
Latest recommendations

| Id▲ | Title | Authors | Abstract | Picture | Thematic fields | Recommender | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
22 May 2023

Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approachScoring symptoms of a plant viral diseaseRecommended by Olivier Panaud based on reviews by Grégoire Aubert and Valérie GeffroyThe paper from Silva et al. (2023) provides new insights into the genetic bases of natural resistance of rice to the Rice Hoja Blanca (RHB) disease, one of its most serious diseases in tropical countries of the American continent and the Caribbean. This disease is caused by the Rice Hoja Blanca Virus, or RHBV, the vector of which is the planthopper insect Tagosodes orizicolus Müir. It is responsible for serious damage to the rice crop (Morales and Jennings 2010). The authors take a Quantitative Trait Loci (QTL) detection approach to find genomic regions statistically associated with the resistant phenotype. To this aim, they use four resistant x susceptible crosses (the susceptible parent being the same in all four crosses) to maximize the chances to find new QTLs. The F2 populations derived from the crosses are genotyped using Single Nucleotide Polymorphisms (SNPs) extracted from whole-genome sequencing (WGS) data of the resistant parents, and the F3 families derived from the F2 individuals are scored for disease symptoms. For this, they use a computer-aided image analysis protocol that they designed so they can estimate the severity of the damages in the plant. They find several new QTLs, some being apparently more associated with disease severity, others with disease incidence. They also find that a previously identified QTL of Oryza sativa ssp. japonica origin is also present in the indica cluster (Romero et al. 2014). Finally, they discuss the candidate genes that could underlie the QTLs and provide a simple model for resistance. It has to be noted that scoring symptoms of a viral disease such as RHB is very challenging. It requires maintaining populations of viruliferous insect vectors, mastering times and conditions for infestation by nymphs, and precise symptom scoring. It also requires the preparation of segregating populations, their genotyping with enough genetic markers, and mastering QTL detection methods. All these aspects are present in this work. In particular, the phenotyping of symptom severity implemented using computer-aided image processing represents an impressive, enormous amount of work. From the genomics side, the fine-scale genotyping is based on the WGS of the parental lines (resistant and susceptible), followed by the application of suitable bioinformatic tools for SNP extraction and primers prediction that can be used on their Fluidigm platform. It also required implementing data correction algorithms to achieve precise genetic maps in the four crosses. The QTL detection itself required careful statistical pre-processing of phenotypic data. The authors then used a combination of several QTL detection methods, including an original meta-QTL method they developed in the software MapDisto. The authors then perform a very complete and convincing analysis of candidate genes, which includes genes already identified for a similar disease (RSV) on chromosome 11 of rice. What remains to elucidate is whether the candidate genes are actually involved or not in the disease resistance process. The team has already started implementing gene knockout strategies to study some of them in more detail. It will be interesting to see whether those genes act against the virus itself, or against the insect vector. Overall the work is of high quality and represents an important advance in the knowledge of disease resistance. In addition, it has many implications for crop breeding, allowing the setup of large-scale, marker-assisted strategies, for new resistant elite varieties of rice. References Morales F and Jennings P (2010) Rice hoja blanca: a complex plant-virus-vector pathosystem. CAB Reviews. https://doi.org/10.1079/PAVSNNR20105043 Romero LE, Lozano I, Garavito A, et al (2014) Major QTLs control resistance to Rice hoja blanca virus and its vector Tagosodes orizicolus. G3 | Genes, Genomes, Genetics 4:133–142. https://doi.org/10.1534/g3.113.009373 Silva A, Montoya ME, Quintero C, Cuasquer J, Tohme J, Graterol E, Cruz M, Lorieux M (2023) Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approach. bioRxiv, 2022.11.07.515427, ver. 2 peer-reviewed and recommended by Peer Community in Genomics https://doi.org/10.1101/2022.11.07.515427 | Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approach | Alexander Silva, Maria Elker Montoya, Constanza Quintero, Juan Cuasquer, Joe Tohme, Eduardo Graterol, Maribel Cruz, Mathias Lorieux | <p style="text-align: justify;">Rice hoja blanca (RHB) is one of the most serious diseases in rice growing areas in tropical Americas. Its causal agent is Rice hoja blanca virus (RHBV), transmitted by the planthopper <em>Tagosodes orizicolus </em>... | | Functional genomics, Plants | Olivier Panaud | 2022-11-09 09:13:30 | ||
10 Jul 2023
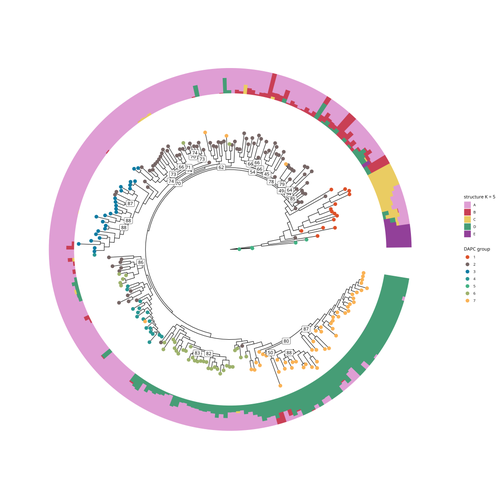
SNP discovery by exome capture and resequencing in a pea genetic resource collectionThe value of a large Pisum SNP datasetRecommended by Wanapinun Nawae based on reviews by Rui Borges and 1 anonymous reviewerOne important goal of modern genetics is to establish functional associations between genotype and phenotype. Single nucleotide polymorphisms (SNPs) are numerous and widely distributed in the genome and can be obtained from nucleic acid sequencing (1). SNPs allow for the investigation of genetic diversity, which is critical for increasing crop resilience to the challenges posed by global climate change. The associations between SNPs and phenotypes can be captured in genome-wide association studies. SNPs can also be used in combination with machine learning, which is becoming more popular for predicting complex phenotypic traits like yield and biotic and abiotic stress tolerance from genotypic data (2). The availability of many SNP datasets is important in machine learning predictions because this approach requires big data to build a comprehensive model of the association between genotype and phenotype. Aubert and colleagues have studied, as part of the PeaMUST project, the genetic diversity of 240 Pisum accessions (3). They sequenced exome-enriched genomic libraries, a technique that enables the identification of high-density, high-quality SNPs at a low cost (4). This technique involves capturing and sequencing only the exonic regions of the genome, which are the protein-coding regions. A total of 2,285,342 SNPs were obtained in this study. The analysis of these SNPs with the annotations of the genome sequence of one of the studied pea accessions (5) identified a number of SNPs that could have an impact on gene activity. Additional analyses revealed 647,220 SNPs that were unique to individual pea accessions, which might contribute to the fitness and diversity of accessions in different habitats. Phylogenetic and clustering analyses demonstrated that the SNPs could distinguish Pisum germplasms based on their agronomic and evolutionary histories. These results point out the power of selected SNPs as markers for identifying Pisum individuals. Overall, this study found high-quality SNPs that are meaningful in a biological context. This dataset was derived from a large set of germplasm and is thus particularly useful for studying genotype-phenotype associations, as well as the diversity within Pisum species. These SNPs could also be used in breeding programs to develop new pea varieties that are resilient to abiotic and biotic stressors. References
https://doi.org/10.1139/gen-2021-005
https://doi.org/10.1186/s12870-022-03559-z
https://doi.org/10.1101/2022.08.03.502586
https://doi.org/10.1534/g3.115.018564
| SNP discovery by exome capture and resequencing in a pea genetic resource collection | G. Aubert, J. Kreplak, M. Leveugle, H. Duborjal, A. Klein, K. Boucherot, E. Vieille, M. Chabert-Martinello, C. Cruaud, V. Bourion, I. Lejeune-Hénaut, M.L. Pilet-Nayel, Y. Bouchenak-Khelladi, N. Francillonne, N. Tayeh, J.P. Pichon, N. Rivière, J. B... | <p style="text-align: justify;"><strong>Background & Summary</strong></p> <p style="text-align: justify;">In addition to being the model plant used by Mendel to establish genetic laws, pea (<em>Pisum sativum</em> L., 2n=14) is a major pulse c... | | Plants, Population genomics | Wanapinun Nawae | 2022-11-29 09:29:06 | ||
11 Sep 2023
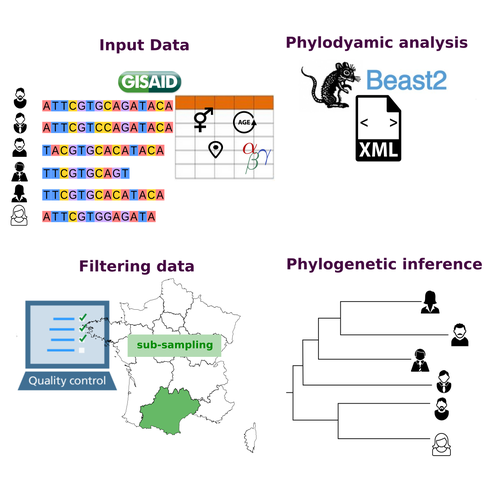
COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequencesA pipeline to select SARS-CoV-2 sequences for reliable phylodynamic analysesRecommended by Emmanuelle Lerat based on reviews by Gabriel Wallau and Bastien BoussauPhylodynamic approaches enable viral genetic variation to be tracked over time, providing insight into pathogen phylogenetic relationships and epidemiological dynamics. These are important methods for monitoring viral spread, and identifying important parameters such as transmission rate, geographic origin and duration of infection [1]. This knowledge makes it possible to adjust public health measures in real-time and was important in the case of the COVID-19 pandemic [2]. However, these approaches can be complicated to use when combining a very large number of sequences. This was particularly true during the COVID-19 pandemic, when sequencing data representing millions of entire viral genomes was generated, with associated metadata enabling their precise identification. Danesh et al. [3] present a bioinformatics pipeline, CovFlow, for selecting relevant sequences according to user-defined criteria to produce files that can be used directly for phylodynamic analyses. The selection of sequences first involves a quality filter on the size of the sequences and the absence of unresolved bases before being able to make choices based on the associated metadata. Once the sequences are selected, they are aligned and a time-scaled phylogenetic tree is inferred. An output file in a format directly usable by BEAST 2 [4] is finally generated. To illustrate the use of the pipeline, Danesh et al. [3] present an analysis of the Delta variant in two regions of France. They observed a delay in the start of the epidemic depending on the region. In addition, they identified genetic variation linked to the start of the school year and the extension of vaccination, as well as the arrival of a new variant. This tool will be of major interest to researchers analysing SARS-CoV-2 sequencing data, and a number of future developments are planned by the authors. References [1] Baele G, Dellicour S, Suchard MA, Lemey P, Vrancken B. 2018. Recent advances in computational phylodynamics. Curr Opin Virol. 31:24-32. https://doi.org/10.1016/j.coviro.2018.08.009 [2] Attwood SW, Hill SC, Aanensen DM, Connor TR, Pybus OG. 2022. Phylogenetic and phylodynamic approaches to understanding and combating the early SARS-CoV-2 pandemic. Nat Rev Genet. 23:547-562. https://doi.org/10.1038/s41576-022-00483-8 [3] Danesh G, Boennec C, Verdurme L, Roussel M, Trombert-Paolantoni S, Visseaux B, Haim-Boukobza S, Alizon S. 2023. COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences. bioRxiv, ver. 7 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.06.17.496544 [4] Bouckaert R, Heled J, Kühnert D, Vaughan T, Wu C-H et al. 2014. BEAST 2: a software platform for Bayesian evolutionary analysis. PLoS Comput Biol 10: e1003537. https://doi.org/10.1371/journal.pcbi.1003537 | COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences | Gonché Danesh, Corentin Boennec, Laura Verdurme, Mathilde Roussel, Sabine Trombert-Paolantoni, Benoit Visseaux, Stephanie Haim-Boukobza, Samuel Alizon | <p style="text-align: justify;">Phylodynamic analyses generate important and timely data to optimise public health response to SARS-CoV-2 outbreaks and epidemics. However, their implementation is hampered by the massive amount of sequence data and... | | Bioinformatics, Evolutionary genomics | Emmanuelle Lerat | 2022-12-12 09:04:01 | ||
07 Aug 2023
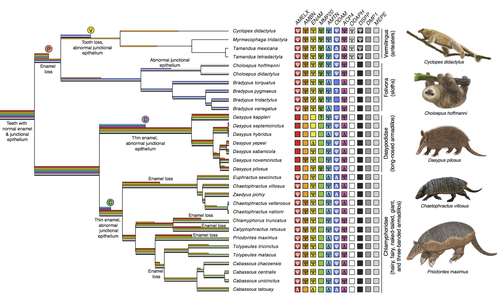
Genomic data suggest parallel dental vestigialization within the xenarthran radiationWhat does dental gene decay tell us about the regressive evolution of teeth in South American mammals?Recommended by Didier Casane based on reviews by Juan C. Opazo, Régis Debruyne and Nicolas PolletA group of mammals, Xenathra, evolved and diversified in South America during its long period of isolation in the early to mid Cenozoic era. More recently, as a result of the Great Faunal Interchange between South America and North America, many xenarthran species went extinct. The thirty-one extant species belong to three groups: armadillos, sloths and anteaters. They share dental degeneration. However, the level of degeneration is variable. Anteaters entirely lack teeth, sloths have intermediately regressed teeth and most armadillos have a toothless premaxilla, as well as peg-like, single-rooted teeth that lack enamel in adult animals (Vizcaíno 2009). This diversity raises a number of questions about the evolution of dentition in these mammals. Unfortunately, the fossil record is too poor to provide refined information on the different stages of regressive evolution in these clades. In such cases, the identification of loss-of-function mutations and/or relaxed selection in genes related to a character regression can be very informative (Emerling and Springer 2014; Meredith et al. 2014; Policarpo et al. 2021). Indeed, shared and unique pseudogenes/relaxed selection can tell us to what extent regression has occurred in common ancestors and whether some changes are lineage-specific. In addition, the distribution of pseudogenes/relaxed selection on the branches of a phylogenetic tree is related to the evolutionary processes involved. A much higher density of pseudogenes in the most internal branches indicates that degeneration took place early and over a short period of time, consistent with selection against the presence of the morphological character with which they are associated, while pseudogenes distributed evenly in many internal and external branches suggest a more gradual process over many millions of years, in line with relaxed selection and fixation of loss-of-function mutations by genetic drift. In this paper (Emerling et al. 2023), the authors examined the dynamics of decay of 11 dental genes that may parallel teeth regression. The analyses of the data reported in this paper clearly point to xenarthran teeth having repeatedly regressed in parallel in the three clades. In fact, no loss-of-function mutation is shared by all species examined. However, more genes should be studied to confirm the hypothesis that the common ancestor of extant xenarthrans had normal dentition. There are distinct patterns of gene loss in different lineages that are associated with the variation in dentition observed across the clades. These patterns of gene loss suggest that regressive evolution took place both gradually and in relatively rapid, discrete phases during the diversification of xenarthrans. This study underscores the utility of using pseudogenes to reconstruct evolutionary history of morphological characters when fossils are sparse. References Emerling CA, Gibb GC, Tilak M-K, Hughes JJ, Kuch M, Duggan AT, Poinar HN, Nachman MW, Delsuc F. 2023. Genomic data suggest parallel dental vestigialization within the xenarthran radiation. bioRxiv, 2022.12.09.519446, ver 2, peer-reviewed and recommended by PCI Genomics. https://doi.org/10.1101/2022.12.09.519446 Emerling CA, Springer MS. 2014. Eyes underground: Regression of visual protein networks in subterranean mammals. Molecular Phylogenetics and Evolution 78: 260-270. https://doi.org/10.1016/j.ympev.2014.05.016 Meredith RW, Zhang G, Gilbert MTP, Jarvis ED, Springer MS. 2014. Evidence for a single loss of mineralized teeth in the common avian ancestor. Science 346: 1254390. https://doi.org/10.1126/science.1254390 Policarpo M, Fumey J, Lafargeas P, Naquin D, Thermes C, Naville M, Dechaud C, Volff J-N, Cabau C, Klopp C, et al. 2021. Contrasting gene decay in subterranean vertebrates: insights from cavefishes and fossorial mammals. Molecular Biology and Evolution 38: 589-605. https://doi.org/10.1093/molbev/msaa249 Vizcaíno SF. 2009. The teeth of the “toothless”: novelties and key innovations in the evolution of xenarthrans (Mammalia, Xenarthra). Paleobiology 35: 343-366. https://doi.org/10.1666/0094-8373-35.3.343 | Genomic data suggest parallel dental vestigialization within the xenarthran radiation | Christopher A Emerling, Gillian C Gibb, Marie-Ka Tilak, Jonathan J Hughes, Melanie Kuch, Ana T Duggan, Hendrik N Poinar, Michael W Nachman, Frederic Delsuc | <p style="text-align: justify;">The recent influx of genomic data has provided greater insights into the molecular basis for regressive evolution, or vestigialization, through gene loss and pseudogenization. As such, the analysis of gene degradati... | | Evolutionary genomics, Vertebrates | Didier Casane | 2022-12-12 16:01:57 | ||
02 Jun 2023
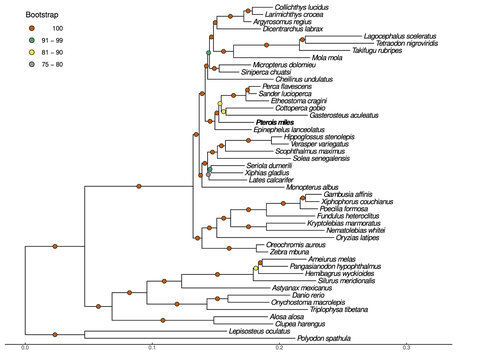
Near-chromosome level genome assembly of devil firefish, Pterois milesThe genome of a dangerous invader (fish) beautyRecommended by Iker Irisarri based on reviews by Maria Recuerda and 1 anonymous reviewer based on reviews by Maria Recuerda and 1 anonymous reviewer
High-quality genomes are currently being generated at an unprecedented speed powered by long-read sequencing technologies. However, sequencing effort is concentrated unequally across the tree of life and several key evolutionary and ecological groups remain largely unexplored. So is the case for fish species of the family Scorpaenidae (Perciformes). Kitsoulis et al. present the genome of the devil firefish, Pterois miles (1). Following current best practices, the assembly relies largely on Oxford Nanopore long reads, aided by Illumina short reads for polishing to increase the per-base accuracy. PacBio’s IsoSeq was used to sequence RNA from a variety of tissues as direct evidence for annotating genes. The reconstructed genome is 902 Mb in size and has high contiguity (N50=14.5 Mb; 660 scaffolds, 90% of the genome covered by the 83 longest scaffolds) and completeness (98% BUSCO completeness). The new genome is used to assess the phylogenetic position of P. miles, explore gene synteny against zebrafish, look at orthogroup expansion and contraction patterns in Perciformes, as well as to investigate the evolution of toxins in scorpaenid fish (2). In addition to its value for better understanding the evolution of scorpaenid and teleost fishes, this new genome is also an important resource for monitoring its invasiveness through the Mediterranean Sea (3) and the Atlantic Ocean, in the latter case forming the invasive lionfish complex with P. volitans (4). REFERENCES 1. Kitsoulis CV, Papadogiannis V, Kristoffersen JB, Kaitetzidou E, Sterioti E, Tsigenopoulos CS, Manousaki T. (2023) Near-chromosome level genome assembly of devil firefish, Pterois miles. BioRxiv, ver. 6 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.01.10.523469 2. Kiriake A, Shiomi K. (2011) Some properties and cDNA cloning of proteinaceous toxins from two species of lionfish (Pterois antennata and Pterois volitans). Toxicon, 58(6-7):494–501. https://doi.org/10.1016/j.toxicon.2011.08.010 3. Katsanevakis S, et al. (2020) Un- published Mediterranean records of marine alien and cryptogenic species. BioInvasions Records, 9:165–182. https://doi.org/10.3391/bir.2020.9.2.01 4. Lyons TJ, Tuckett QM, Hill JE. (2019) Data quality and quantity for invasive species: A case study of the lionfishes. Fish and Fisheries, 20:748–759. https://doi.org/10.1111/faf.12374 | Near-chromosome level genome assembly of devil firefish, *Pterois miles* | Christos V. Kitsoulis, Vasileios Papadogiannis, Jon B. Kristoffersen, Elisavet Kaitetzidou, Aspasia Sterioti, Costas S. Tsigenopoulos, Tereza Manousaki | <p style="text-align: justify;">Devil firefish (<em>Pterois miles</em>), a member of Scorpaenidae family, is one of the most successful marine non-native species, dominating around the world, that was rapidly spread into the Mediterranean Sea, thr... | | Evolutionary genomics | Iker Irisarri | 2023-01-17 12:37:20 | ||
14 Sep 2023
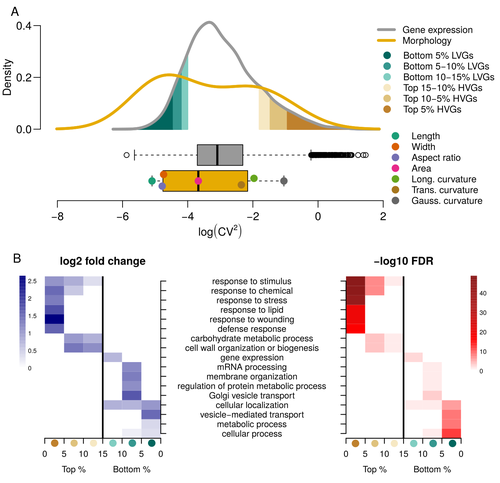
Expression of cell-wall related genes is highly variable and correlates with sepal morphologyThe same but different: How small scale hidden variations can have large effectsRecommended by Francois Sabot based on reviews by Sandra Corjito and 1 anonymous reviewer
For ages, we considered only single genes, or just a few, in order to understand the relationship between phenotype and genotype in response to environmental challenges. Recently, the use of meaningful groups of genes, e.g. gene regulatory networks, or modules of co-expression, allowed scientists to have a larger view of gene regulation. However, all these findings were based on contrasted genotypes, e.g. between wild-types and mutants, as the implicit assumption often made is that there is little transcriptomic variability within the same genotype context. Hartasànchez and collaborators (2023) decided to challenge both views: they used a single genotype instead of two, the famous A. thaliana Col0, and numerous plants, and considered whole gene networks related to sepal morphology and its variations. They used a clever approach, combining high-level phenotyping and gene expression to better understand phenomena and regulations underlying sepal morphologies. Using multiple controls, they showed that basic variations in the expression of genes related to the cell wall regulation, as well as the ones involved in chloroplast metabolism, influenced the global transcriptomic pattern observed in sepal while being in near-identical genetic background and controlling for all other experimental conditions. The paper of Hartasànchez et al. is thus a tremendous call for humility in biology, as we saw in their work that we just understand the gross machinery. However, the Devil is in the details: understanding those very small variations that may have a large influence on phenotypes, and thus on local adaptation to environmental challenges, is of great importance in these times of climatic changes. References Hartasánchez DA, Kiss A, Battu V, Soraru C, Delgado-Vaquera A, Massinon F, Brasó-Vives M, Mollier C, Martin-Magniette M-L, Boudaoud A, Monéger F. 2023. Expression of cell-wall related genes is highly variable and correlates with sepal morphology. bioRxiv, ver. 4, peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.26.489498 | Expression of cell-wall related genes is highly variable and correlates with sepal morphology | Diego A. Hartasánchez, Annamaria Kiss, Virginie Battu, Charline Soraru, Abigail Delgado-Vaquera, Florian Massinon, Marina Brasó-Vives, Corentin Mollier, Marie-Laure Martin-Magniette, Arezki Boudaoud, Françoise Monéger | <p style="text-align: justify;">Control of organ morphology is a fundamental feature of living organisms. There is, however, observable variation in organ size and shape within a given genotype. Taking the sepal of Arabidopsis as a model, we inves... | | Bioinformatics, Epigenomics, Plants | Francois Sabot | 2023-03-14 19:10:15 | ||
09 Aug 2023
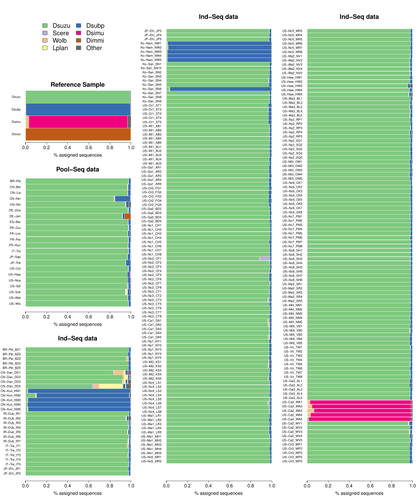
Efficient k-mer based curation of raw sequence data: application in Drosophila suzukiiDecontaminating reads, not contigsRecommended by Nicolas Galtier based on reviews by Marie Cariou and Denis BaurainContamination, the presence of foreign DNA sequences in a sample of interest, is currently a major problem in genomics. Because contamination is often unavoidable at the experimental stage, it is increasingly recognized that the processing of high-throughput sequencing data must include a decontamination step. This is usually performed after the many sequence reads have been assembled into a relatively small number of contigs. Dubious contigs are then discarded based on their composition (e.g. GC-content) or because they are highly similar to a known piece of DNA from a foreign species. Here [1], Mathieu Gautier explores a novel strategy consisting in decontaminating reads, not contigs. Why is this promising? Assembly programs and algorithms are complex, and it is not easy to predict, or monitor, how they handle contaminant reads. Ideally, contaminant reads will be assembled into obvious contaminant contigs. However, there might be more complex situations, such as chimeric contigs with alternating genuine and contaminant segments. Decontaminating at the read level, if possible, should eliminate such unfavorable situations where sequence information from contaminant and target samples are intimately intertwined by an assembler. To achieve this aim, Gautier proposes to use methods initially designed for the analysis of metagenomic data. This is pertinent since the decontamination process involves considering a sample as a mixture of different sources of DNA. The programs used here, CLARK and CLARK-L, are based on so-called k-mer analysis, meaning that the similarity between a read to annotate and a reference sequence is measured by how many sub-sequences (of length 31 base pairs for CLARK and 27 base pairs for CLARK-L) they share. This is notoriously more efficient than traditional sequence alignment algorithms when it comes to comparing a very large number of (most often unrelated) sequences. This is, therefore, a reference-based approach, in which the reads from a sample are assigned to previously sequenced genomes based on k-mer content. This original approach is here specifically applied to the case of Drosophila suzukii, an invasive pest damaging fruit production in Europe and America. Fortunately, Drosophila is a genus of insects with abundant genomic resources, including high-quality reference genomes in dozens of species. Having calibrated and validated his pipeline using data sets of known origins, Gautier quantifies in each of 258 presumed D. suzukii samples the proportion of reads that likely belong to other species of fruit flies, or to fruit fly-associated microbes. This proportion is close to one in 16 samples, which clearly correspond to mis-labelled individuals. It is non-negligible in another ~10 samples, which really correspond to D. suzukii individuals. Most of these reads of unexpected origin are contaminants and should be filtered out. Interestingly, one D. suzukii sample contains a substantial proportion of reads from the closely related D. subpulchera, which might instead reflect a recent episode of gene flow between these two species. The approach, therefore, not only serves as a crucial technical step, but also has the potential to reveal biological processes. Gautier's thorough, well-documented work will clearly benefit the ongoing and future research on D. suzuki, and Drosophila genomics in general. The author and reviewers rightfully note that, like any reference-based approach, this method is heavily dependent on the availability and quality of reference genomes - Drosophila being a favorable case. Building the reference database is a key step, and the interpretation of the output can only be made in the light of its content and gaps, as illustrated by Gautier's careful and detailed discussion of his numerous results. This pioneering study is a striking demonstration of the potential of metagenomic methods for the decontamination of high-throughput sequence data at the read level. The pipeline requires remarkably few computing resources, ensuring low carbon emission. I am looking forward to seeing it applied to a wide range of taxa and samples.
Reference [1] Gautier Mathieu. Efficient k-mer based curation of raw sequence data: application in Drosophila suzukii. bioRxiv, 2023.04.18.537389, ver. 2, peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.04.18.537389 | Efficient k-mer based curation of raw sequence data: application in *Drosophila suzukii* | Gautier Mathieu | <p>Several studies have highlighted the presence of contaminated entries in public sequence repositories, calling for special attention to the associated metadata. Here, we propose and evaluate a fast and efficient kmer-based approach to assess th... | | Bioinformatics, Population genomics | Nicolas Galtier | 2023-04-20 22:05:13 | ||
15 Mar 2024
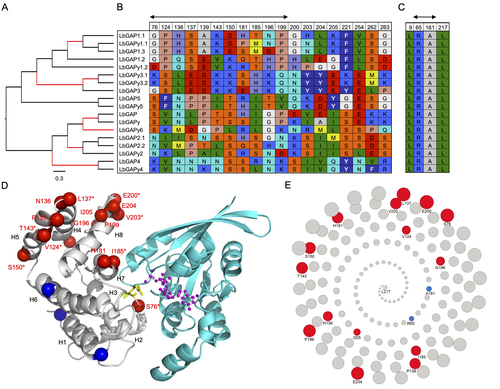
Convergent origin and accelerated evolution of vesicle-associated RhoGAP proteins in two unrelated parasitoid waspsUsing transcriptomics and proteomics to understand the expansion of a secreted poisonous armoury in parasitoid wasps genomesRecommended by Ignacio Bravo based on reviews by Inacio Azevedo and 2 anonymous reviewers
Parasitoid wasps lay their eggs inside another arthropod, whose body is physically consumed by the parasitoid larvae. Phylogenetic inference suggests that Parasitoida are monophyletic, and that this clade underwent a strong radiation shortly after branching off from the Apocrita stem, some 236 million years ago (Peters et al. 2017). The increase in taxonomic diversity during evolutionary radiations is usually concurrent with an increase in genetic/genomic diversity, and is often associated with an increase in phenotypic diversity. Gene (or genome) duplication provides the evolutionary potential for such increase of genomic diversity by neo/subfunctionalisation of one of the gene paralogs, and is often proposed to be related to evolutionary radiations (Ohno 1970; Francino 2005).
References
| Convergent origin and accelerated evolution of vesicle-associated RhoGAP proteins in two unrelated parasitoid wasps | Dominique Colinet, Fanny Cavigliasso, Matthieu Leobold, Appoline Pichon, Serge Urbach, Dominique Cazes, Marine Poullet, Maya Belghazi, Anne-Nathalie Volkoff, Jean-Michel Drezen, Jean-Luc Gatti, and Marylène Poirié | <p>Animal venoms and other protein-based secretions that perform a variety of functions, from predation to defense, are highly complex cocktails of bioactive compounds. Gene duplication, accompanied by modification of the expression and/or functio... | | Evolutionary genomics | Ignacio Bravo | 2023-06-12 11:08:31 | ||
07 Sep 2023
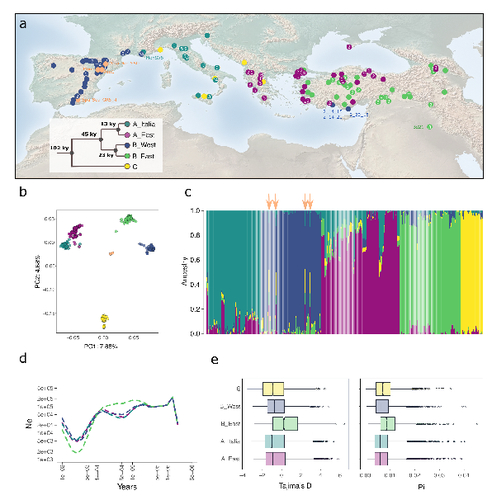
The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological nichesNatural variation and adaptation in Brachypodium distachyonRecommended by Josep Casacuberta based on reviews by Thibault Leroy and 1 anonymous reviewerIdentifying the genetic factors that allow plant adaptation is a major scientific question that is particularly relevant in the face of the climate change that we are already experiencing. To address this, it is essential to have genetic information on a high number of accessions (i.e., plants registered with unique accession numbers) growing under contrasting environmental conditions. There is already an important number of studies addressing these issues in the plant Arabidopsis thaliana, but there is a need to expand these analyses to species that play key roles in wild ecosystems and are close to very relevant crops, as is the case of grasses. The work of Minadakis, Roulin and co-workers (1) presents a Brachypodium distachyon panel of 332 fully sequences accessions that covers the whole species distribution across a wide range of bioclimatic conditions, which will be an invaluable tool to fill this gap. In addition, the authors use this data to start analyzing the population structure and demographic history of this plant, suggesting that the species experienced a shift of its distribution following the Last Glacial Maximum, which may have forced the species into new habitats. The authors also present a modeling of the niches occupied by B. distachyon together with an analysis of the genetic clades found in each of them, and start analyzing the different adaptive loci that may have allowed the species’ expansion into different bioclimatic areas. In addition to the importance of the resources made available by the authors for the scientific community, the analyses presented are well done and carefully discussed, and they highlight the potential of these new resources to investigate the genetic bases of plant adaptation. References 1. Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin. The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological niches. bioRxiv, 2023.06.01.543285, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.01.543285 | The demographic history of the wild crop relative *Brachypodium distachyon* is shaped by distinct past and present ecological niches | Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin | <p style="text-align: justify;">Closely related to economically important crops, the grass <em>Brachypodium distachyon</em> has been originally established as a pivotal species for grass genomics but more recently flourished as a model for develop... | | Evolutionary genomics, Functional genomics, Plants, Population genomics | Josep Casacuberta | 2023-06-14 15:28:30 | ||
15 Jan 2024
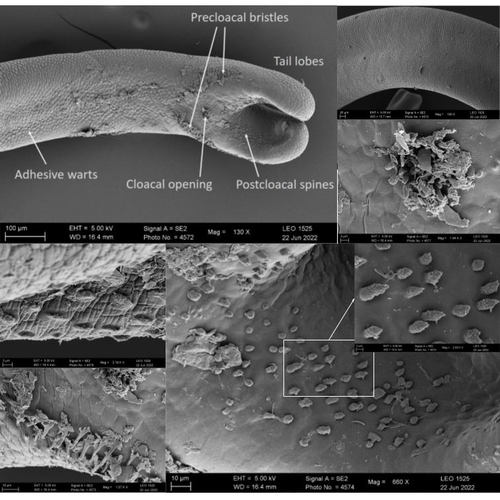
The genome sequence of the Montseny horsehair worm, Gordionus montsenyensis sp. nov., a key resource to investigate Ecdysozoa evolutionEmbarking on a novel journey in Metazoa evolution through the pioneering sequencing of a key underrepresented lineageRecommended by Juan C. Opazo based on reviews by Gonzalo Riadi and 2 anonymous reviewers
Whole genome sequences are revolutionizing our understanding across various biological fields. They not only shed light on the evolution of genetic material but also uncover the genetic basis of phenotypic diversity. The sequencing of underrepresented lineages, such as the one presented in this study, is of critical importance. It is crucial in filling significant gaps in our understanding of Metazoa evolution. Despite the wealth of genome sequences in public databases, it is crucial to acknowledge that some lineages across the Tree of Life are underrepresented or absent. This research represents a significant step towards addressing this imbalance, contributing to the collective knowledge of the global scientific community. In this genome note, as part of the European Reference Genome Atlas pilot effort to generate reference genomes for European biodiversity (Mc Cartney et al. 2023), Klara Eleftheriadi and colleagues (Eleftheriadi et al. 2023) make a significant effort to add a genome sequence of an unrepresented group in the animal Tree of Life. More specifically, they present a taxonomic description and chromosome-level genome assembly of a newly described species of horsehair worm (Gordionus montsenyensis). Their sequence methodology gave rise to an assembly of 396 scaffolds totaling 288 Mb, with an N50 value of 64.4 Mb, where 97% of this assembly is grouped into five pseudochromosomes. The nuclear genome annotation predicted 10,320 protein-coding genes, and they also assembled the circular mitochondrial genome into a 15-kilobase sequence. The selection of a species representing the phylum Nematomorpha, a group of parasitic organisms belonging to the Ecdysozoa lineage, is good, since today, there is only one publicly available genome for this animal phylum (Cunha et al. 2023). Interestingly, this article shows, among other things, that the species analyzed has lost ∼30% of the universal Metazoan genes. Efforts, like the one performed by Eleftheriadi and colleagues, are necessary to gain more insights, for example, on the evolution of this massive gene lost in this group of animals.
Cunha, T. J., de Medeiros, B. A. S, Lord, A., Sørensen, M. V., and Giribet, G. (2023). Rampant Loss of Universal Metazoan Genes Revealed by a Chromosome-Level Genome Assembly of the Parasitic Nematomorpha. Current Biology, 33 (16): 3514–21.e4. https://doi.org/10.1016/j.cub.2023.07.003 Eleftheriadi, K., Guiglielmoni, N., Salces-Ortiz, J., Vargas-Chavez, C., Martínez-Redondo, G. I., Gut, M., Flot, J.-F., Schmidt-Rhaesa, A., and Fernández, R. (2023). The Genome Sequence of the Montseny Horsehair worm, Gordionus montsenyensis sp. Nov., a Key Resource to Investigate Ecdysozoa Evolution. bioRxiv, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.26.546503 Mc Cartney, A. M., Formenti, G., Mouton, A., De Panis, D., Marins, L. S., Leitão, H. G., Diedericks, G., et al. (2023). The European Reference Genome Atlas: Piloting a Decentralised Approach to Equitable Biodiversity Genomics. bioRxiv. https://doi.org/10.1101/2023.09.25.559365 | The genome sequence of the Montseny horsehair worm, *Gordionus montsenyensis* sp. nov., a key resource to investigate Ecdysozoa evolution | Eleftheriadi Klara, Guiglielmoni Nadège, Salces-Ortiz Judit, Vargas-Chávez Carlos, Martínez-Redondo Gemma I, Gut Marta, Flot Jean François, Schmidt-Rhaesa Andreas, Fernández Rosa | <p>Nematomorpha, also known as Gordiacea or Gordian worms, are a phylum of parasitic organisms that belong to the Ecdysozoa, a clade of invertebrate animals characterized by molting. They are one of the less scientifically studied animal phyla, an... | | ERGA Pilot | Juan C. Opazo | 2023-06-29 10:31:36 |




