribution of the ancient Tur lineage in domestic goats through time and space. Dex measures the relative degree of allele sharing, derived specifically in a selected genome or group of genomes, and may have some utility in genera with complex admixture histories or admixture from ghost lineages. Results confirm that Neolithic European goat had an excess of allele sharing with this ancient Tur lineage, something that is absent in contemporary goats eastwards or in modern goats. Interspecific gene flow is not uncommon among mammals, but the case of Capra has the additional motivation of understanding the origins of the domestic species. This work uncovers an ancient Tur lineage that is different from the modern ones and is additionally found in another geographic area. Furthermore, evidence shows that this ancient lineage exhibits substantial amounts of allele sharing with the wild ancestor of the domestic goat, but also with the Neolithic Eurasian domestic goats, highlighting the complexity of the domestication process. This work has also important implications in understanding the effect of over-hunting and habitat disruption during the Anthropocene on the evolution of the Capra genus. The availability of more ancient specimens and better coverage of the modern genomic variability can help quantifying the lineages that went lost and identify the causes of their extinction. This work is limited by the current availability of whole genomes from modern Capra specimens, but pieces of evidence as well that an effort is needed to obtain more genomic data from ancient goats from different geographic ranges to determine to what extent these lineages contributed to goat domestication. References Daly KG, Arbuckle BS, Rossi C, Mattiangeli V, Lawlor PA, Mashkour M, Sauer E, Lesur J, Atici L, Cevdet CM and Bradley DG (2022) A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomics. bioRxiv, 2022.04.08.487619, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.08.487619 | A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomics | Kevin G. Daly, Benjamin S. Arbuckle, Conor Rossi, Valeria Mattiangeli, Phoebe A. Lawlor, Marjan Mashkour, Eberhard Sauer, Joséphine Lesur, Levent Atici, Cevdet Merih Erek, Daniel G. Bradley | <p>Direkli Cave, located in the Taurus Mountains of southern Turkey, was occupied by Late Epipaleolithic hunters-gatherers for the seasonal hunting and processing of game including large numbers of wild goats. We report genomic data from new and p... | | Evolutionary genomics, Population genomics, Vertebrates | Laura Botigué | 2022-04-15 12:05:47 | ||
07 Sep 2023
The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological nichesNatural variation and adaptation in Brachypodium distachyonRecommended by Josep Casacuberta based on reviews by Thibault Leroy and 1 anonymous reviewerIdentifying the genetic factors that allow plant adaptation is a major scientific question that is particularly relevant in the face of the climate change that we are already experiencing. To address this, it is essential to have genetic information on a high number of accessions (i.e., plants registered with unique accession numbers) growing under contrasting environmental conditions. There is already an important number of studies addressing these issues in the plant Arabidopsis thaliana, but there is a need to expand these analyses to species that play key roles in wild ecosystems and are close to very relevant crops, as is the case of grasses. The work of Minadakis, Roulin and co-workers (1) presents a Brachypodium distachyon panel of 332 fully sequences accessions that covers the whole species distribution across a wide range of bioclimatic conditions, which will be an invaluable tool to fill this gap. In addition, the authors use this data to start analyzing the population structure and demographic history of this plant, suggesting that the species experienced a shift of its distribution following the Last Glacial Maximum, which may have forced the species into new habitats. The authors also present a modeling of the niches occupied by B. distachyon together with an analysis of the genetic clades found in each of them, and start analyzing the different adaptive loci that may have allowed the species’ expansion into different bioclimatic areas. In addition to the importance of the resources made available by the authors for the scientific community, the analyses presented are well done and carefully discussed, and they highlight the potential of these new resources to investigate the genetic bases of plant adaptation. References 1. Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin. The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological niches. bioRxiv, 2023.06.01.543285, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.01.543285 | The demographic history of the wild crop relative *Brachypodium distachyon* is shaped by distinct past and present ecological niches | Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin | <p style="text-align: justify;">Closely related to economically important crops, the grass <em>Brachypodium distachyon</em> has been originally established as a pivotal species for grass genomics but more recently flourished as a model for develop... | | Evolutionary genomics, Functional genomics, Plants, Population genomics | Josep Casacuberta | 2023-06-14 15:28:30 | ||
19 Jul 2021
TransPi - a comprehensive TRanscriptome ANalysiS PIpeline for de novo transcriptome assemblyTransPI: A balancing act between transcriptome assemblersRecommended by Oleg Simakov based on reviews by Gustavo Sanchez and Juan Daniel Montenegro CabreraEver since the introduction of the first widely usable assemblers for transcriptomic reads (Huang and Madan 1999; Schulz et al. 2012; Simpson et al. 2009; Trapnell et al. 2010, and many more), it has been a technical challenge to compare different methods and to choose the “right” or “best” assembly. It took years until the first widely accepted set of benchmarks beyond raw statistical evaluation became available (e.g., Parra, Bradnam, and Korf 2007; Simão et al. 2015). However, an approach to find the right balance between the number of transcripts or isoforms vs. evolutionary completeness measures has been lacking. This has been particularly pronounced in the field of non-model organisms (i.e., wild species that lack a genomic reference). Often, studies in this area employed only one set of assembly tools (the most often used to this day being Trinity, Haas et al. 2013; Grabherr et al. 2011). While it was relatively straightforward to obtain an initial assembly, its validation, annotation, as well its application to the particular purpose that the study was designed for (phylogenetics, differential gene expression, etc) lacked a clear workflow. This led to many studies using a custom set of tools with ensuing various degrees of reproducibility. TransPi (Rivera-Vicéns et al. 2021) fills this gap by first employing a meta approach using several available transcriptome assemblers and algorithms to produce a combined and reduced transcriptome assembly, then validating and annotating the resulting transcriptome. Notably, TransPI performs an extensive analysis/detection of chimeric transcripts, the results of which show that this new tool often produces fewer misassemblies compared to Trinity. TransPI not only generates a final report that includes the most important plots (in clickable/zoomable format) but also stores all relevant intermediate files, allowing advanced users to take a deeper look and/or experiment with different settings. As running TransPi is largely automated (including its installation via several popular package managers), it is very user-friendly and is likely to become the new "gold standard" for transcriptome analyses, especially of non-model organisms. References Grabherr MG, Haas BJ, Yassour M, Levin JZ, Thompson DA, Amit I, Adiconis X, Fan L, Raychowdhury R, Zeng Q, Chen Z, Mauceli E, Hacohen N, Gnirke A, Rhind N, di Palma F, Birren BW, Nusbaum C, Lindblad-Toh K, Friedman N, Regev A (2011) Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nature Biotechnology, 29, 644–652. https://doi.org/10.1038/nbt.1883 Haas BJ, Papanicolaou A, Yassour M, Grabherr M, Blood PD, Bowden J, Couger MB, Eccles D, Li B, Lieber M, MacManes MD, Ott M, Orvis J, Pochet N, Strozzi F, Weeks N, Westerman R, William T, Dewey CN, Henschel R, LeDuc RD, Friedman N, Regev A (2013) De novo transcript sequence reconstruction from RNA-seq using the Trinity platform for reference generation and analysis. Nature Protocols, 8, 1494–1512. https://doi.org/10.1038/nprot.2013.084 Huang X, Madan A (1999) CAP3: A DNA Sequence Assembly Program. Genome Research, 9, 868–877. https://doi.org/10.1101/gr.9.9.868 Parra G, Bradnam K, Korf I (2007) CEGMA: a pipeline to accurately annotate core genes in eukaryotic genomes. Bioinformatics, 23, 1061–1067. https://doi.org/10.1093/bioinformatics/btm071 Rivera-Vicéns RE, Garcia-Escudero CA, Conci N, Eitel M, Wörheide G (2021) TransPi – a comprehensive TRanscriptome ANalysiS PIpeline for de novo transcriptome assembly. bioRxiv, 2021.02.18.431773, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.02.18.431773 Schulz MH, Zerbino DR, Vingron M, Birney E (2012) Oases: robust de novo RNA-seq assembly across the dynamic range of expression levels. Bioinformatics, 28, 1086–1092. https://doi.org/10.1093/bioinformatics/bts094 Simão FA, Waterhouse RM, Ioannidis P, Kriventseva EV, Zdobnov EM (2015) BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics, 31, 3210–3212. https://doi.org/10.1093/bioinformatics/btv351 Simpson JT, Wong K, Jackman SD, Schein JE, Jones SJM, Birol İ (2009) ABySS: A parallel assembler for short read sequence data. Genome Research, 19, 1117–1123. https://doi.org/10.1101/gr.089532.108 Trapnell C, Williams BA, Pertea G, Mortazavi A, Kwan G, van Baren MJ, Salzberg SL, Wold BJ, Pachter L (2010) Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. Nature Biotechnology, 28, 511–515. https://doi.org/10.1038/nbt.1621 | TransPi - a comprehensive TRanscriptome ANalysiS PIpeline for de novo transcriptome assembly | Ramon E Rivera-Vicens, Catalina Garcia-Escudero, Nicola Conci, Michael Eitel, Gert Wörheide | <p style="text-align: justify;">The use of RNA-Seq data and the generation of de novo transcriptome assemblies have been pivotal for studies in ecology and evolution. This is distinctly true for non-model organisms, where no genome information is ... | | Bioinformatics, Evolutionary genomics | Oleg Simakov | 2021-02-18 20:56:08 | ||
09 Aug 2023
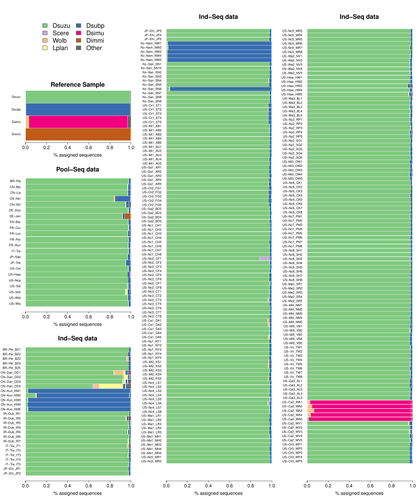
Efficient k-mer based curation of raw sequence data: application in Drosophila suzukiiDecontaminating reads, not contigsRecommended by Nicolas Galtier based on reviews by Marie Cariou and Denis BaurainContamination, the presence of foreign DNA sequences in a sample of interest, is currently a major problem in genomics. Because contamination is often unavoidable at the experimental stage, it is increasingly recognized that the processing of high-throughput sequencing data must include a decontamination step. This is usually performed after the many sequence reads have been assembled into a relatively small number of contigs. Dubious contigs are then discarded based on their composition (e.g. GC-content) or because they are highly similar to a known piece of DNA from a foreign species. Here [1], Mathieu Gautier explores a novel strategy consisting in decontaminating reads, not contigs. Why is this promising? Assembly programs and algorithms are complex, and it is not easy to predict, or monitor, how they handle contaminant reads. Ideally, contaminant reads will be assembled into obvious contaminant contigs. However, there might be more complex situations, such as chimeric contigs with alternating genuine and contaminant segments. Decontaminating at the read level, if possible, should eliminate such unfavorable situations where sequence information from contaminant and target samples are intimately intertwined by an assembler. To achieve this aim, Gautier proposes to use methods initially designed for the analysis of metagenomic data. This is pertinent since the decontamination process involves considering a sample as a mixture of different sources of DNA. The programs used here, CLARK and CLARK-L, are based on so-called k-mer analysis, meaning that the similarity between a read to annotate and a reference sequence is measured by how many sub-sequences (of length 31 base pairs for CLARK and 27 base pairs for CLARK-L) they share. This is notoriously more efficient than traditional sequence alignment algorithms when it comes to comparing a very large number of (most often unrelated) sequences. This is, therefore, a reference-based approach, in which the reads from a sample are assigned to previously sequenced genomes based on k-mer content. This original approach is here specifically applied to the case of Drosophila suzukii, an invasive pest damaging fruit production in Europe and America. Fortunately, Drosophila is a genus of insects with abundant genomic resources, including high-quality reference genomes in dozens of species. Having calibrated and validated his pipeline using data sets of known origins, Gautier quantifies in each of 258 presumed D. suzukii samples the proportion of reads that likely belong to other species of fruit flies, or to fruit fly-associated microbes. This proportion is close to one in 16 samples, which clearly correspond to mis-labelled individuals. It is non-negligible in another ~10 samples, which really correspond to D. suzukii individuals. Most of these reads of unexpected origin are contaminants and should be filtered out. Interestingly, one D. suzukii sample contains a substantial proportion of reads from the closely related D. subpulchera, which might instead reflect a recent episode of gene flow between these two species. The approach, therefore, not only serves as a crucial technical step, but also has the potential to reveal biological processes. Gautier's thorough, well-documented work will clearly benefit the ongoing and future research on D. suzuki, and Drosophila genomics in general. The author and reviewers rightfully note that, like any reference-based approach, this method is heavily dependent on the availability and quality of reference genomes - Drosophila being a favorable case. Building the reference database is a key step, and the interpretation of the output can only be made in the light of its content and gaps, as illustrated by Gautier's careful and detailed discussion of his numerous results. This pioneering study is a striking demonstration of the potential of metagenomic methods for the decontamination of high-throughput sequence data at the read level. The pipeline requires remarkably few computing resources, ensuring low carbon emission. I am looking forward to seeing it applied to a wide range of taxa and samples.
Reference [1] Gautier Mathieu. Efficient k-mer based curation of raw sequence data: application in Drosophila suzukii. bioRxiv, 2023.04.18.537389, ver. 2, peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.04.18.537389 | Efficient k-mer based curation of raw sequence data: application in *Drosophila suzukii* | Gautier Mathieu | <p>Several studies have highlighted the presence of contaminated entries in public sequence repositories, calling for special attention to the associated metadata. Here, we propose and evaluate a fast and efficient kmer-based approach to assess th... | | Bioinformatics, Population genomics | Nicolas Galtier | 2023-04-20 22:05:13 | ||
07 Oct 2021

Fine-scale quantification of GC-biased gene conversion intensity in mammalsA systematic approach to the study of GC-biased gene conversion in mammalsRecommended by Carina Farah Mugal based on reviews by Fanny Pouyet , David Castellano and 1 anonymous reviewerThe role of GC-biased gene conversion (gBGC) in molecular evolution has interested scientists for the last two decades since its discovery in 1999 (Eyre-Walker 1999; Galtier et al. 2001). gBGC is a process that is associated with meiotic recombination, and is characterized by a transmission distortion in favor of G and C over A and T alleles at GC/AT heterozygous sites that occur in the vicinity of recombination-inducing double-strand breaks (Duret and Galtier 2009; Mugal et al. 2015). This transmission distortion results in a fixation bias of G and C alleles, equivalent to directional selection for G and C (Nagylaki 1983). The fixation bias subsequently leads to a correlation between recombination rate and GC content across the genome, which has served as indirect evidence for the prevalence of gBGC in many organisms. The fixation bias also produces shifts in the allele frequency spectrum (AFS) towards higher frequencies of G and C alleles. These molecular signatures of gBGC provide a means to quantify the strength of gBGC and study its variation among species and across the genome. Following this idea, first Lartillot (2013) and Capra et al. (2013) developed phylogenetic methodology to quantify gBGC based on substitutions, and De Maio et al. (2013) combined information on polymorphism into a phylogenetic setting. Complementary to the phylogenetic methods, later Glemin et al. (2015) developed a method that draws information solely from polymorphism data and the shape of the AFS. Application of these methods to primates (Capra et al. 2013; De Maio et al. 2013; Glemin et al. 2015) and mammals (Lartillot 2013) supported the notion that variation in the strength of gBGC across the genome reflects the dynamics of the recombination landscape, while variation among species correlates with proxies of the effective population size. However, application of the polymorphism-based method by Glemin et al. (2015) to distantly related Metazoa did not confirm the correlation with effective population size (Galtier et al. 2018). Here, Galtier (2021) introduces a novel phylogenetic approach applicable to the study of closely related species. Specifically, Galtier introduces a statistical framework that enables the systematic study of variation in the strength of gBGC among species and among genes. In addition, Galtier assesses fine-scale variation of gBGC across the genome by means of spatial autocorrelation analysis. This puts Galtier in a position to study variation in the strength of gBGC at three different scales, i) among species, ii) among genes, and iii) within genes. Galtier applies his method to four families of mammals, Hominidae, Cercopithecidae, Bovidae, and Muridae and provides a thorough discussion of his findings and methodology. Galtier found that the strength of gBGC correlates with proxies of the effective population size (Ne), but that the slope of the relationship differs among the four families of mammals. Given the relationship between the population-scaled strength of gBGC B = 4Neb, this finding suggests that the conversion bias (b) could vary among mammalian species. Variation in b could either result from differences in the strength of the transmission distortion (Galtier et al. 2018) or evolutionary changes in the rate of recombination (Boman et al. 2021). Alternatively, Galtier suggests that also systematic variation in proxies of Ne could lead to similar observations. Finally, the present study reports intriguing inter-species differences between the extent of variation in the strength of gBGC among and within genes, which are interpreted in consideration of the recombination dynamics in mammals. References Boman J, Mugal CF, Backström N (2021) The Effects of GC-Biased Gene Conversion on Patterns of Genetic Diversity among and across Butterfly Genomes. Genome Biology and Evolution, 13. https://doi.org/10.1093/gbe/evab064 Capra JA, Hubisz MJ, Kostka D, Pollard KS, Siepel A (2013) A Model-Based Analysis of GC-Biased Gene Conversion in the Human and Chimpanzee Genomes. PLOS Genetics, 9, e1003684. https://doi.org/10.1371/journal.pgen.1003684 De Maio N, Schlötterer C, Kosiol C (2013) Linking Great Apes Genome Evolution across Time Scales Using Polymorphism-Aware Phylogenetic Models. Molecular Biology and Evolution, 30, 2249–2262. https://doi.org/10.1093/molbev/mst131 Duret L, Galtier N (2009) Biased Gene Conversion and the Evolution of Mammalian Genomic Landscapes. Annual Review of Genomics and Human Genetics, 10, 285–311. https://doi.org/10.1146/annurev-genom-082908-150001 Eyre-Walker A (1999) Evidence of Selection on Silent Site Base Composition in Mammals: Potential Implications for the Evolution of Isochores and Junk DNA. Genetics, 152, 675–683. https://doi.org/10.1093/genetics/152.2.675 Galtier N (2021) Fine-scale quantification of GC-biased gene conversion intensity in mammals. bioRxiv, 2021.05.05.442789, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.05.05.442789 Galtier N, Piganeau G, Mouchiroud D, Duret L (2001) GC-Content Evolution in Mammalian Genomes: The Biased Gene Conversion Hypothesis. Genetics, 159, 907–911. https://doi.org/10.1093/genetics/159.2.907 Galtier N, Roux C, Rousselle M, Romiguier J, Figuet E, Glémin S, Bierne N, Duret L (2018) Codon Usage Bias in Animals: Disentangling the Effects of Natural Selection, Effective Population Size, and GC-Biased Gene Conversion. Molecular Biology and Evolution, 35, 1092–1103. https://doi.org/10.1093/molbev/msy015 Glémin S, Arndt PF, Messer PW, Petrov D, Galtier N, Duret L (2015) Quantification of GC-biased gene conversion in the human genome. Genome Research, 25, 1215–1228. https://doi.org/10.1101/gr.185488.114 Lartillot N (2013) Phylogenetic Patterns of GC-Biased Gene Conversion in Placental Mammals and the Evolutionary Dynamics of Recombination Landscapes. Molecular Biology and Evolution, 30, 489–502. https://doi.org/10.1093/molbev/mss239 Mugal CF, Weber CC, Ellegren H (2015) GC-biased gene conversion links the recombination landscape and demography to genomic base composition. BioEssays, 37, 1317–1326. https://doi.org/10.1002/bies.201500058 Nagylaki T (1983) Evolution of a finite population under gene conversion. Proceedings of the National Academy of Sciences, 80, 6278–6281. https://doi.org/10.1073/pnas.80.20.6278 | Fine-scale quantification of GC-biased gene conversion intensity in mammals | Nicolas Galtier | <p style="text-align: justify;">GC-biased gene conversion (gBGC) is a molecular evolutionary force that favours GC over AT alleles irrespective of their fitness effect. Quantifying the variation in time and across genomes of its intensity is key t... | | Evolutionary genomics, Population genomics, Vertebrates | Carina Farah Mugal | 2021-05-25 09:25:52 | ||
18 Jul 2022
CulebrONT: a streamlined long reads multi-assembler pipeline for prokaryotic and eukaryotic genomesA flexible and reproducible pipeline for long-read assembly and evaluationRecommended by Raúl Castanera based on reviews by Benjamin Istace and Valentine MurigneuxThird-generation sequencing has revolutionised de novo genome assembly. Thanks to this technology, genome reference sequences have evolved from fragmented drafts to gapless, telomere-to-telomere genome assemblies. Long reads produced by Oxford Nanopore and PacBio technologies can span structural variants and resolve complex repetitive regions such as centromeres, unlocking previously inaccessible genomic information. Nowadays, many research groups can afford to sequence the genome of their working model using long reads. Nevertheless, genome assembly poses a significant computational challenge. Read length, quality, coverage and genomic features such as repeat content can affect assembly contiguity, accuracy, and completeness in almost unpredictable ways. Consequently, there is no best universal software or protocol for this task. Producing a high-quality assembly requires chaining several tools into pipelines and performing extensive comparisons between the assemblies obtained by different tool combinations to decide which one is the best. This task can be extremely challenging, as the number of tools available rises very rapidly, and thorough benchmarks cannot be updated and published at such a fast pace. In their paper, Orjuela and collaborators present CulebrONT [1], a universal pipeline that greatly contributes to overcoming these challenges and facilitates long-read genome assembly for all taxonomic groups. CulebrONT incorporates six commonly used assemblers and allows to perform assembly, circularization (if needed), polishing, and evaluation in a simple framework. One important aspect of CulebrONT is its modularity, which allows the activation or deactivation of specific tools, giving great flexibility to the user. Nevertheless, possibly the best feature of CulebrONT is the opportunity to benchmark the selected tool combinations based on the excellent report generated by the pipeline. This HTML report aggregates the output of several tools for quality evaluation of the assemblies (e.g. BUSCO [2] or QUAST [3]) generated by the different assemblers, in addition to the running time and configuration parameters. Such information is of great help to identify the best-suited pipeline, as exemplified by the authors using four datasets of different taxonomic origins. Finally, CulebrONT can handle multiple samples in parallel, which makes it a good solution for laboratories looking for multiple assemblies on a large scale. References 1. Orjuela J, Comte A, Ravel S, Charriat F, Vi T, Sabot F, Cunnac S (2022) CulebrONT: a streamlined long reads multi-assembler pipeline for prokaryotic and eukaryotic genomes. bioRxiv, 2021.07.19.452922, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.07.19.452922 2. Simão FA, Waterhouse RM, Ioannidis P, Kriventseva EV, Zdobnov EM (2015) BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics, 31, 3210–3212. https://doi.org/10.1093/bioinformatics/btv351 3. Gurevich A, Saveliev V, Vyahhi N, Tesler G (2013) QUAST: quality assessment tool for genome assemblies. Bioinformatics, 29, 1072–1075. https://doi.org/10.1093/bioinformatics/btt086 | CulebrONT: a streamlined long reads multi-assembler pipeline for prokaryotic and eukaryotic genomes | Julie Orjuela, Aurore Comte, Sébastien Ravel, Florian Charriat, Tram Vi, Francois Sabot, Sébastien Cunnac | <p style="text-align: justify;">Using long reads provides higher contiguity and better genome assemblies. However, producing such high quality sequences from raw reads requires to chain a growing set of tools, and determining the best workflow is ... | | Bioinformatics | Raúl Castanera | Valentine Murigneux | 2022-02-22 16:21:25 | |
09 Oct 2020
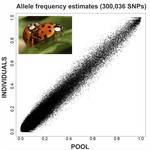
An evaluation of pool-sequencing transcriptome-based exon capture for population genomics in non-model speciesAssessing a novel sequencing-based approach for population genomics in non-model speciesRecommended by Thomas Derrien and Sebastian E. Ramos-Onsins based on reviews by Valentin Wucher and 1 anonymous reviewerDeveloping new sequencing and bioinformatic strategies for non-model species is of great interest in many applications, such as phylogenetic studies of diverse related species, but also for studies in population genomics, where a relatively large number of individuals is necessary. Different approaches have been developed and used in these last two decades, such as RAD-Seq (e.g., Miller et al. 2007), exome sequencing (e.g., Teer and Mullikin 2010) and other genome reduced representation methods that avoid the use of a good reference and well annotated genome (reviewed at Davey et al. 2011). However, population genomics studies require the analysis of numerous individuals, which makes the studies still expensive. Pooling samples was thought as an inexpensive strategy to obtain estimates of variability and other related to the frequency spectrum, thus allowing the study of variability at population level (e.g., Van Tassell et al. 2008), although the major drawback was the loss of information related to the linkage of the variants. In addition, population analysis using all these sequencing strategies require statistical and empirical validations that are not always fully performed. A number of studies aiming to obtain unbiased estimates of variability using reduced representation libraries and/or with pooled data have been performed (e.g., Futschik and Schlötterer 2010, Gautier et al. 2013, Ferretti et al. 2013, Lynch et al. 2014), as well as validation of new sequencing methods for population genetic analyses (e.g., Gautier et al. 2013, Nevado et al. 2014). Nevertheless, empirical validation using both pooled and individual experimental approaches combined with different bioinformatic methods has not been always performed. References [1] Choquet et al. (2019). Towards population genomics in non-model species with large genomes: a case study of the marine zooplankton Calanus finmarchicus. Royal Society open science, 6(2), 180608. doi: https://doi.org/10.1098/rsos.180608 | An evaluation of pool-sequencing transcriptome-based exon capture for population genomics in non-model species | Emeline Deleury, Thomas Guillemaud, Aurélie Blin & Eric Lombaert | <p>Exon capture coupled to high-throughput sequencing constitutes a cost-effective technical solution for addressing specific questions in evolutionary biology by focusing on expressed regions of the genome preferentially targeted by selection. Tr... | | Bioinformatics, Population genomics | Thomas Derrien | 2020-02-26 09:21:11 | ||
24 Jan 2024

High quality genome assembly of the brown hare (Lepus europaeus) with chromosome-level scaffoldingA high quality reference genome of the brown hareRecommended by Ed Hollox based on reviews by Merce Montoliu-Nerin and 1 anonymous reviewer based on reviews by Merce Montoliu-Nerin and 1 anonymous reviewer
The brown hare, or European hare, Lupus europaeus, is a widespread mammal whose natural range spans western Eurasia. At the northern limit of its range, it hybridises with the mountain hare (L. timidis), and humans have introduced it into other continents. It represents a particularly interesting mammal to study for its population genetics, extensive hybridisation zones, and as an invasive species. This study (Michell et al. 2024) has generated a high-quality assembly of a genome from a brown hare from Finland using long PacBio HiFi sequencing reads and Hi-C scaffolding. The contig N50 of this new genome is 43 Mb, and completeness, assessed using BUSCO, is 96.1%. The assembly comprises 23 autosomes, and an X chromosome and Y chromosome, with many chromosomes including telomeric repeats, indicating the high level of completeness of this assembly. While the genome of the mountain hare has previously been assembled, its assembly was based on a short-read shotgun assembly, with the rabbit as a reference genome. The new high-quality brown hare genome assembly allows a direct comparison with the rabbit genome assembly. For example, the assembly addresses the karyotype difference between the hare (n=24) and the rabbit (n=22). Chromosomes 12 and 17 of the hare are equivalent to chromosome 1 of the rabbit, and chromosomes 13 and 16 of the hare are equivalent to chromosome 2 of the rabbit. The new assembly also provides a hare Y-chromosome, as the previous mountain hare genome was from a female. This new genome assembly provides an important foundation for population genetics and evolutionary studies of lagomorphs. References Michell, C., Collins, J., Laine, P. K., Fekete, Z., Tapanainen, R., Wood, J. M. D., Goffart, S., Pohjoismäki, J. L. O. (2024). High quality genome assembly of the brown hare (Lepus europaeus) with chromosome-level scaffolding. bioRxiv, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.08.29.555262 | High quality genome assembly of the brown hare (*Lepus europaeus*) with chromosome-level scaffolding | Craig Michell, Joanna Collins, Pia K. Laine, Zsofia Fekete, Riikka Tapanainen, Jonathan M. D. Wood, Steffi Goffart, Jaakko L. O. Pohjoismaki | <p style="text-align: justify;">We present here a high-quality genome assembly of the brown hare (Lepus europaeus Pallas), based on a fibroblast cell line of a male specimen from Liperi, Eastern Finland. This brown hare genome represents the first... | | ERGA Pilot, Vertebrates | Ed Hollox | 2023-10-16 20:46:39 | ||
25 Nov 2022
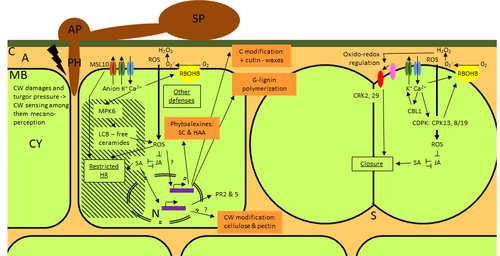
Phenotypic and transcriptomic analyses reveal major differences between apple and pear scab nonhost resistanceApples and pears: two closely related species with differences in scab nonhost resistanceRecommended by Wirulda Pootakham based on reviews by 3 anonymous reviewersNonhost resistance is a common form of disease resistance exhibited by plants against microorganisms that are pathogenic to other plant species [1]. Apples and pears are two closely related species belonging to Rosaceae family, both affected by scab disease caused by fungal pathogens in the Venturia genus. These pathogens appear to be highly host-specific. While apples are nonhosts for Venturia pyrina, pears are nonhosts for Venturia inaequalis. To date, the molecular bases of scab nonhost resistance in apple and pear have not been elucidated. This preprint by Vergne, et al (2022) [2] analyzed nonhost resistance symptoms in apple/V. pyrina and pear/V. inaequalis interactions as well as their transcriptomic responses. Interestingly, the author demonstrated that the nonhost apple/V. pyrina interaction was almost symptomless while hypersensitive reactions were observed for pear/V. inaequalis interaction. The transcriptomic analyses also revealed a number of differentially expressed genes (DEGs) that corresponded to the severity of the interactions, with very few DEGs observed during the apple/V. pyrina interaction and a much higher number of DEGs during the pear/V. inaequalis interaction. This type of reciprocal host-pathogen interaction study is valuable in gaining new insights into how plants interact with microorganisms that are potential pathogens in related species. A few processes appeared to be involved in the pear resistance against the nonhost pathogen V. inaequalis at the transcriptomic level, such as stomata closure, modification of cell wall and production of secondary metabolites as well as phenylpropanoids. Based on the transcriptomics changes during the nonhost interaction, the author compared the responses to those of host-pathogen interactions and revealed some interesting findings. They proposed a series of cascading effects in pear induced by the presence of V. inaequalis, which I believe helps shed some light on the basic mechanism for nonhost resistance. I am recommending this study because it provides valuable information that will strengthen our understanding of nonhost resistance in the Rosaceae family and other plant species. The knowledge gained here may be applied to genetically engineer plants for a broader resistance against a number of pathogens in the future. References 1. Senthil-Kumar M, Mysore KS (2013) Nonhost Resistance Against Bacterial Pathogens: Retrospectives and Prospects. Annual Review of Phytopathology, 51, 407–427. https://doi.org/10.1146/annurev-phyto-082712-102319 2. Vergne E, Chevreau E, Ravon E, Gaillard S, Pelletier S, Bahut M, Perchepied L (2022) Phenotypic and transcriptomic analyses reveal major differences between apple and pear scab nonhost resistance. bioRxiv, 2021.06.01.446506, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.06.01.446506 | Phenotypic and transcriptomic analyses reveal major differences between apple and pear scab nonhost resistance | E. Vergne, E. Chevreau, E. Ravon, S. Gaillard, S. Pelletier, M. Bahut, L. Perchepied | <p style="text-align: justify;"><strong>Background. </strong>Nonhost resistance is the outcome of most plant/pathogen interactions, but it has rarely been described in Rosaceous fruit species. Apple (<em>Malus x domestica</em> Borkh.) have a nonho... | | Functional genomics, Plants | Wirulda Pootakham | Jessica Soyer, Anonymous | 2022-05-13 15:06:08 |




