
Latest recommendations

| Id | Title | Authors | Abstract | Picture | Thematic fields | Recommender | Reviewers | Submission date▼ | |
|---|---|---|---|---|---|---|---|---|---|
11 Sep 2023
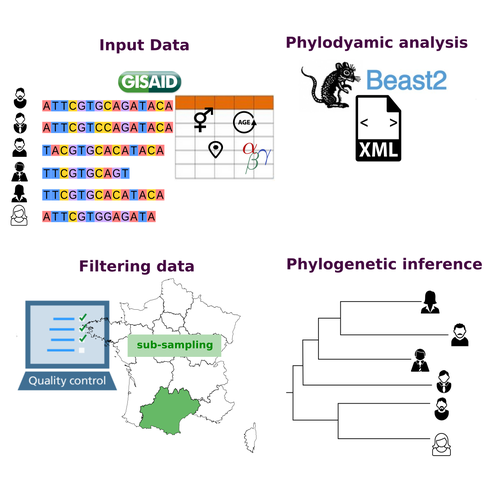
COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequencesA pipeline to select SARS-CoV-2 sequences for reliable phylodynamic analysesRecommended by Emmanuelle Lerat based on reviews by Gabriel Wallau and Bastien BoussauPhylodynamic approaches enable viral genetic variation to be tracked over time, providing insight into pathogen phylogenetic relationships and epidemiological dynamics. These are important methods for monitoring viral spread, and identifying important parameters such as transmission rate, geographic origin and duration of infection [1]. This knowledge makes it possible to adjust public health measures in real-time and was important in the case of the COVID-19 pandemic [2]. However, these approaches can be complicated to use when combining a very large number of sequences. This was particularly true during the COVID-19 pandemic, when sequencing data representing millions of entire viral genomes was generated, with associated metadata enabling their precise identification. Danesh et al. [3] present a bioinformatics pipeline, CovFlow, for selecting relevant sequences according to user-defined criteria to produce files that can be used directly for phylodynamic analyses. The selection of sequences first involves a quality filter on the size of the sequences and the absence of unresolved bases before being able to make choices based on the associated metadata. Once the sequences are selected, they are aligned and a time-scaled phylogenetic tree is inferred. An output file in a format directly usable by BEAST 2 [4] is finally generated. To illustrate the use of the pipeline, Danesh et al. [3] present an analysis of the Delta variant in two regions of France. They observed a delay in the start of the epidemic depending on the region. In addition, they identified genetic variation linked to the start of the school year and the extension of vaccination, as well as the arrival of a new variant. This tool will be of major interest to researchers analysing SARS-CoV-2 sequencing data, and a number of future developments are planned by the authors. References [1] Baele G, Dellicour S, Suchard MA, Lemey P, Vrancken B. 2018. Recent advances in computational phylodynamics. Curr Opin Virol. 31:24-32. https://doi.org/10.1016/j.coviro.2018.08.009 [2] Attwood SW, Hill SC, Aanensen DM, Connor TR, Pybus OG. 2022. Phylogenetic and phylodynamic approaches to understanding and combating the early SARS-CoV-2 pandemic. Nat Rev Genet. 23:547-562. https://doi.org/10.1038/s41576-022-00483-8 [3] Danesh G, Boennec C, Verdurme L, Roussel M, Trombert-Paolantoni S, Visseaux B, Haim-Boukobza S, Alizon S. 2023. COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences. bioRxiv, ver. 7 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.06.17.496544 [4] Bouckaert R, Heled J, Kühnert D, Vaughan T, Wu C-H et al. 2014. BEAST 2: a software platform for Bayesian evolutionary analysis. PLoS Comput Biol 10: e1003537. https://doi.org/10.1371/journal.pcbi.1003537 | COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences | Gonché Danesh, Corentin Boennec, Laura Verdurme, Mathilde Roussel, Sabine Trombert-Paolantoni, Benoit Visseaux, Stephanie Haim-Boukobza, Samuel Alizon | <p style="text-align: justify;">Phylodynamic analyses generate important and timely data to optimise public health response to SARS-CoV-2 outbreaks and epidemics. However, their implementation is hampered by the massive amount of sequence data and... | | Bioinformatics, Evolutionary genomics | Emmanuelle Lerat | 2022-12-12 09:04:01 | ||
10 Jul 2023
SNP discovery by exome capture and resequencing in a pea genetic resource collectionThe value of a large Pisum SNP datasetRecommended by Wanapinun Nawae based on reviews by Rui Borges and 1 anonymous reviewerOne important goal of modern genetics is to establish functional associations between genotype and phenotype. Single nucleotide polymorphisms (SNPs) are numerous and widely distributed in the genome and can be obtained from nucleic acid sequencing (1). SNPs allow for the investigation of genetic diversity, which is critical for increasing crop resilience to the challenges posed by global climate change. The associations between SNPs and phenotypes can be captured in genome-wide association studies. SNPs can also be used in combination with machine learning, which is becoming more popular for predicting complex phenotypic traits like yield and biotic and abiotic stress tolerance from genotypic data (2). The availability of many SNP datasets is important in machine learning predictions because this approach requires big data to build a comprehensive model of the association between genotype and phenotype. Aubert and colleagues have studied, as part of the PeaMUST project, the genetic diversity of 240 Pisum accessions (3). They sequenced exome-enriched genomic libraries, a technique that enables the identification of high-density, high-quality SNPs at a low cost (4). This technique involves capturing and sequencing only the exonic regions of the genome, which are the protein-coding regions. A total of 2,285,342 SNPs were obtained in this study. The analysis of these SNPs with the annotations of the genome sequence of one of the studied pea accessions (5) identified a number of SNPs that could have an impact on gene activity. Additional analyses revealed 647,220 SNPs that were unique to individual pea accessions, which might contribute to the fitness and diversity of accessions in different habitats. Phylogenetic and clustering analyses demonstrated that the SNPs could distinguish Pisum germplasms based on their agronomic and evolutionary histories. These results point out the power of selected SNPs as markers for identifying Pisum individuals. Overall, this study found high-quality SNPs that are meaningful in a biological context. This dataset was derived from a large set of germplasm and is thus particularly useful for studying genotype-phenotype associations, as well as the diversity within Pisum species. These SNPs could also be used in breeding programs to develop new pea varieties that are resilient to abiotic and biotic stressors. References
https://doi.org/10.1139/gen-2021-005
https://doi.org/10.1186/s12870-022-03559-z
https://doi.org/10.1101/2022.08.03.502586
https://doi.org/10.1534/g3.115.018564
| SNP discovery by exome capture and resequencing in a pea genetic resource collection | G. Aubert, J. Kreplak, M. Leveugle, H. Duborjal, A. Klein, K. Boucherot, E. Vieille, M. Chabert-Martinello, C. Cruaud, V. Bourion, I. Lejeune-Hénaut, M.L. Pilet-Nayel, Y. Bouchenak-Khelladi, N. Francillonne, N. Tayeh, J.P. Pichon, N. Rivière, J. B... | <p style="text-align: justify;"><strong>Background & Summary</strong></p> <p style="text-align: justify;">In addition to being the model plant used by Mendel to establish genetic laws, pea (<em>Pisum sativum</em> L., 2n=14) is a major pulse c... | | Plants, Population genomics | Wanapinun Nawae | 2022-11-29 09:29:06 | ||
22 May 2023

Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approachScoring symptoms of a plant viral diseaseRecommended by Olivier Panaud based on reviews by Grégoire Aubert and Valérie GeffroyThe paper from Silva et al. (2023) provides new insights into the genetic bases of natural resistance of rice to the Rice Hoja Blanca (RHB) disease, one of its most serious diseases in tropical countries of the American continent and the Caribbean. This disease is caused by the Rice Hoja Blanca Virus, or RHBV, the vector of which is the planthopper insect Tagosodes orizicolus Müir. It is responsible for serious damage to the rice crop (Morales and Jennings 2010). The authors take a Quantitative Trait Loci (QTL) detection approach to find genomic regions statistically associated with the resistant phenotype. To this aim, they use four resistant x susceptible crosses (the susceptible parent being the same in all four crosses) to maximize the chances to find new QTLs. The F2 populations derived from the crosses are genotyped using Single Nucleotide Polymorphisms (SNPs) extracted from whole-genome sequencing (WGS) data of the resistant parents, and the F3 families derived from the F2 individuals are scored for disease symptoms. For this, they use a computer-aided image analysis protocol that they designed so they can estimate the severity of the damages in the plant. They find several new QTLs, some being apparently more associated with disease severity, others with disease incidence. They also find that a previously identified QTL of Oryza sativa ssp. japonica origin is also present in the indica cluster (Romero et al. 2014). Finally, they discuss the candidate genes that could underlie the QTLs and provide a simple model for resistance. It has to be noted that scoring symptoms of a viral disease such as RHB is very challenging. It requires maintaining populations of viruliferous insect vectors, mastering times and conditions for infestation by nymphs, and precise symptom scoring. It also requires the preparation of segregating populations, their genotyping with enough genetic markers, and mastering QTL detection methods. All these aspects are present in this work. In particular, the phenotyping of symptom severity implemented using computer-aided image processing represents an impressive, enormous amount of work. From the genomics side, the fine-scale genotyping is based on the WGS of the parental lines (resistant and susceptible), followed by the application of suitable bioinformatic tools for SNP extraction and primers prediction that can be used on their Fluidigm platform. It also required implementing data correction algorithms to achieve precise genetic maps in the four crosses. The QTL detection itself required careful statistical pre-processing of phenotypic data. The authors then used a combination of several QTL detection methods, including an original meta-QTL method they developed in the software MapDisto. The authors then perform a very complete and convincing analysis of candidate genes, which includes genes already identified for a similar disease (RSV) on chromosome 11 of rice. What remains to elucidate is whether the candidate genes are actually involved or not in the disease resistance process. The team has already started implementing gene knockout strategies to study some of them in more detail. It will be interesting to see whether those genes act against the virus itself, or against the insect vector. Overall the work is of high quality and represents an important advance in the knowledge of disease resistance. In addition, it has many implications for crop breeding, allowing the setup of large-scale, marker-assisted strategies, for new resistant elite varieties of rice. References Morales F and Jennings P (2010) Rice hoja blanca: a complex plant-virus-vector pathosystem. CAB Reviews. https://doi.org/10.1079/PAVSNNR20105043 Romero LE, Lozano I, Garavito A, et al (2014) Major QTLs control resistance to Rice hoja blanca virus and its vector Tagosodes orizicolus. G3 | Genes, Genomes, Genetics 4:133–142. https://doi.org/10.1534/g3.113.009373 Silva A, Montoya ME, Quintero C, Cuasquer J, Tohme J, Graterol E, Cruz M, Lorieux M (2023) Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approach. bioRxiv, 2022.11.07.515427, ver. 2 peer-reviewed and recommended by Peer Community in Genomics https://doi.org/10.1101/2022.11.07.515427 | Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approach | Alexander Silva, Maria Elker Montoya, Constanza Quintero, Juan Cuasquer, Joe Tohme, Eduardo Graterol, Maribel Cruz, Mathias Lorieux | <p style="text-align: justify;">Rice hoja blanca (RHB) is one of the most serious diseases in rice growing areas in tropical Americas. Its causal agent is Rice hoja blanca virus (RHBV), transmitted by the planthopper <em>Tagosodes orizicolus </em>... | | Functional genomics, Plants | Olivier Panaud | 2022-11-09 09:13:30 | ||
22 Nov 2023
The slow evolving genome of the xenacoelomorph worm Xenoturbella bockiGenomic idiosyncrasies of Xenoturbella bocki: morphologically simple yet genetically complexRecommended by Rosa Fernández based on reviews by Christopher Laumer and 1 anonymous reviewerXenoturbella is a genus of morphologically simple bilaterians inhabiting benthic environments. Until very recently, only one species was known from the genus, Xenoturbella bocki Westblad 1949 [1]. Less than a decade ago, five more species were discovered (X. churro, X. monstrosa, X. profunda, X. hollandorum [2] and X. japonica [3]). These enigmatic animals lack an anus, a coelom, reproductive organs, nephrocytes and a centralized nervous system [1]. The systematic classification of the genus has substantially changed in the last decades, with first being considered as its own phylum (Xenoturbellida) and then being clustered together with acoels and nemertodermatids into the phylum Xenacoelomorpha [4,5]. The phylogenetic position of the xenacoelomorphs has been recalcitrant to resolution, with its position ranging from being the sister group to Nephrozoa (ie, protostomes and deuterostomes [6]) to the sister group to Ambulacraria (ie, Hemichordata and Echinodermata) in a clade called Xenambulacraria [4]. Recent studies based on expanded datasets and more refined analyses support either topology [7,8]. Either way, it is clear that additional studies on Xenoturbella could provide important insights into the origins of bilaterian traits such as the anus, the nephrons and the evolution of a centralized nervous system.
In any case, we are approaching a qualitative jump in how we understand phylogenomics thanks to efforts derived from the availability of chromosome-level genome assemblies for a growing number of species. Exciting times are ahead for us, evolutionary biologists, to explore what high-quality genomes - in combination with multiomics datasets - will reveal about animal evolution. I am personally really looking forward to it. References 1. Westblad E. (1949). Xenoturbella bocki n.g., n.sp., a peculiar, primitive Turbellarian type. Arkiv för Zoologi 1, 3-29 (1949). 2. Rouse, G. W., Wilson, N. G., Carvajal, J. I. & Vrijenhoek, R. C. New deep-sea species of Xenoturbella and the position of Xenacoelomorpha. Nature 530, 94–97 (2016). https://doi.org/10.1038/nature16545 3. Nakano, H. et al. Correction to: A new species of Xenoturbella from the western Pacific Ocean and the evolution of Xenoturbella. BMC Evol. Biol. 18, 1–2 (2018). https://doi.org/10.1186/s12862-018-1190-5https://doi.org/10.1186/s12862-018-1190-5 4. Philippe, H. et al. Acoelomorph flatworms are deuterostomes related to Xenoturbella. Nature 470, 255–258 (2011). https://doi.org/10.1038/nature09676 5. Hejnol, A. et al. Assessing the root of bilaterian animals with scalable phylogenomic methods. Proc. Biol. Sci. 276, 4261–4270 (2009). https://doi.org/10.1098/rspb.2009.0896 6. Cannon, J. T. et al. Xenacoelomorpha is the sister group to Nephrozoa. Nature 530, 89–93 (2016). https://doi.org/10.1038/nature16520 7. Laumer, C. E. et al. Revisiting metazoan phylogeny with genomic sampling of all phyla. Proc. Biol. Sci. 286, 20190831 (2019). https://doi.org/10.1098/rspb.2019.0831 8. Philippe, H. et al. Mitigating anticipated effects of systematic errors supports sister-group relationship between Xenacoelomorpha and Ambulacraria. Curr. Biol. 29, 1818–1826.e6 (2019). https://doi.org/10.1016/j.cub.2019.04.009 9. Schiffer, P. H., Natsidis, P., Leite D. J., Robertson, H., Lapraz, F., Marlétaz, F., Fromm, B., Baudry, L., Simpson, F., Høye, E., Zakrzewski, A-C., Kapli, P., Hoff, K. J., Mueller, S., Marbouty, M., Marlow, H., Copley, R. R., Koszul, R., Sarkies, P. & Telford, M .J. The slow evolving genome of the xenacoelomorph worm Xenoturbella bocki. bioRxiv (2023), ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.06.24.497508 10. Suga, H. et al. The Capsaspora genome reveals a complex unicellular prehistory of animals. Nat. Commun. 4, 2325 (2013). https://doi.org/10.1038/ncomms3325 11. Fernández, R. & Gabaldón, T. Gene gain and loss across the metazoan tree of life. Nat Ecol Evol 4, 524–533 (2020). https://doi.org/10.1038/s41559-019-1069-x | The slow evolving genome of the xenacoelomorph worm *Xenoturbella bocki* | Philipp H. Schiffer, Paschalis Natsidis, Daniel J. Leite, Helen Robertson, François Lapraz, Ferdinand Marlétaz, Bastian Fromm, Liam Baudry, Fraser Simpson, Eirik Høye, Anne-C. Zakrzewski, Paschalia Kapli, Katharina J. Hoff, Steven Mueller, Martial... | <p style="text-align: justify;">The evolutionary origins of Bilateria remain enigmatic. One of the more enduring proposals highlights similarities between a cnidarian-like planula larva and simple acoel-like flatworms. This idea is based in part o... | | Evolutionary genomics | Rosa Fernández | 2022-11-01 12:31:53 | ||
24 Feb 2023

MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomesA unique and customizable approach for functionally annotating prokaryotic genomesRecommended by Gavin Douglas based on reviews by Kwee Boon Brandon Seah and Max Emil Schön based on reviews by Kwee Boon Brandon Seah and Max Emil Schön
Macromolecular System Finder (MacSyFinder) v2 (Néron et al., 2023) is a newly updated approach for performing functional annotation of prokaryotic genomes (Abby et al., 2014). This tool parses an input file of protein sequences from a single genome (either ordered by genome location or unordered) and identifies the presence of specific cellular functions (referred to as “systems”). These systems are called based on two criteria: (1) that the "quorum" of a minimum set of core proteins involved is reached the “quorum” of a minimum set of core proteins being involved that are present, and (2) that the genes encoding these proteins are in the expected genomic organization (e.g., within the same order in an operon), when ordered data is provided. I believe the MacSyFinder approach represents an improvement over more commonly used methods exactly because it can incorporate such information on genomic organization, and also because it is more customizable. Before properly appreciating these points, it is worth noting the norms and key challenges surrounding high-throughput functional annotation of prokaryotic genomes. Genome sequences are being added to online repositories at increasing rates, which has led to an enormous amount of bacterial genome diversity available to investigate (Altermann et al., 2022). A key aspect of understanding this diversity is the functional annotation step, which enables genes to be grouped into more biologically interpretable categories. For instance, gene calls can be mapped against existing Clusters of Orthologous Genes, which are themselves grouped into general categories such as ‘Transcription’ and ‘Lipid metabolism’ (Galperin et al., 2021). This approach is valuable but is primarily used for global summaries of functional annotations within a genome: for example, it could be useful to know that a genome is particularly enriched for genes involved in lipid metabolism. However, knowing that a particular gene is involved in the general process of lipid metabolism is less likely to be actionable. In other words, the desired specificity of a gene’s functional annotation will depend on the exact question being investigated. There is no shortage of functional ontologies in genomics that can be applied for this purpose (Douglas and Langille, 2021), and researchers are often overwhelmed by the choice of which functional ontology to use. In this context, giving researchers the ability to precisely specify the gene families and operon structures they are interested in identifying across genomes provides useful control over what precise functions they are profiling. Of course, most researchers will lack the information and/or expertise to fully take advantage of MacSyFinder’s customizable features, but having this option for specialized purposes is valuable. The other MacSyFinder feature that I find especially noteworthy is that it can incorporate genomic organization (e.g., of genes ordered in operons) when calling systems. This is a rare feature among commonly used tools for functional annotation and likely results in much higher specificity. As the authors note, this capability makes the co-occurrence of paralogs, and other divergent genes that share sequence similarity, to contribute less noise (i.e., they result in fewer false positive calls). It is important to emphasize that these features are not new additions in MacSyFinder v2, but there are many other valuable changes. Most practically, this release is written in Python 3, rather than the obsolete Python 2.7, and was made more computationally efficient, which will enable MacSyFinder to be more widely used and more easily maintained moving forward. In addition, the search algorithm for analyzing individual proteins was fundamentally updated as well. The authors show that their improvements to the search algorithm result in an 8% and 20% increase in the number of identified calls for single and multi-locus secretion systems, respectively. Taken together, MacSyFinder v2 represents both practical and scientific improvements over the previous version, which will be of great value to the field. References Abby SS, Néron B, Ménager H, Touchon M, Rocha EPC (2014) MacSyFinder: A Program to Mine Genomes for Molecular Systems with an Application to CRISPR-Cas Systems. PLOS ONE, 9, e110726. https://doi.org/10.1371/journal.pone.0110726 Altermann E, Tegetmeyer HE, Chanyi RM (2022) The evolution of bacterial genome assemblies - where do we need to go next? Microbiome Research Reports, 1, 15. https://doi.org/10.20517/mrr.2022.02 Douglas GM, Langille MGI (2021) A primer and discussion on DNA-based microbiome data and related bioinformatics analyses. Peer Community Journal, 1. https://doi.org/10.24072/pcjournal.2 Galperin MY, Wolf YI, Makarova KS, Vera Alvarez R, Landsman D, Koonin EV (2021) COG database update: focus on microbial diversity, model organisms, and widespread pathogens. Nucleic Acids Research, 49, D274–D281. https://doi.org/10.1093/nar/gkaa1018 Néron B, Denise R, Coluzzi C, Touchon M, Rocha EPC, Abby SS (2023) MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes. bioRxiv, 2022.09.02.506364, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.09.02.506364 | MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes | Bertrand Néron, Rémi Denise, Charles Coluzzi, Marie Touchon, Eduardo P. C. Rocha, Sophie S. Abby | <p style="text-align: justify;">Complex cellular functions are usually encoded by a set of genes in one or a few organized genetic loci in microbial genomes. Macromolecular System Finder (MacSyFinder) is a program that uses these properties to mod... | | Bacteria and archaea, Bioinformatics, Functional genomics | Gavin Douglas | Kwee Boon Brandon Seah, Max Emil Schön | 2022-09-09 10:30:31 | |
23 Sep 2022
MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studiesMATEdb: a new phylogenomic-driven database for MetazoaRecommended by Samuel Abalde based on reviews by 2 anonymous reviewers
The development (and standardization) of high-throughput sequencing techniques has revolutionized evolutionary biology, to the point that we almost see as normal fine-detail studies of genome architecture evolution (Robert et al., 2022), adaptation to new habitats (Rahi et al., 2019), or the development of key evolutionary novelties (Hilgers et al., 2018), to name three examples. One of the fields that has benefited the most is phylogenomics, i.e. the use of genome-wide data for inferring the evolutionary relationships among organisms. Dealing with such amount of data, however, has come with important analytical and computational challenges. Likewise, although the steady generation of genomic data from virtually any organism opens exciting opportunities for comparative analyses, it also creates a sort of “information fog”, where it is hard to find the most appropriate and/or the higher quality data. I have personally experienced this not so long ago, when I had to spend several weeks selecting the most complete transcriptomes from several phyla, moving back and forth between the NCBI SRA repository and the relevant literature. In an attempt to deal with this issue, some research labs have committed their time and resources to the generation of taxa- and topic-specific databases (Lathe et al., 2008), such as MolluscDB (Liu et al., 2021), focused on mollusk genomics, or EukProt (Richter et al., 2022), a protein repository representing the diversity of eukaryotes. A new database that promises to become an important resource in the near future is MATEdb (Fernández et al., 2022), a repository of high-quality genomic data from Metazoa. MATEdb has been developed from publicly available and newly generated transcriptomes and genomes, prioritizing quality over quantity. Upon download, the user has access to both raw data and the related datasets: assemblies, several quality metrics, the set of inferred protein-coding genes, and their annotation. Although it is clear to me that this repository has been created with phylogenomic analyses in mind, I see how it could be generalized to other related problems such as analyses of gene content or evolution of specific gene families. In my opinion, the main strengths of MATEdb are threefold:
On a negative note, I see two main drawbacks. First, as of today (September 16th, 2022) this database is in an early stage and it still needs to incorporate a lot of animal groups. This has been discussed during the revision process and the authors are already working on it, so it is only a matter of time until all major taxa are represented. Second, there is a scalability issue. In its current format it is not possible to select the taxa of interest and the full database has to be downloaded, which will become more and more difficult as it grows. Nonetheless, with the appropriate resources it would be easy to find a better solution. There are plenty of examples that could serve as inspiration, so I hope this does not become a big problem in the future. Altogether, I and the researchers that participated in the revision process believe that MATEdb has the potential to become an important and valuable addition to the metazoan phylogenomics community. Personally, I wish it was available just a few months ago, it would have saved me so much time. References Fernández R, Tonzo V, Guerrero CS, Lozano-Fernandez J, Martínez-Redondo GI, Balart-García P, Aristide L, Eleftheriadi K, Vargas-Chávez C (2022) MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studies. bioRxiv, 2022.07.18.500182, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.07.18.500182 Hilgers L, Hartmann S, Hofreiter M, von Rintelen T (2018) Novel Genes, Ancient Genes, and Gene Co-Option Contributed to the Genetic Basis of the Radula, a Molluscan Innovation. Molecular Biology and Evolution, 35, 1638–1652. https://doi.org/10.1093/molbev/msy052 Lathe W, Williams J, Mangan M, Karolchik, D (2008). Genomic data resources: challenges and promises. Nature Education, 1(3), 2. Liu F, Li Y, Yu H, Zhang L, Hu J, Bao Z, Wang S (2021) MolluscDB: an integrated functional and evolutionary genomics database for the hyper-diverse animal phylum Mollusca. Nucleic Acids Research, 49, D988–D997. https://doi.org/10.1093/nar/gkaa918 Rahi ML, Mather PB, Ezaz T, Hurwood DA (2019) The Molecular Basis of Freshwater Adaptation in Prawns: Insights from Comparative Transcriptomics of Three Macrobrachium Species. Genome Biology and Evolution, 11, 1002–1018. https://doi.org/10.1093/gbe/evz045 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Robert NSM, Sarigol F, Zimmermann B, Meyer A, Voolstra CR, Simakov O (2022) Emergence of distinct syntenic density regimes is associated with early metazoan genomic transitions. BMC Genomics, 23, 143. https://doi.org/10.1186/s12864-022-08304-2 | MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studies | Rosa Fernandez, Vanina Tonzo, Carolina Simon Guerrero, Jesus Lozano-Fernandez, Gemma I Martinez-Redondo, Pau Balart-Garcia, Leandro Aristide, Klara Eleftheriadi, Carlos Vargas-Chavez | <p style="text-align: justify;">With the advent of high throughput sequencing, the amount of genomic data available for animals (Metazoa) species has bloomed over the last decade, especially from transcriptomes due to lower sequencing costs and ea... | | Bioinformatics, Evolutionary genomics, Functional genomics | Samuel Abalde | 2022-07-20 07:30:39 | ||
15 Sep 2022
EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotesEukProt enables reproducible Eukaryota-wide protein sequence analysesRecommended by Gavin Douglas based on reviews by 2 anonymous reviewers
Comparative genomics is a general approach for understanding how genomes differ, which can be considered from many angles. For instance, this approach can delineate how gene content varies across organisms, which can lead to novel hypotheses regarding what those organisms do. It also enables investigations into the sequence-level divergence of orthologous DNA, which can provide insight into how evolutionary forces differentially shape genome content and structure across lineages. Burki F, Roger AJ, Brown MW, Simpson AGB (2020) The New Tree of Eukaryotes. Trends in Ecology & Evolution, 35, 43–55. https://doi.org/10.1016/j.tree.2019.08.008 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE, Bouwman J, Brookes AJ, Clark T, Crosas M, Dillo I, Dumon O, Edmunds S, Evelo CT, Finkers R, Gonzalez-Beltran A, Gray AJG, Groth P, Goble C, Grethe JS, Heringa J, ’t Hoen PAC, Hooft R, Kuhn T, Kok R, Kok J, Lusher SJ, Martone ME, Mons A, Packer AL, Persson B, Rocca-Serra P, Roos M, van Schaik R, Sansone S-A, Schultes E, Sengstag T, Slater T, Strawn G, Swertz MA, Thompson M, van der Lei J, van Mulligen E, Velterop J, Waagmeester A, Wittenburg P, Wolstencroft K, Zhao J, Mons B (2016) The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18 | EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes | Daniel J. Richter, Cédric Berney, Jürgen F. H. Strassert, Yu-Ping Poh, Emily K. Herman, Sergio A. Muñoz-Gómez, Jeremy G. Wideman, Fabien Burki, Colomban de Vargas | <p style="text-align: justify;">EukProt is a database of published and publicly available predicted protein sets selected to represent the breadth of eukaryotic diversity, currently including 993 species from all major supergroups as well as orpha... | | Bioinformatics, Evolutionary genomics | Gavin Douglas | 2022-06-08 14:19:28 | ||
07 Feb 2023
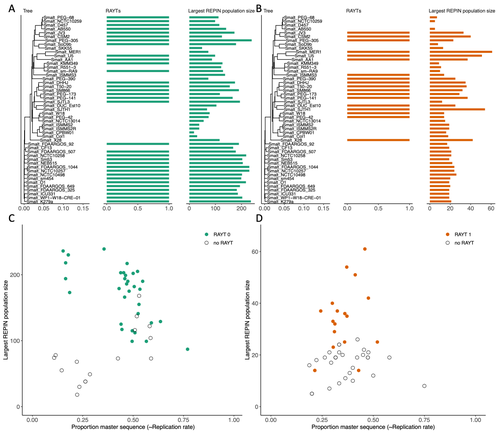
RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomesA workflow for studying enigmatic non-autonomous transposable elements across bacteriaRecommended by Gavin Douglas based on reviews by Sophie Abby and 1 anonymous reviewer
Repetitive extragenic palindromic sequences (REPs) are common repetitive elements in bacterial genomes (Gilson et al., 1984; Stern et al., 1984). In 2011, Bertels and Rainey identified that REPs are overrepresented in pairs of inverted repeats, which likely form hairpin structures, that they referred to as “REP doublets forming hairpins” (REPINs). Based on bioinformatics analyses, they argued that REPINs are likely selfish elements that evolved from REPs flanking particular transposes (Bertels and Rainey, 2011). These transposases, so-called REP-associated tyrosine transposases (RAYTs), were known to be highly associated with the REP content in a genome and to have characteristic upstream and downstream flanking REPs (Nunvar et al., 2010). The flanking REPs likely enable RAYT transposition, and their horizontal replication is physically linked to this process. In contrast, Bertels and Rainey hypothesized that REPINs are selfish elements that are highly replicated due to the similarity in arrangement to these RAYT-flanking REPs, but independent of RAYT transposition and generally with no impact on bacterial fitness (Bertels and Rainey, 2011). This last point was especially contentious, as REPINs are highly conserved within species (Bertels and Rainey, 2023), which is unusual for non-beneficial bacterial DNA (Mira et al., 2001). Bertels and Rainey have since refined their argument to be that REPINs must provide benefits to host cells, but that there are nonetheless signatures of intragenomic conflict in genomes associated with these elements (Bertels and Rainey, 2023). These signatures reflect the divergent levels of selections driving REPIN distribution: selection at the level of each DNA element and selection on each individual bacterium. I found this observation particularly interesting as I and my colleague recently argued that these divergent levels of selection, and the interaction between them, is key to understanding bacterial pangenome diversity (Douglas and Shapiro, 2021). REPINs could be an excellent system for investigating these levels of selection across bacteria more generally. The problem is that REPINs have not been widely characterized in bacterial genomes, partially because no bioinformatic workflow has been available for this purpose. To address this problem, Fortmann-Grote et al. (2023) developed RAREFAN, which is a web server for identifying RAYTs and associated REPINs in a set of input genomes. The authors showcase their tool by applying it to 49 Stenotrophomonas maltophilia genomes and providing examples of how to identify and assess RAYT-REPIN hits. The workflow requires several manual steps, but nonetheless represents a straightforward and standardized approach. Overall, this workflow should enable RAYTs and REPINs to be identified across diverse bacterial species, which will facilitate further investigation into the mechanisms driving their maintenance and spread. References Bertels F, Rainey PB (2023) Ancient Darwinian replicators nested within eubacterial genomes. BioEssays, 45, 2200085. https://doi.org/10.1002/bies.202200085 Bertels F, Rainey PB (2011) Within-Genome Evolution of REPINs: a New Family of Miniature Mobile DNA in Bacteria. PLOS Genetics, 7, e1002132. https://doi.org/10.1371/journal.pgen.1002132 Douglas GM, Shapiro BJ (2021) Genic Selection Within Prokaryotic Pangenomes. Genome Biology and Evolution, 13, evab234. https://doi.org/10.1093/gbe/evab234 Fortmann-Grote C, Irmer J von, Bertels F (2023) RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes. bioRxiv, 2022.05.22.493013, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.05.22.493013 Gilson E, Clément J m., Brutlag D, Hofnung M (1984) A family of dispersed repetitive extragenic palindromic DNA sequences in E. coli. The EMBO Journal, 3, 1417–1421. https://doi.org/10.1002/j.1460-2075.1984.tb01986.x Mira A, Ochman H, Moran NA (2001) Deletional bias and the evolution of bacterial genomes. Trends in Genetics, 17, 589–596. https://doi.org/10.1016/S0168-9525(01)02447-7 Nunvar J, Huckova T, Licha I (2010) Identification and characterization of repetitive extragenic palindromes (REP)-associated tyrosine transposases: implications for REP evolution and dynamics in bacterial genomes. BMC Genomics, 11, 44. https://doi.org/10.1186/1471-2164-11-44 Stern MJ, Ames GF-L, Smith NH, Clare Robinson E, Higgins CF (1984) Repetitive extragenic palindromic sequences: A major component of the bacterial genome. Cell, 37, 1015–1026. https://doi.org/10.1016/0092-8674(84)90436-7 | RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes | Frederic Bertels, Julia von Irmer, Carsten Fortmann-Grote | <p style="text-align: justify;">Compared to eukaryotes, repetitive sequences are rare in bacterial genomes and usually do not persist for long. Yet, there is at least one class of persistent prokaryotic mobile genetic elements: REPINs. REPINs are ... | | Bacteria and archaea, Bioinformatics, Evolutionary genomics, Viruses and transposable elements | Gavin Douglas | 2022-06-07 08:21:34 | ||
25 Nov 2022
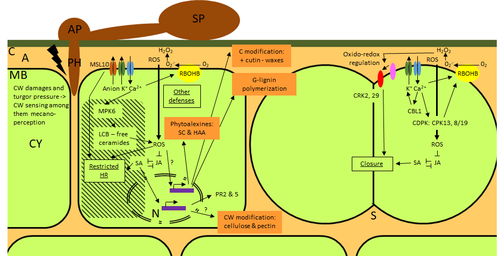
Phenotypic and transcriptomic analyses reveal major differences between apple and pear scab nonhost resistanceApples and pears: two closely related species with differences in scab nonhost resistanceRecommended by Wirulda Pootakham based on reviews by 3 anonymous reviewersNonhost resistance is a common form of disease resistance exhibited by plants against microorganisms that are pathogenic to other plant species [1]. Apples and pears are two closely related species belonging to Rosaceae family, both affected by scab disease caused by fungal pathogens in the Venturia genus. These pathogens appear to be highly host-specific. While apples are nonhosts for Venturia pyrina, pears are nonhosts for Venturia inaequalis. To date, the molecular bases of scab nonhost resistance in apple and pear have not been elucidated. This preprint by Vergne, et al (2022) [2] analyzed nonhost resistance symptoms in apple/V. pyrina and pear/V. inaequalis interactions as well as their transcriptomic responses. Interestingly, the author demonstrated that the nonhost apple/V. pyrina interaction was almost symptomless while hypersensitive reactions were observed for pear/V. inaequalis interaction. The transcriptomic analyses also revealed a number of differentially expressed genes (DEGs) that corresponded to the severity of the interactions, with very few DEGs observed during the apple/V. pyrina interaction and a much higher number of DEGs during the pear/V. inaequalis interaction. This type of reciprocal host-pathogen interaction study is valuable in gaining new insights into how plants interact with microorganisms that are potential pathogens in related species. A few processes appeared to be involved in the pear resistance against the nonhost pathogen V. inaequalis at the transcriptomic level, such as stomata closure, modification of cell wall and production of secondary metabolites as well as phenylpropanoids. Based on the transcriptomics changes during the nonhost interaction, the author compared the responses to those of host-pathogen interactions and revealed some interesting findings. They proposed a series of cascading effects in pear induced by the presence of V. inaequalis, which I believe helps shed some light on the basic mechanism for nonhost resistance. I am recommending this study because it provides valuable information that will strengthen our understanding of nonhost resistance in the Rosaceae family and other plant species. The knowledge gained here may be applied to genetically engineer plants for a broader resistance against a number of pathogens in the future. References 1. Senthil-Kumar M, Mysore KS (2013) Nonhost Resistance Against Bacterial Pathogens: Retrospectives and Prospects. Annual Review of Phytopathology, 51, 407–427. https://doi.org/10.1146/annurev-phyto-082712-102319 2. Vergne E, Chevreau E, Ravon E, Gaillard S, Pelletier S, Bahut M, Perchepied L (2022) Phenotypic and transcriptomic analyses reveal major differences between apple and pear scab nonhost resistance. bioRxiv, 2021.06.01.446506, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.06.01.446506 | Phenotypic and transcriptomic analyses reveal major differences between apple and pear scab nonhost resistance | E. Vergne, E. Chevreau, E. Ravon, S. Gaillard, S. Pelletier, M. Bahut, L. Perchepied | <p style="text-align: justify;"><strong>Background. </strong>Nonhost resistance is the outcome of most plant/pathogen interactions, but it has rarely been described in Rosaceous fruit species. Apple (<em>Malus x domestica</em> Borkh.) have a nonho... | | Functional genomics, Plants | Wirulda Pootakham | Jessica Soyer, Anonymous | 2022-05-13 15:06:08 | |
13 Jul 2022
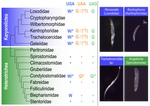
Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codonsAn accident frozen in time: the ambiguous stop/sense genetic code of karyorelict ciliatesRecommended by Iker Irisarri based on reviews by Vittorio Boscaro and 2 anonymous reviewers
Several variations of the “universal” genetic code are known. Among the most striking are those where a codon can either encode for an amino acid or a stop signal depending on the context. Such ambiguous codes are known to have evolved in eukaryotes multiple times independently, particularly in ciliates – eight different codes have so far been discovered (1). We generally view such genetic codes are rare ‘variants’ of the standard code restricted to single species or strains, but this might as well reflect a lack of study of closely related species. In this study, Seah and co-authors (2) explore the possibility of codon reassignment in karyorelict ciliates closely related to Parduczia sp., which has been shown to contain an ambiguous genetic code (1). Here, single-cell transcriptomics are used, along with similar available data, to explore the possibility of codon reassignment across the diversity of Karyorelictea (four out of the six recognized families). Codon reassignments were inferred from their frequencies within conserved Pfam (3) protein domains, whereas stop codons were inferred from full-length transcripts with intact 3’-UTRs. Results show the reassignment of UAA and UAG stop codons to code for glutamine (Q) and the reassignment of the UGA stop codon into tryptophan (W). This occurs only within the coding sequences, whereas the end of transcription is marked by UGA as the main stop codon, and to a lesser extent by UAA. In agreement with a previous model proposed that explains the functioning of ambiguous codes (1,4), the authors observe a depletion of in-frame UGAs before the UGA codon that indicates the stop, thus avoiding premature termination of transcription. The inferred codon reassignments occur in all studied karyorelicts, including the previously studied Parduczia sp. Despite the overall clear picture, some questions remain. Data for two out of six main karyorelict lineages are so far absent and the available data for Cryptopharyngidae was inconclusive; the phylogenetic affinities of Cryptopharyngidae have also been questioned (5). This indicates the need for further study of this interesting group of organisms. As nicely discussed by the authors, experimental evidence could further strengthen the conclusions of this paper, including ribosome profiling, mass spectrometry – as done for Condylostoma (1) – or even direct genetic manipulation. The uniformity of the ambiguous genetic code across karyorelicts might at first seem dull, but when viewed in a phylogenetic context character distribution strongly suggest that this genetic code has an ancient origin in the karyorelict ancestor ~455 Ma in the Proterozoic (6). This ambiguous code is also not a rarity of some obscure species, but it is shared by ciliates that are very diverse and ecologically important. The origin of the karyorelict code is also intriguing. Adaptive arguments suggest that it could confer robustness to mutations causing premature stop codons. However, we lack evidence for ambiguous codes being linked to specific habitats of lifestyles that could account for it. Instead, the authors favor the neutral view of an ancient “frozen accident”, fixed stochastically simply because it did not pose a significant selective disadvantage. Once a stop codon is reassigned to an amino acid, it is increasingly difficult to revert this without the deleterious effect of prematurely terminating translation. At the end, the origin of the genetic code itself is thought to be a frozen accident too (7). References 1. Swart EC, Serra V, Petroni G, Nowacki M. Genetic codes with no dedicated stop codon: Context-dependent translation termination. Cell 2016;166: 691–702. https://doi.org/10.1016/j.cell.2016.06.020 2. Seah BKB, Singh A, Swart EC (2022) Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons. bioRxiv, 2022.04.12.488043. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.12.488043 3. Mistry J, Chuguransky S, Williams L, Qureshi M, Salazar GA, Sonnhammer ELL, Tosatto SCE, Paladin L, Raj S, Richardson LJ, Finn RD, Bateman A. Pfam: The protein families database in 2021, Nuc Acids Res 2020;49: D412-D419. https://doi.org/10.1093/nar/gkaa913 4. Alkalaeva E, Mikhailova T. Reassigning stop codons via translation termination: How a few eukaryotes broke the dogma. Bioessays. 2017;39. https://doi.org/10.1002/bies.201600213 5. Xu Y, Li J, Song W, Warren A. Phylogeny and establishment of a new ciliate family, Wilbertomorphidae fam. nov. (Ciliophora, Karyorelictea), a highly specialized taxon represented by Wilbertomorpha colpoda gen. nov., spec. nov. J Eukaryot Microbiol. 2013;60: 480–489. https://doi.org/10.1111/jeu.12055 6. Fernandes NM, Schrago CG. A multigene timescale and diversification dynamics of Ciliophora evolution. Mol Phylogenet Evol. 2019;139: 106521. https://doi.org/10.1016/j.ympev.2019.106521 7. Crick FH. The origin of the genetic code. J Mol Biol. 1968;38: 367–379. https://doi.org/10.1016/0022-2836(68)90392-6 | Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons | Brandon Kwee Boon Seah, Aditi Singh, Estienne Carl Swart | <p style="text-align: justify;">In ambiguous stop/sense genetic codes, the stop codon(s) not only terminate translation but can also encode amino acids. Such codes have evolved at least four times in eukaryotes, twice among ciliates (<em>Condylost... | | Bioinformatics, Evolutionary genomics | Iker Irisarri | 2022-05-02 11:06:10 |




