
Latest recommendations

| Id | Title | Authors▼ | Abstract | Picture | Thematic fields | Recommender | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
13 Jul 2022
Nucleosome patterns in four plant pathogenic fungi with contrasted genome structuresGenome-wide chromatin and expression datasets of various pathogenic ascomycetesRecommended by Sébastien Bloyer and Romain Koszul based on reviews by Ricardo C. Rodríguez de la Vega and 1 anonymous reviewerPlant pathogenic fungi represent serious economic threats. These organisms are rapidly adaptable, with plastic genomes containing many variable regions and evolving rapidly. It is, therefore, useful to characterize their genetic regulation in order to improve their control. One of the steps to do this is to obtain omics data that link their DNA structure and gene expression. Clairet C, Lapalu N, Simon A, Soyer JL, Viaud M, Zehraoui E, Dalmais B, Fudal I, Ponts N (2022) Nucleosome patterns in four plant pathogenic fungi with contrasted genome structures. bioRxiv, 2021.04.16.439968, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.04.16.439968 | Nucleosome patterns in four plant pathogenic fungi with contrasted genome structures | Colin Clairet, Nicolas Lapalu, Adeline Simon, Jessica L. Soyer, Muriel Viaud, Enric Zehraoui, Berengere Dalmais, Isabelle Fudal, Nadia Ponts | <p style="text-align: justify;">Fungal pathogens represent a serious threat towards agriculture, health, and environment. Control of fungal diseases on crops necessitates a global understanding of fungal pathogenicity determinants and their expres... | | Epigenomics, Fungi | Sébastien Bloyer | 2021-04-17 10:32:41 | ||
02 Jun 2023
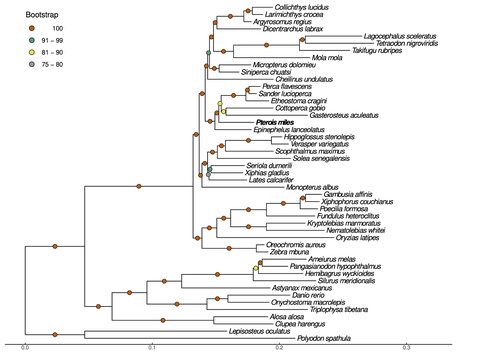
Near-chromosome level genome assembly of devil firefish, Pterois milesThe genome of a dangerous invader (fish) beautyRecommended by Iker Irisarri based on reviews by Maria Recuerda and 1 anonymous reviewer based on reviews by Maria Recuerda and 1 anonymous reviewer
High-quality genomes are currently being generated at an unprecedented speed powered by long-read sequencing technologies. However, sequencing effort is concentrated unequally across the tree of life and several key evolutionary and ecological groups remain largely unexplored. So is the case for fish species of the family Scorpaenidae (Perciformes). Kitsoulis et al. present the genome of the devil firefish, Pterois miles (1). Following current best practices, the assembly relies largely on Oxford Nanopore long reads, aided by Illumina short reads for polishing to increase the per-base accuracy. PacBio’s IsoSeq was used to sequence RNA from a variety of tissues as direct evidence for annotating genes. The reconstructed genome is 902 Mb in size and has high contiguity (N50=14.5 Mb; 660 scaffolds, 90% of the genome covered by the 83 longest scaffolds) and completeness (98% BUSCO completeness). The new genome is used to assess the phylogenetic position of P. miles, explore gene synteny against zebrafish, look at orthogroup expansion and contraction patterns in Perciformes, as well as to investigate the evolution of toxins in scorpaenid fish (2). In addition to its value for better understanding the evolution of scorpaenid and teleost fishes, this new genome is also an important resource for monitoring its invasiveness through the Mediterranean Sea (3) and the Atlantic Ocean, in the latter case forming the invasive lionfish complex with P. volitans (4). REFERENCES 1. Kitsoulis CV, Papadogiannis V, Kristoffersen JB, Kaitetzidou E, Sterioti E, Tsigenopoulos CS, Manousaki T. (2023) Near-chromosome level genome assembly of devil firefish, Pterois miles. BioRxiv, ver. 6 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.01.10.523469 2. Kiriake A, Shiomi K. (2011) Some properties and cDNA cloning of proteinaceous toxins from two species of lionfish (Pterois antennata and Pterois volitans). Toxicon, 58(6-7):494–501. https://doi.org/10.1016/j.toxicon.2011.08.010 3. Katsanevakis S, et al. (2020) Un- published Mediterranean records of marine alien and cryptogenic species. BioInvasions Records, 9:165–182. https://doi.org/10.3391/bir.2020.9.2.01 4. Lyons TJ, Tuckett QM, Hill JE. (2019) Data quality and quantity for invasive species: A case study of the lionfishes. Fish and Fisheries, 20:748–759. https://doi.org/10.1111/faf.12374 | Near-chromosome level genome assembly of devil firefish, *Pterois miles* | Christos V. Kitsoulis, Vasileios Papadogiannis, Jon B. Kristoffersen, Elisavet Kaitetzidou, Aspasia Sterioti, Costas S. Tsigenopoulos, Tereza Manousaki | <p style="text-align: justify;">Devil firefish (<em>Pterois miles</em>), a member of Scorpaenidae family, is one of the most successful marine non-native species, dominating around the world, that was rapidly spread into the Mediterranean Sea, thr... | | Evolutionary genomics | Iker Irisarri | 2023-01-17 12:37:20 | ||
07 Aug 2023
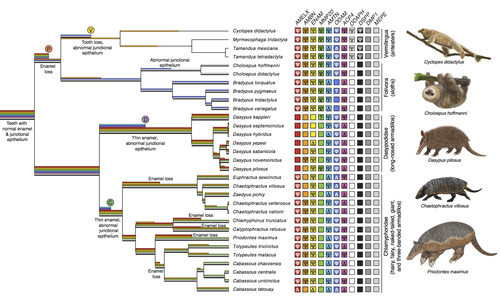
Genomic data suggest parallel dental vestigialization within the xenarthran radiationWhat does dental gene decay tell us about the regressive evolution of teeth in South American mammals?Recommended by Didier Casane based on reviews by Juan C. Opazo, Régis Debruyne and Nicolas PolletA group of mammals, Xenathra, evolved and diversified in South America during its long period of isolation in the early to mid Cenozoic era. More recently, as a result of the Great Faunal Interchange between South America and North America, many xenarthran species went extinct. The thirty-one extant species belong to three groups: armadillos, sloths and anteaters. They share dental degeneration. However, the level of degeneration is variable. Anteaters entirely lack teeth, sloths have intermediately regressed teeth and most armadillos have a toothless premaxilla, as well as peg-like, single-rooted teeth that lack enamel in adult animals (Vizcaíno 2009). This diversity raises a number of questions about the evolution of dentition in these mammals. Unfortunately, the fossil record is too poor to provide refined information on the different stages of regressive evolution in these clades. In such cases, the identification of loss-of-function mutations and/or relaxed selection in genes related to a character regression can be very informative (Emerling and Springer 2014; Meredith et al. 2014; Policarpo et al. 2021). Indeed, shared and unique pseudogenes/relaxed selection can tell us to what extent regression has occurred in common ancestors and whether some changes are lineage-specific. In addition, the distribution of pseudogenes/relaxed selection on the branches of a phylogenetic tree is related to the evolutionary processes involved. A much higher density of pseudogenes in the most internal branches indicates that degeneration took place early and over a short period of time, consistent with selection against the presence of the morphological character with which they are associated, while pseudogenes distributed evenly in many internal and external branches suggest a more gradual process over many millions of years, in line with relaxed selection and fixation of loss-of-function mutations by genetic drift. In this paper (Emerling et al. 2023), the authors examined the dynamics of decay of 11 dental genes that may parallel teeth regression. The analyses of the data reported in this paper clearly point to xenarthran teeth having repeatedly regressed in parallel in the three clades. In fact, no loss-of-function mutation is shared by all species examined. However, more genes should be studied to confirm the hypothesis that the common ancestor of extant xenarthrans had normal dentition. There are distinct patterns of gene loss in different lineages that are associated with the variation in dentition observed across the clades. These patterns of gene loss suggest that regressive evolution took place both gradually and in relatively rapid, discrete phases during the diversification of xenarthrans. This study underscores the utility of using pseudogenes to reconstruct evolutionary history of morphological characters when fossils are sparse. References Emerling CA, Gibb GC, Tilak M-K, Hughes JJ, Kuch M, Duggan AT, Poinar HN, Nachman MW, Delsuc F. 2023. Genomic data suggest parallel dental vestigialization within the xenarthran radiation. bioRxiv, 2022.12.09.519446, ver 2, peer-reviewed and recommended by PCI Genomics. https://doi.org/10.1101/2022.12.09.519446 Emerling CA, Springer MS. 2014. Eyes underground: Regression of visual protein networks in subterranean mammals. Molecular Phylogenetics and Evolution 78: 260-270. https://doi.org/10.1016/j.ympev.2014.05.016 Meredith RW, Zhang G, Gilbert MTP, Jarvis ED, Springer MS. 2014. Evidence for a single loss of mineralized teeth in the common avian ancestor. Science 346: 1254390. https://doi.org/10.1126/science.1254390 Policarpo M, Fumey J, Lafargeas P, Naquin D, Thermes C, Naville M, Dechaud C, Volff J-N, Cabau C, Klopp C, et al. 2021. Contrasting gene decay in subterranean vertebrates: insights from cavefishes and fossorial mammals. Molecular Biology and Evolution 38: 589-605. https://doi.org/10.1093/molbev/msaa249 Vizcaíno SF. 2009. The teeth of the “toothless”: novelties and key innovations in the evolution of xenarthrans (Mammalia, Xenarthra). Paleobiology 35: 343-366. https://doi.org/10.1666/0094-8373-35.3.343 | Genomic data suggest parallel dental vestigialization within the xenarthran radiation | Christopher A Emerling, Gillian C Gibb, Marie-Ka Tilak, Jonathan J Hughes, Melanie Kuch, Ana T Duggan, Hendrik N Poinar, Michael W Nachman, Frederic Delsuc | <p style="text-align: justify;">The recent influx of genomic data has provided greater insights into the molecular basis for regressive evolution, or vestigialization, through gene loss and pseudogenization. As such, the analysis of gene degradati... | | Evolutionary genomics, Vertebrates | Didier Casane | 2022-12-12 16:01:57 | ||
08 Apr 2022

POSTPRINT
Phylogenetics in the Genomic Era“Phylogenetics in the Genomic Era” brings together experts in the field to present a comprehensive synthesisRecommended by Robert Waterhouse and Karen MeusemannE-book: Phylogenetics in the Genomic Era (Scornavacca et al. 2021) This book was not peer-reviewed by PCI Genomics. It has undergone an internal review by the editors. Accurate reconstructions of the relationships amongst species and the genes encoded in their genomes are an essential foundation for almost all evolutionary inferences emerging from downstream analyses. Molecular phylogenetics has developed as a field over many decades to build suites of models and methods to reconstruct reliable trees that explain, support, or refute such inferences. The genomic era has brought new challenges and opportunities to the field, opening up new areas of research and algorithm development to take advantage of the accumulating large-scale data. Such ‘big-data’ phylogenetics has come to be known as phylogenomics, which broadly aims to connect molecular and evolutionary biology research to address questions centred on relationships amongst taxa, mechanisms of molecular evolution, and the biological functions of genes and other genomic elements. This book brings together experts in the field to present a comprehensive synthesis of Phylogenetics in the Genomic Era, covering key conceptual and methodological aspects of how to build accurate phylogenies and how to apply them in molecular and evolutionary research. The paragraphs below briefly summarise the five constituent parts of the book, highlighting the key concepts, methods, and applications that each part addresses. Being organised in an accessible style, while presenting details to provide depth where necessary, and including guides describing real-world examples of major phylogenomic tools, this collection represents an invaluable resource, particularly for students and newcomers to the field of phylogenomics. Part 1: Phylogenetic analyses in the genomic era Modelling how sequences evolve is a fundamental cornerstone of phylogenetic reconstructions. This part of the book introduces the reader to phylogenetic inference methods and algorithmic optimisations in the contexts of Markov, Maximum Likelihood, and Bayesian models of sequence evolution. The main concepts and theoretical considerations are mapped out for probabilistic Markov models, efficient tree building with Maximum Likelihood methods, and the flexibility and robustness of Bayesian approaches. These are supported with practical examples of phylogenomic applications using the popular tools RAxML and PhyloBayes. By considering theoretical, algorithmic, and practical aspects, these chapters provide readers with a holistic overview of the challenges and recent advances in developing scalable phylogenetic analyses in the genomic era. Part 2: Data quality, model adequacy This part focuses on the importance of considering the appropriateness of the evolutionary models used and the accuracy of the underlying molecular and genomic data. Both these aspects can profoundly affect the results when applying current phylogenomic methods to make inferences about complex biological and evolutionary processes. A clear example is presented for methods for building multiple sequence alignments and subsequent filtering approaches that can greatly impact phylogeny inference. The importance of error detection in (meta)barcode sequencing data is also highlighted, with solutions offered by the MACSE_BARCODE pipeline for accurate taxonomic assignments. Orthology datasets are essential markers for phylogenomic inferences, but the overview of concepts and methods presented shows that they too face challenges with respect to model selection and data quality. Finally, an innovative approach using ancestral gene order reconstructions provides new perspectives on how to assess gene tree accuracy for phylogenomic analyses. By emphasising through examples the importance of using appropriate evolutionary models and assessing input data quality, these chapters alert readers to key limitations that the field as a whole strives to address. Part 3: Resolving phylogenomic conflicts Conflicting phylogenetic signals are commonplace and may derive from statistical or systematic bias. This part of the book addresses possible causes of conflict, discordance between gene trees and species trees and how processes that lead to such conflicts can be described by phylogenetic models. Furthermore, it provides an overview of various models and methods with examples in phylogenomics including their pros and cons. Outlined in detail is the multispecies coalescent model (MSC) and its applications in phylogenomics. An interesting aspect is that different phylogenetic signals leading to conflict are in fact a key source of information rather than a problem that can – and should – be used to point to events like introgression or hybridisation, highlighting possible future trends in this research area. Last but not least, this part of the book also addresses inferring species trees by concatenating single multiple sequence alignments (gene alignments) versus inferring the species tree based on ensembles of single gene trees pointing out advantages and disadvantages of both approaches. As an important take home message from these chapters, it is recommended to be flexible and identify the most appropriate approach for each dataset to be analysed since this may tremendously differ depending on the dataset, setting, taxa, and phylogenetic level addressed by the researcher. Part 4: Functional evolutionary genomics In this part of the book the focus shifts to functional considerations of phylogenomics approaches both in terms of molecular evolution and adaptation and with respect to gene expression. The utility of multi-species analysis is clearly presented in the context of annotating functional genomic elements through quantifying evolutionary constraint and protein-coding potential. An historical perspective on characterising rates of change highlights how phylogenomic datasets help to understand the modes of molecular evolution across the genome, over time, and between lineages. These are contextualised with respect to the specific aim of detecting signatures of adaptation from protein-coding DNA alignments using the example of the MutSelDP-ω∗ model. This is extended with the presentation of the generally rare case of adaptive sequence convergence, where consideration of appropriate models and knowledge of gene functions and phenotypic effects are needed. Constrained or relaxed, selection pressures on sequence or copy-number affect genomic elements in different ways, making the very concept of function difficult to pin down despite it being fundamental to relate the genome to the phenotype and organismal fitness. Here gene expression provides a measurable intermediate, for which the Expression Comparison tool from the Bgee suite allows exploration of expression patterns across multiple animal species taking into account anatomical homology. Overall, phylogenomics applications in functional evolutionary genomics build on a rich theoretical history from molecular analyses where integration with knowledge of gene functions is challenging but critical. Part 5: Phylogenomic applications Rather than attempting to review the full extent of applications linked to phylogenomics, this part of the book focuses on providing detailed specific insights into selected examples and methods concerning i) estimating divergence times, and ii) species delimitation in the era of ‘omics’ data. With respect to estimating divergence times, an exemplary overview is provided for fossil data recovered from geological records, either using fossil data as calibration points with an extant-species-inferred phylogeny, or using a fossilised birth-death process as a mechanistic model that accounts for lineage diversification. Included is a tutorial for a joint approach to infer phylogenies and estimate divergence times using the RevBayes software with various models implemented for different applications and datasets incorporating molecular and morphological data. An interesting excursion is outlined focusing on timescale estimates with respect to viral evolution introducing BEAGLE, a high-performance likelihood-calculation platform that can be used on multi-core systems. As a second major subject, species delimitation is addressed since currently the increasing amount of available genomic data enables extensive inferences, for instance about the degree of genetic isolation among species and ancient and recent introgression events. Describing the history of molecular species delimitation up to the current genomic era and presenting widely used computational methods incorporating single- and multi-locus genomic data, pros and cons are addressed. Finally, a proposal for a new method for delimiting species based on empirical criteria is outlined. In the closing chapter of this part of the book, BPP (Bayesian Markov chain Monte Carlo program) for analysing multi-locus sequence data under the multispecies coalescent (MSC) model with and without introgression is introduced, including a tutorial. These examples together provide accessible details on key conceptual and methodological aspects related to the application of phylogenetics in the genomic era. References Scornavacca C, Delsuc F, Galtier N (2021) Phylogenetics in the Genomic Era. https://hal.inria.fr/PGE/ | Phylogenetics in the Genomic Era | Céline Scornavacca, Frédéric Delsuc, Nicolas Galtier | <p style="text-align: justify;">Molecular phylogenetics was born in the middle of the 20th century, when the advent of protein and DNA sequencing offered a novel way to study the evolutionary relationships between living organisms. The first 50 ye... | | Bacteria and archaea, Bioinformatics, Evolutionary genomics, Functional genomics, Fungi, Plants, Population genomics, Vertebrates, Viruses and transposable elements | Robert Waterhouse | 2022-03-15 17:43:52 | ||
06 Jul 2021
A pipeline to detect the relationship between transposable elements and adjacent genes in host genomesA new tool to cross and analyze TE and gene annotationsRecommended by Emmanuelle Lerat based on reviews by 2 anonymous reviewersTransposable elements (TEs) are important components of genomes. Indeed, they are now recognized as having a major role in gene and genome evolution (Biémont 2010). In particular, several examples have shown that the presence of TEs near genes may influence their functioning, either by recruiting particular epigenetic modifications (Guio et al. 2018) or by directly providing new regulatory sequences allowing new expression patterns (Chung et al. 2007; Sundaram et al. 2014). Therefore, the study of the interaction between TEs and their host genome requires tools to easily cross-annotate both types of entities. In particular, one needs to be able to identify all TEs located in the close vicinity of genes or inside them. Such task may not always be obvious for many biologists, as it requires informatics knowledge to develop their own script codes. In their work, Meguerdichian et al. (2021) propose a command-line pipeline that takes as input the annotations of both genes and TEs for a given genome, then detects and reports the positional relationships between each TE insertion and their closest genes. The results are processed into an R script to provide tables displaying some statistics and graphs to visualize these relationships. This tool has the potential to be very useful for performing preliminary analyses before studying the impact of TEs on gene functioning, especially for biologists. Indeed, it makes it possible to identify genes close to TE insertions. These identified genes could then be specifically considered in order to study in more detail the link between the presence of TEs and their functioning. For example, the identification of TEs close to genes may allow to determine their potential role on gene expression. References Biémont C (2010). A brief history of the status of transposable elements: from junk DNA to major players in evolution. Genetics, 186, 1085–1093. https://doi.org/10.1534/genetics.110.124180 Chung H, Bogwitz MR, McCart C, Andrianopoulos A, ffrench-Constant RH, Batterham P, Daborn PJ (2007). Cis-regulatory elements in the Accord retrotransposon result in tissue-specific expression of the Drosophila melanogaster insecticide resistance gene Cyp6g1. Genetics, 175, 1071–1077. https://doi.org/10.1534/genetics.106.066597 Guio L, Vieira C, González J (2018). Stress affects the epigenetic marks added by natural transposable element insertions in Drosophila melanogaster. Scientific Reports, 8, 12197. https://doi.org/10.1038/s41598-018-30491-w Meguerditchian C, Ergun A, Decroocq V, Lefebvre M, Bui Q-T (2021). A pipeline to detect the relationship between transposable elements and adjacent genes in host genomes. bioRxiv, 2021.02.25.432867, ver. 4 peer-reviewed and recommended by Peer Community In Genomics. https://doi.org/10.1101/2021.02.25.432867 Sundaram V, Cheng Y, Ma Z, Li D, Xing X, Edge P, Snyder MP, Wang T (2014). Widespread contribution of transposable elements to the innovation of gene regulatory networks. Genome Research, 24, 1963–1976. https://doi.org/10.1101/gr.168872.113 | A pipeline to detect the relationship between transposable elements and adjacent genes in host genomes | Caroline Meguerditchian, Ayse Ergun, Veronique Decroocq, Marie Lefebvre, Quynh-Trang Bui | <p>Understanding the relationship between transposable elements (TEs) and their closest positional genes in the host genome is a key point to explore their potential role in genome evolution. Transposable elements can regulate and affect gene expr... | | Bioinformatics, Viruses and transposable elements | Emmanuelle Lerat | 2021-03-03 15:08:34 | ||
27 Apr 2021

Uncovering transposable element variants and their potential adaptive impact in urban populations of the malaria vector Anopheles coluzziiAnopheles coluzzii, a new system to study how transposable elements may foster adaptation to urban environmentsRecommended by Anne Roulin based on reviews by Yann Bourgeois and 1 anonymous reviewerTransposable elements (TEs) are mobile DNA sequences that can increase their copy number and move from one location to another within the genome [1]. Because of their transposition dynamics, TEs constitute a significant fraction of eukaryotic genomes. TEs are also known to play an important functional role and a wealth of studies has now reported how TEs may influence single host traits [e.g. 2–4]. Given that TEs are more likely than classical point mutations to cause extreme changes in gene expression and phenotypes, they might therefore be especially prone to produce the raw diversity necessary for individuals to respond to challenging environments [5,6] such as the ones found in urban area.
| Uncovering transposable element variants and their potential adaptive impact in urban populations of the malaria vector Anopheles coluzzii | Carlos Vargas-Chavez, Neil Michel Longo Pendy, Sandrine E. Nsango, Laura Aguilera, Diego Ayala, and Josefa González | <p style="text-align: justify;">Background</p> <p style="text-align: justify;">Anopheles coluzzii is one of the primary vectors of human malaria in sub-Saharan Africa. Recently, it has colonized the main cities of Central Africa threatening vecto... | | Evolutionary genomics | Anne Roulin | 2020-12-02 14:58:47 | ||
13 Jul 2022
Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codonsAn accident frozen in time: the ambiguous stop/sense genetic code of karyorelict ciliatesRecommended by Iker Irisarri based on reviews by Vittorio Boscaro and 2 anonymous reviewers
Several variations of the “universal” genetic code are known. Among the most striking are those where a codon can either encode for an amino acid or a stop signal depending on the context. Such ambiguous codes are known to have evolved in eukaryotes multiple times independently, particularly in ciliates – eight different codes have so far been discovered (1). We generally view such genetic codes are rare ‘variants’ of the standard code restricted to single species or strains, but this might as well reflect a lack of study of closely related species. In this study, Seah and co-authors (2) explore the possibility of codon reassignment in karyorelict ciliates closely related to Parduczia sp., which has been shown to contain an ambiguous genetic code (1). Here, single-cell transcriptomics are used, along with similar available data, to explore the possibility of codon reassignment across the diversity of Karyorelictea (four out of the six recognized families). Codon reassignments were inferred from their frequencies within conserved Pfam (3) protein domains, whereas stop codons were inferred from full-length transcripts with intact 3’-UTRs. Results show the reassignment of UAA and UAG stop codons to code for glutamine (Q) and the reassignment of the UGA stop codon into tryptophan (W). This occurs only within the coding sequences, whereas the end of transcription is marked by UGA as the main stop codon, and to a lesser extent by UAA. In agreement with a previous model proposed that explains the functioning of ambiguous codes (1,4), the authors observe a depletion of in-frame UGAs before the UGA codon that indicates the stop, thus avoiding premature termination of transcription. The inferred codon reassignments occur in all studied karyorelicts, including the previously studied Parduczia sp. Despite the overall clear picture, some questions remain. Data for two out of six main karyorelict lineages are so far absent and the available data for Cryptopharyngidae was inconclusive; the phylogenetic affinities of Cryptopharyngidae have also been questioned (5). This indicates the need for further study of this interesting group of organisms. As nicely discussed by the authors, experimental evidence could further strengthen the conclusions of this paper, including ribosome profiling, mass spectrometry – as done for Condylostoma (1) – or even direct genetic manipulation. The uniformity of the ambiguous genetic code across karyorelicts might at first seem dull, but when viewed in a phylogenetic context character distribution strongly suggest that this genetic code has an ancient origin in the karyorelict ancestor ~455 Ma in the Proterozoic (6). This ambiguous code is also not a rarity of some obscure species, but it is shared by ciliates that are very diverse and ecologically important. The origin of the karyorelict code is also intriguing. Adaptive arguments suggest that it could confer robustness to mutations causing premature stop codons. However, we lack evidence for ambiguous codes being linked to specific habitats of lifestyles that could account for it. Instead, the authors favor the neutral view of an ancient “frozen accident”, fixed stochastically simply because it did not pose a significant selective disadvantage. Once a stop codon is reassigned to an amino acid, it is increasingly difficult to revert this without the deleterious effect of prematurely terminating translation. At the end, the origin of the genetic code itself is thought to be a frozen accident too (7). References 1. Swart EC, Serra V, Petroni G, Nowacki M. Genetic codes with no dedicated stop codon: Context-dependent translation termination. Cell 2016;166: 691–702. https://doi.org/10.1016/j.cell.2016.06.020 2. Seah BKB, Singh A, Swart EC (2022) Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons. bioRxiv, 2022.04.12.488043. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.12.488043 3. Mistry J, Chuguransky S, Williams L, Qureshi M, Salazar GA, Sonnhammer ELL, Tosatto SCE, Paladin L, Raj S, Richardson LJ, Finn RD, Bateman A. Pfam: The protein families database in 2021, Nuc Acids Res 2020;49: D412-D419. https://doi.org/10.1093/nar/gkaa913 4. Alkalaeva E, Mikhailova T. Reassigning stop codons via translation termination: How a few eukaryotes broke the dogma. Bioessays. 2017;39. https://doi.org/10.1002/bies.201600213 5. Xu Y, Li J, Song W, Warren A. Phylogeny and establishment of a new ciliate family, Wilbertomorphidae fam. nov. (Ciliophora, Karyorelictea), a highly specialized taxon represented by Wilbertomorpha colpoda gen. nov., spec. nov. J Eukaryot Microbiol. 2013;60: 480–489. https://doi.org/10.1111/jeu.12055 6. Fernandes NM, Schrago CG. A multigene timescale and diversification dynamics of Ciliophora evolution. Mol Phylogenet Evol. 2019;139: 106521. https://doi.org/10.1016/j.ympev.2019.106521 7. Crick FH. The origin of the genetic code. J Mol Biol. 1968;38: 367–379. https://doi.org/10.1016/0022-2836(68)90392-6 | Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons | Brandon Kwee Boon Seah, Aditi Singh, Estienne Carl Swart | <p style="text-align: justify;">In ambiguous stop/sense genetic codes, the stop codon(s) not only terminate translation but can also encode amino acids. Such codes have evolved at least four times in eukaryotes, twice among ciliates (<em>Condylost... | | Bioinformatics, Evolutionary genomics | Iker Irisarri | 2022-05-02 11:06:10 | ||
24 Feb 2023

MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomesA unique and customizable approach for functionally annotating prokaryotic genomesRecommended by Gavin Douglas based on reviews by Kwee Boon Brandon Seah and Max Emil Schön
Macromolecular System Finder (MacSyFinder) v2 (Néron et al., 2023) is a newly updated approach for performing functional annotation of prokaryotic genomes (Abby et al., 2014). This tool parses an input file of protein sequences from a single genome (either ordered by genome location or unordered) and identifies the presence of specific cellular functions (referred to as “systems”). These systems are called based on two criteria: (1) that the "quorum" of a minimum set of core proteins involved is reached the “quorum” of a minimum set of core proteins being involved that are present, and (2) that the genes encoding these proteins are in the expected genomic organization (e.g., within the same order in an operon), when ordered data is provided. I believe the MacSyFinder approach represents an improvement over more commonly used methods exactly because it can incorporate such information on genomic organization, and also because it is more customizable. Before properly appreciating these points, it is worth noting the norms and key challenges surrounding high-throughput functional annotation of prokaryotic genomes. Genome sequences are being added to online repositories at increasing rates, which has led to an enormous amount of bacterial genome diversity available to investigate (Altermann et al., 2022). A key aspect of understanding this diversity is the functional annotation step, which enables genes to be grouped into more biologically interpretable categories. For instance, gene calls can be mapped against existing Clusters of Orthologous Genes, which are themselves grouped into general categories such as ‘Transcription’ and ‘Lipid metabolism’ (Galperin et al., 2021). This approach is valuable but is primarily used for global summaries of functional annotations within a genome: for example, it could be useful to know that a genome is particularly enriched for genes involved in lipid metabolism. However, knowing that a particular gene is involved in the general process of lipid metabolism is less likely to be actionable. In other words, the desired specificity of a gene’s functional annotation will depend on the exact question being investigated. There is no shortage of functional ontologies in genomics that can be applied for this purpose (Douglas and Langille, 2021), and researchers are often overwhelmed by the choice of which functional ontology to use. In this context, giving researchers the ability to precisely specify the gene families and operon structures they are interested in identifying across genomes provides useful control over what precise functions they are profiling. Of course, most researchers will lack the information and/or expertise to fully take advantage of MacSyFinder’s customizable features, but having this option for specialized purposes is valuable. The other MacSyFinder feature that I find especially noteworthy is that it can incorporate genomic organization (e.g., of genes ordered in operons) when calling systems. This is a rare feature among commonly used tools for functional annotation and likely results in much higher specificity. As the authors note, this capability makes the co-occurrence of paralogs, and other divergent genes that share sequence similarity, to contribute less noise (i.e., they result in fewer false positive calls). It is important to emphasize that these features are not new additions in MacSyFinder v2, but there are many other valuable changes. Most practically, this release is written in Python 3, rather than the obsolete Python 2.7, and was made more computationally efficient, which will enable MacSyFinder to be more widely used and more easily maintained moving forward. In addition, the search algorithm for analyzing individual proteins was fundamentally updated as well. The authors show that their improvements to the search algorithm result in an 8% and 20% increase in the number of identified calls for single and multi-locus secretion systems, respectively. Taken together, MacSyFinder v2 represents both practical and scientific improvements over the previous version, which will be of great value to the field. References Abby SS, Néron B, Ménager H, Touchon M, Rocha EPC (2014) MacSyFinder: A Program to Mine Genomes for Molecular Systems with an Application to CRISPR-Cas Systems. PLOS ONE, 9, e110726. https://doi.org/10.1371/journal.pone.0110726 Altermann E, Tegetmeyer HE, Chanyi RM (2022) The evolution of bacterial genome assemblies - where do we need to go next? Microbiome Research Reports, 1, 15. https://doi.org/10.20517/mrr.2022.02 Douglas GM, Langille MGI (2021) A primer and discussion on DNA-based microbiome data and related bioinformatics analyses. Peer Community Journal, 1. https://doi.org/10.24072/pcjournal.2 Galperin MY, Wolf YI, Makarova KS, Vera Alvarez R, Landsman D, Koonin EV (2021) COG database update: focus on microbial diversity, model organisms, and widespread pathogens. Nucleic Acids Research, 49, D274–D281. https://doi.org/10.1093/nar/gkaa1018 Néron B, Denise R, Coluzzi C, Touchon M, Rocha EPC, Abby SS (2023) MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes. bioRxiv, 2022.09.02.506364, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.09.02.506364 | MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes | Bertrand Néron, Rémi Denise, Charles Coluzzi, Marie Touchon, Eduardo P. C. Rocha, Sophie S. Abby | <p style="text-align: justify;">Complex cellular functions are usually encoded by a set of genes in one or a few organized genetic loci in microbial genomes. Macromolecular System Finder (MacSyFinder) is a program that uses these properties to mod... | | Bacteria and archaea, Bioinformatics, Functional genomics | Gavin Douglas | Kwee Boon Brandon Seah, Max Emil Schön | 2022-09-09 10:30:31 | |
23 Mar 2022
Chromosomal rearrangements with stable repertoires of genes and transposable elements in an invasive forest-pathogenic fungusComparative genomics in the chestnut blight fungus Cryphonectria parasitica reveals large chromosomal rearrangements and a stable genome organizationRecommended by Sebastien Duplessis based on reviews by Benjamin Schwessinger and 1 anonymous reviewerAbout twenty-five years after the sequencing of the first fungal genome and a dozen years after the first plant pathogenic fungi genomes were sequenced, unprecedented international efforts have led to an impressive collection of genomes available for the community of mycologists in international databases (Goffeau et al. 1996, Dean et al. 2005; Spatafora et al. 2017). For instance, to date, the Joint Genome Institute Mycocosm database has collected more than 2,100 fungal genomes over the fungal tree of life (https://mycocosm.jgi.doe.gov). Such resources are paving the way for comparative genomics, population genomics and phylogenomics to address a large panel of questions regarding the biology and the ecology of fungal species. Early on, population genomics applied to pathogenic fungi revealed a great diversity of genome content and organization and a wide variety of variants and rearrangements (Raffaele and Kamoun 2012, Hartmann 2022). Such plasticity raises questions about how to choose a representative genome to serve as an ideal reference to address pertinent biological questions. Cryphonectria parasitica is a fungal pathogen that is infamous for the devastation of chestnut forests in North America after its accidental introduction more than a century ago (Anagnostakis 1987). Since then, it has been a quarantine species under surveillance in various parts of the world. As for other fungi causing diseases on forest trees, the study of adaptation to its host in the forest ecosystem and of its reproduction and dissemination modes is more complex than for crop-targeting pathogens. A first reference genome was published in 2020 for the chestnut blight fungus C. parasitica strain EP155 in the frame of an international project with the DOE JGI (Crouch et al. 2020). Another genome was then sequenced from the French isolate YVO003, which showed a few differences in the assembly suggesting possible rearrangements (Demené et al. 2019). Here the sequencing of a third isolate ESM015 from the native area of C. parasitica in Japan allows to draw broader comparative analysis and particularly to compare between native and introduced isolates (Demené et al. 2022). Demené and collaborators report on a new genome sequence using up-to-date long-read sequencing technologies and they provide an improved genome assembly. Comparison with previously published C. parasitica genomes did not reveal dramatic changes in the overall chromosomal landscapes, but large rearrangements could be spotted. Despite these rearrangements, the genome content and organization – i.e. genes and repeats – remain stable, with a limited number of genes gains and losses. As in any fungal plant pathogen genome, the repertoire of candidate effectors predicted among secreted proteins was more particularly scrutinized. Such effector genes have previously been reported in other pathogens in repeat-enriched plastic genomic regions with accelerated evolutionary rates under the pressure of the host immune system (Raffaele and Kamoun 2012). Demené and collaborators established a list of priority candidate effectors in the C. parasitica gene catalog likely involved in the interaction with the host plant which will require more attention in future functional studies. Six major inter-chromosomal translocations were detected and are likely associated with double break strands repairs. The authors speculate on the possible effects that these translocations may have on gene organization and expression regulation leading to dramatic phenotypic changes in relation to introduction and invasion in new continents and the impact regarding sexual reproduction in this fungus (Demené et al. 2022). I recommend this article not only because it is providing an improved assembly of a reference genome for C. parasitica, but also because it adds diversity in terms of genome references availability, with a third high-quality assembly. Such an effort in the tree pathology community for a pathogen under surveillance is of particular importance for future progress in post-genomic analysis, e.g. in further genomic population studies (Hartmann 2022). References Anagnostakis SL (1987) Chestnut Blight: The Classical Problem of an Introduced Pathogen. Mycologia, 79, 23–37. https://doi.org/10.2307/3807741 Crouch JA, Dawe A, Aerts A, Barry K, Churchill ACL, Grimwood J, Hillman BI, Milgroom MG, Pangilinan J, Smith M, Salamov A, Schmutz J, Yadav JS, Grigoriev IV, Nuss DL (2020) Genome Sequence of the Chestnut Blight Fungus Cryphonectria parasitica EP155: A Fundamental Resource for an Archetypical Invasive Plant Pathogen. Phytopathology®, 110, 1180–1188. https://doi.org/10.1094/PHYTO-12-19-0478-A Dean RA, Talbot NJ, Ebbole DJ, Farman ML, Mitchell TK, Orbach MJ, Thon M, Kulkarni R, Xu J-R, Pan H, Read ND, Lee Y-H, Carbone I, Brown D, Oh YY, Donofrio N, Jeong JS, Soanes DM, Djonovic S, Kolomiets E, Rehmeyer C, Li W, Harding M, Kim S, Lebrun M-H, Bohnert H, Coughlan S, Butler J, Calvo S, Ma L-J, Nicol R, Purcell S, Nusbaum C, Galagan JE, Birren BW (2005) The genome sequence of the rice blast fungus Magnaporthe grisea. Nature, 434, 980–986. https://doi.org/10.1038/nature03449 Demené A., Laurent B., Cros-Arteil S., Boury C. and Dutech C. 2022. Chromosomal rearrangements with stable repertoires of genes and transposable elements in an invasive forest-pathogenic fungus. bioRxiv, 2021.03.09.434572, ver.6 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.03.09.434572 Goffeau A, Barrell BG, Bussey H, Davis RW, Dujon B, Feldmann H, Galibert F, Hoheisel JD, Jacq C, Johnston M, Louis EJ, Mewes HW, Murakami Y, Philippsen P, Tettelin H, Oliver SG (1996) Life with 6000 Genes. Science, 274, 546–567. https://doi.org/10.1126/science.274.5287.546 Hartmann FE (2022) Using structural variants to understand the ecological and evolutionary dynamics of fungal plant pathogens. New Phytologist, 234, 43–49. https://doi.org/10.1111/nph.17907 Raffaele S, Kamoun S (2012) Genome evolution in filamentous plant pathogens: why bigger can be better. Nature Reviews Microbiology, 10, 417–430. https://doi.org/10.1038/nrmicro2790 Spatafora JW, Aime MC, Grigoriev IV, Martin F, Stajich JE, Blackwell M (2017) The Fungal Tree of Life: from Molecular Systematics to Genome-Scale Phylogenies. Microbiology Spectrum, 5, 5.5.03. https://doi.org/10.1128/microbiolspec.FUNK-0053-2016 | Chromosomal rearrangements with stable repertoires of genes and transposable elements in an invasive forest-pathogenic fungus | Arthur Demene, Benoit Laurent, Sandrine Cros-Arteil, Christophe Boury, Cyril Dutech | <p style="text-align: justify;">Chromosomal rearrangements have been largely described among eukaryotes, and may have important consequences on evolution of species. High genome plasticity has been often reported in Fungi, which may explain their ... | | Evolutionary genomics, Fungi | Sebastien Duplessis | 2021-03-12 14:18:20 | ||
16 Dec 2022
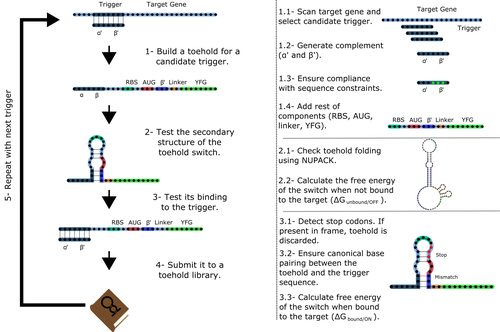
Toeholder: a Software for Automated Design and In Silico Validation of Toehold RiboswitchesA novel approach for engineering biological systems by interfacing computer science with synthetic biologyRecommended by Sahar Melamed based on reviews by Wim Wranken and 1 anonymous reviewerBiological systems depend on finely tuned interactions of their components. Thus, regulating these components is critical for the system's functionality. In prokaryotic cells, riboswitches are regulatory elements controlling transcription or translation. Riboswitches are RNA molecules that are usually located in the 5′-untranslated region of protein-coding genes. They generate secondary structures leading to the regulation of the expression of the downstream protein-coding gene (Kavita and Breaker, 2022). Riboswitches are very versatile and can bind a wide range of small molecules; in many cases, these are metabolic byproducts from the gene’s enzymatic or signaling pathway. Their versatility and abundance in many species make them attractive for synthetic biological circuits. One class that has been drawing the attention of synthetic biologists is toehold switches (Ekdahl et al., 2022; Green et al., 2014). These are single-stranded RNA molecules harboring the necessary elements for translation initiation of the downstream gene: a ribosome-binding site and a start codon. Conformation change of toehold switches is triggered by an RNA molecule, which enables translation. To exploit the most out of toehold switches, automation of their design would be highly advantageous. Cisneros and colleagues (Cisneros et al., 2022) developed a tool, “Toeholder”, that automates the design of toehold switches and performs in silico tests to select switch candidates for a target gene. Toeholder is an open-source tool that provides a comprehensive and automated workflow for the design of toehold switches. While web tools have been developed for designing toehold switches (To et al., 2018), Toeholder represents an intriguing approach to engineering biological systems by coupling synthetic biology with computational biology. Using molecular dynamics simulations, it identified the positions in the toehold switch where hydrogen bonds fluctuate the most. Identifying these regions holds great potential for modifications when refining the design of the riboswitches. To be effective, toehold switches should provide a strong ON signal and a weak OFF signal in the presence or the absence of a target, respectively. Toeholder nicely ranks the candidate toehold switches based on experimental evidence that correlates with toehold performance (based on good ON/OFF ratios). Riboswitches are highly appealing for a broad range of applications, including pharmaceutical and medical purposes (Blount and Breaker, 2006; Giarimoglou et al., 2022; Tickner and Farzan, 2021), thanks to their adaptability and inexpensiveness. The Toeholder tool developed by Cisneros and colleagues is expected to promote the implementation of toehold switches into these various applications. References Blount KF, Breaker RR (2006) Riboswitches as antibacterial drug targets. Nature Biotechnology, 24, 1558–1564. https://doi.org/10.1038/nbt1268 Cisneros AF, Rouleau FD, Bautista C, Lemieux P, Dumont-Leblond N, ULaval 2019 T iGEM (2022) Toeholder: a Software for Automated Design and In Silico Validation of Toehold Riboswitches. bioRxiv, 2021.11.09.467922, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.11.09.467922 Ekdahl AM, Rojano-Nisimura AM, Contreras LM (2022) Engineering Toehold-Mediated Switches for Native RNA Detection and Regulation in Bacteria. Journal of Molecular Biology, 434, 167689. https://doi.org/10.1016/j.jmb.2022.167689 Giarimoglou N, Kouvela A, Maniatis A, Papakyriakou A, Zhang J, Stamatopoulou V, Stathopoulos C (2022) A Riboswitch-Driven Era of New Antibacterials. Antibiotics, 11, 1243. https://doi.org/10.3390/antibiotics11091243 Green AA, Silver PA, Collins JJ, Yin P (2014) Toehold Switches: De-Novo-Designed Regulators of Gene Expression. Cell, 159, 925–939. https://doi.org/10.1016/j.cell.2014.10.002 Kavita K, Breaker RR (2022) Discovering riboswitches: the past and the future. Trends in Biochemical Sciences. https://doi.org/10.1016/j.tibs.2022.08.009 Tickner ZJ, Farzan M (2021) Riboswitches for Controlled Expression of Therapeutic Transgenes Delivered by Adeno-Associated Viral Vectors. Pharmaceuticals, 14, 554. https://doi.org/10.3390/ph14060554 To AC-Y, Chu DH-T, Wang AR, Li FC-Y, Chiu AW-O, Gao DY, Choi CHJ, Kong S-K, Chan T-F, Chan K-M, Yip KY (2018) A comprehensive web tool for toehold switch design. Bioinformatics, 34, 2862–2864. https://doi.org/10.1093/bioinformatics/bty216 | Toeholder: a Software for Automated Design and In Silico Validation of Toehold Riboswitches | Angel F. Cisneros, François D. Rouleau, Carla Bautista, Pascale Lemieux, Nathan Dumont-Leblond | <p>Abstract: Synthetic biology aims to engineer biological circuits, which often involve gene expression. A particularly promising group of regulatory elements are riboswitches because of their versatility with respect to their targets, but e... | | Bioinformatics | Sahar Melamed | 2022-02-16 14:40:13 |




