
Latest recommendations

| Id | Title | Authors | Abstract▼ | Picture | Thematic fields | Recommender | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
13 Jul 2022
Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codonsAn accident frozen in time: the ambiguous stop/sense genetic code of karyorelict ciliatesRecommended by Iker Irisarri based on reviews by Vittorio Boscaro and 2 anonymous reviewers based on reviews by Vittorio Boscaro and 2 anonymous reviewers
Several variations of the “universal” genetic code are known. Among the most striking are those where a codon can either encode for an amino acid or a stop signal depending on the context. Such ambiguous codes are known to have evolved in eukaryotes multiple times independently, particularly in ciliates – eight different codes have so far been discovered (1). We generally view such genetic codes are rare ‘variants’ of the standard code restricted to single species or strains, but this might as well reflect a lack of study of closely related species. In this study, Seah and co-authors (2) explore the possibility of codon reassignment in karyorelict ciliates closely related to Parduczia sp., which has been shown to contain an ambiguous genetic code (1). Here, single-cell transcriptomics are used, along with similar available data, to explore the possibility of codon reassignment across the diversity of Karyorelictea (four out of the six recognized families). Codon reassignments were inferred from their frequencies within conserved Pfam (3) protein domains, whereas stop codons were inferred from full-length transcripts with intact 3’-UTRs. Results show the reassignment of UAA and UAG stop codons to code for glutamine (Q) and the reassignment of the UGA stop codon into tryptophan (W). This occurs only within the coding sequences, whereas the end of transcription is marked by UGA as the main stop codon, and to a lesser extent by UAA. In agreement with a previous model proposed that explains the functioning of ambiguous codes (1,4), the authors observe a depletion of in-frame UGAs before the UGA codon that indicates the stop, thus avoiding premature termination of transcription. The inferred codon reassignments occur in all studied karyorelicts, including the previously studied Parduczia sp. Despite the overall clear picture, some questions remain. Data for two out of six main karyorelict lineages are so far absent and the available data for Cryptopharyngidae was inconclusive; the phylogenetic affinities of Cryptopharyngidae have also been questioned (5). This indicates the need for further study of this interesting group of organisms. As nicely discussed by the authors, experimental evidence could further strengthen the conclusions of this paper, including ribosome profiling, mass spectrometry – as done for Condylostoma (1) – or even direct genetic manipulation. The uniformity of the ambiguous genetic code across karyorelicts might at first seem dull, but when viewed in a phylogenetic context character distribution strongly suggest that this genetic code has an ancient origin in the karyorelict ancestor ~455 Ma in the Proterozoic (6). This ambiguous code is also not a rarity of some obscure species, but it is shared by ciliates that are very diverse and ecologically important. The origin of the karyorelict code is also intriguing. Adaptive arguments suggest that it could confer robustness to mutations causing premature stop codons. However, we lack evidence for ambiguous codes being linked to specific habitats of lifestyles that could account for it. Instead, the authors favor the neutral view of an ancient “frozen accident”, fixed stochastically simply because it did not pose a significant selective disadvantage. Once a stop codon is reassigned to an amino acid, it is increasingly difficult to revert this without the deleterious effect of prematurely terminating translation. At the end, the origin of the genetic code itself is thought to be a frozen accident too (7). References 1. Swart EC, Serra V, Petroni G, Nowacki M. Genetic codes with no dedicated stop codon: Context-dependent translation termination. Cell 2016;166: 691–702. https://doi.org/10.1016/j.cell.2016.06.020 2. Seah BKB, Singh A, Swart EC (2022) Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons. bioRxiv, 2022.04.12.488043. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.12.488043 3. Mistry J, Chuguransky S, Williams L, Qureshi M, Salazar GA, Sonnhammer ELL, Tosatto SCE, Paladin L, Raj S, Richardson LJ, Finn RD, Bateman A. Pfam: The protein families database in 2021, Nuc Acids Res 2020;49: D412-D419. https://doi.org/10.1093/nar/gkaa913 4. Alkalaeva E, Mikhailova T. Reassigning stop codons via translation termination: How a few eukaryotes broke the dogma. Bioessays. 2017;39. https://doi.org/10.1002/bies.201600213 5. Xu Y, Li J, Song W, Warren A. Phylogeny and establishment of a new ciliate family, Wilbertomorphidae fam. nov. (Ciliophora, Karyorelictea), a highly specialized taxon represented by Wilbertomorpha colpoda gen. nov., spec. nov. J Eukaryot Microbiol. 2013;60: 480–489. https://doi.org/10.1111/jeu.12055 6. Fernandes NM, Schrago CG. A multigene timescale and diversification dynamics of Ciliophora evolution. Mol Phylogenet Evol. 2019;139: 106521. https://doi.org/10.1016/j.ympev.2019.106521 7. Crick FH. The origin of the genetic code. J Mol Biol. 1968;38: 367–379. https://doi.org/10.1016/0022-2836(68)90392-6 | Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons | Brandon Kwee Boon Seah, Aditi Singh, Estienne Carl Swart | <p style="text-align: justify;">In ambiguous stop/sense genetic codes, the stop codon(s) not only terminate translation but can also encode amino acids. Such codes have evolved at least four times in eukaryotes, twice among ciliates (<em>Condylost... | | Bioinformatics, Evolutionary genomics | Iker Irisarri | 2022-05-02 11:06:10 | ||
07 Oct 2021

Fine-scale quantification of GC-biased gene conversion intensity in mammalsA systematic approach to the study of GC-biased gene conversion in mammalsRecommended by Carina Farah Mugal based on reviews by Fanny Pouyet , David Castellano and 1 anonymous reviewerThe role of GC-biased gene conversion (gBGC) in molecular evolution has interested scientists for the last two decades since its discovery in 1999 (Eyre-Walker 1999; Galtier et al. 2001). gBGC is a process that is associated with meiotic recombination, and is characterized by a transmission distortion in favor of G and C over A and T alleles at GC/AT heterozygous sites that occur in the vicinity of recombination-inducing double-strand breaks (Duret and Galtier 2009; Mugal et al. 2015). This transmission distortion results in a fixation bias of G and C alleles, equivalent to directional selection for G and C (Nagylaki 1983). The fixation bias subsequently leads to a correlation between recombination rate and GC content across the genome, which has served as indirect evidence for the prevalence of gBGC in many organisms. The fixation bias also produces shifts in the allele frequency spectrum (AFS) towards higher frequencies of G and C alleles. These molecular signatures of gBGC provide a means to quantify the strength of gBGC and study its variation among species and across the genome. Following this idea, first Lartillot (2013) and Capra et al. (2013) developed phylogenetic methodology to quantify gBGC based on substitutions, and De Maio et al. (2013) combined information on polymorphism into a phylogenetic setting. Complementary to the phylogenetic methods, later Glemin et al. (2015) developed a method that draws information solely from polymorphism data and the shape of the AFS. Application of these methods to primates (Capra et al. 2013; De Maio et al. 2013; Glemin et al. 2015) and mammals (Lartillot 2013) supported the notion that variation in the strength of gBGC across the genome reflects the dynamics of the recombination landscape, while variation among species correlates with proxies of the effective population size. However, application of the polymorphism-based method by Glemin et al. (2015) to distantly related Metazoa did not confirm the correlation with effective population size (Galtier et al. 2018). Here, Galtier (2021) introduces a novel phylogenetic approach applicable to the study of closely related species. Specifically, Galtier introduces a statistical framework that enables the systematic study of variation in the strength of gBGC among species and among genes. In addition, Galtier assesses fine-scale variation of gBGC across the genome by means of spatial autocorrelation analysis. This puts Galtier in a position to study variation in the strength of gBGC at three different scales, i) among species, ii) among genes, and iii) within genes. Galtier applies his method to four families of mammals, Hominidae, Cercopithecidae, Bovidae, and Muridae and provides a thorough discussion of his findings and methodology. Galtier found that the strength of gBGC correlates with proxies of the effective population size (Ne), but that the slope of the relationship differs among the four families of mammals. Given the relationship between the population-scaled strength of gBGC B = 4Neb, this finding suggests that the conversion bias (b) could vary among mammalian species. Variation in b could either result from differences in the strength of the transmission distortion (Galtier et al. 2018) or evolutionary changes in the rate of recombination (Boman et al. 2021). Alternatively, Galtier suggests that also systematic variation in proxies of Ne could lead to similar observations. Finally, the present study reports intriguing inter-species differences between the extent of variation in the strength of gBGC among and within genes, which are interpreted in consideration of the recombination dynamics in mammals. References Boman J, Mugal CF, Backström N (2021) The Effects of GC-Biased Gene Conversion on Patterns of Genetic Diversity among and across Butterfly Genomes. Genome Biology and Evolution, 13. https://doi.org/10.1093/gbe/evab064 Capra JA, Hubisz MJ, Kostka D, Pollard KS, Siepel A (2013) A Model-Based Analysis of GC-Biased Gene Conversion in the Human and Chimpanzee Genomes. PLOS Genetics, 9, e1003684. https://doi.org/10.1371/journal.pgen.1003684 De Maio N, Schlötterer C, Kosiol C (2013) Linking Great Apes Genome Evolution across Time Scales Using Polymorphism-Aware Phylogenetic Models. Molecular Biology and Evolution, 30, 2249–2262. https://doi.org/10.1093/molbev/mst131 Duret L, Galtier N (2009) Biased Gene Conversion and the Evolution of Mammalian Genomic Landscapes. Annual Review of Genomics and Human Genetics, 10, 285–311. https://doi.org/10.1146/annurev-genom-082908-150001 Eyre-Walker A (1999) Evidence of Selection on Silent Site Base Composition in Mammals: Potential Implications for the Evolution of Isochores and Junk DNA. Genetics, 152, 675–683. https://doi.org/10.1093/genetics/152.2.675 Galtier N (2021) Fine-scale quantification of GC-biased gene conversion intensity in mammals. bioRxiv, 2021.05.05.442789, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.05.05.442789 Galtier N, Piganeau G, Mouchiroud D, Duret L (2001) GC-Content Evolution in Mammalian Genomes: The Biased Gene Conversion Hypothesis. Genetics, 159, 907–911. https://doi.org/10.1093/genetics/159.2.907 Galtier N, Roux C, Rousselle M, Romiguier J, Figuet E, Glémin S, Bierne N, Duret L (2018) Codon Usage Bias in Animals: Disentangling the Effects of Natural Selection, Effective Population Size, and GC-Biased Gene Conversion. Molecular Biology and Evolution, 35, 1092–1103. https://doi.org/10.1093/molbev/msy015 Glémin S, Arndt PF, Messer PW, Petrov D, Galtier N, Duret L (2015) Quantification of GC-biased gene conversion in the human genome. Genome Research, 25, 1215–1228. https://doi.org/10.1101/gr.185488.114 Lartillot N (2013) Phylogenetic Patterns of GC-Biased Gene Conversion in Placental Mammals and the Evolutionary Dynamics of Recombination Landscapes. Molecular Biology and Evolution, 30, 489–502. https://doi.org/10.1093/molbev/mss239 Mugal CF, Weber CC, Ellegren H (2015) GC-biased gene conversion links the recombination landscape and demography to genomic base composition. BioEssays, 37, 1317–1326. https://doi.org/10.1002/bies.201500058 Nagylaki T (1983) Evolution of a finite population under gene conversion. Proceedings of the National Academy of Sciences, 80, 6278–6281. https://doi.org/10.1073/pnas.80.20.6278 | Fine-scale quantification of GC-biased gene conversion intensity in mammals | Nicolas Galtier | <p style="text-align: justify;">GC-biased gene conversion (gBGC) is a molecular evolutionary force that favours GC over AT alleles irrespective of their fitness effect. Quantifying the variation in time and across genomes of its intensity is key t... | | Evolutionary genomics, Population genomics, Vertebrates | Carina Farah Mugal | 2021-05-25 09:25:52 | ||
13 Jul 2022
Nucleosome patterns in four plant pathogenic fungi with contrasted genome structuresGenome-wide chromatin and expression datasets of various pathogenic ascomycetesRecommended by Sébastien Bloyer and Romain Koszul based on reviews by Ricardo C. Rodríguez de la Vega and 1 anonymous reviewerPlant pathogenic fungi represent serious economic threats. These organisms are rapidly adaptable, with plastic genomes containing many variable regions and evolving rapidly. It is, therefore, useful to characterize their genetic regulation in order to improve their control. One of the steps to do this is to obtain omics data that link their DNA structure and gene expression. Clairet C, Lapalu N, Simon A, Soyer JL, Viaud M, Zehraoui E, Dalmais B, Fudal I, Ponts N (2022) Nucleosome patterns in four plant pathogenic fungi with contrasted genome structures. bioRxiv, 2021.04.16.439968, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.04.16.439968 | Nucleosome patterns in four plant pathogenic fungi with contrasted genome structures | Colin Clairet, Nicolas Lapalu, Adeline Simon, Jessica L. Soyer, Muriel Viaud, Enric Zehraoui, Berengere Dalmais, Isabelle Fudal, Nadia Ponts | <p style="text-align: justify;">Fungal pathogens represent a serious threat towards agriculture, health, and environment. Control of fungal diseases on crops necessitates a global understanding of fungal pathogenicity determinants and their expres... | | Epigenomics, Fungi | Sébastien Bloyer | 2021-04-17 10:32:41 | ||
15 Sep 2022
EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotesEukProt enables reproducible Eukaryota-wide protein sequence analysesRecommended by Gavin Douglas based on reviews by 2 anonymous reviewers
Comparative genomics is a general approach for understanding how genomes differ, which can be considered from many angles. For instance, this approach can delineate how gene content varies across organisms, which can lead to novel hypotheses regarding what those organisms do. It also enables investigations into the sequence-level divergence of orthologous DNA, which can provide insight into how evolutionary forces differentially shape genome content and structure across lineages. Burki F, Roger AJ, Brown MW, Simpson AGB (2020) The New Tree of Eukaryotes. Trends in Ecology & Evolution, 35, 43–55. https://doi.org/10.1016/j.tree.2019.08.008 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE, Bouwman J, Brookes AJ, Clark T, Crosas M, Dillo I, Dumon O, Edmunds S, Evelo CT, Finkers R, Gonzalez-Beltran A, Gray AJG, Groth P, Goble C, Grethe JS, Heringa J, ’t Hoen PAC, Hooft R, Kuhn T, Kok R, Kok J, Lusher SJ, Martone ME, Mons A, Packer AL, Persson B, Rocca-Serra P, Roos M, van Schaik R, Sansone S-A, Schultes E, Sengstag T, Slater T, Strawn G, Swertz MA, Thompson M, van der Lei J, van Mulligen E, Velterop J, Waagmeester A, Wittenburg P, Wolstencroft K, Zhao J, Mons B (2016) The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18 | EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes | Daniel J. Richter, Cédric Berney, Jürgen F. H. Strassert, Yu-Ping Poh, Emily K. Herman, Sergio A. Muñoz-Gómez, Jeremy G. Wideman, Fabien Burki, Colomban de Vargas | <p style="text-align: justify;">EukProt is a database of published and publicly available predicted protein sets selected to represent the breadth of eukaryotic diversity, currently including 993 species from all major supergroups as well as orpha... | | Bioinformatics, Evolutionary genomics | Gavin Douglas | 2022-06-08 14:19:28 | ||
12 Jul 2022

Chromosome-level genome assembly and annotation of two lineages of the ant Cataglyphis hispanica: steppingstones towards genomic studies of hybridogenesis and thermal adaptation in desert antsA genomic resource for ants, and moreRecommended by Nadia Ponts based on reviews by Isabel Almudi and Nicolas NègreThe ant species Cataglyphis hispanica is remarkably well adapted to arid habitats of the Iberian Peninsula where two hybridogenetic lineages co-occur, i.e., queens mating with males from the other lineage produce only non-reproductive hybrid workers whereas reproductive males and females are produced by parthenogenesis (Lavanchy and Schwander, 2019). For these two reasons, the genomes of these lineages, Chis1 and Chis2, are potential gold mines to explore the genetic bases of thermal adaptation and the evolution of alternative reproductive modes. Nowadays, sequencing technology enables assembling all kinds of genomes provided genomic DNA can be extracted. More difficult to achieve is high-quality assemblies with just as high-quality annotations that are readily available to the community to be used and re-used at will (Byrne et al., 2019; Salzberg, 2019). The challenge was successfully completed by Darras and colleagues, the generated resource being fully available to the community, including scripts and command lines used to obtain the proposed results. The authors particularly describe that lineage Chis2 has 27 chromosomes, against 26 or 27 for lineage Chis1, with a Robertsonian translocation identified by chromosome conformation capture (Duan et al., 2010, 2012) in the two Queens sequenced. Transcript-supported gene annotation provided 11,290 high-quality gene models. In addition, an ant-tailored annotation pipeline identified 56 different families of repetitive elements in both Chis1 and Chis2 lineages of C. hispanica spread in a little over 15 % of the genome. Altogether, the genomes of Chis1 and Chis2 are highly similar and syntenic, with some level of polymorphism raising questions about their evolutionary story timeline. In particular, the uniform distribution of polymorphisms along the genomes shakes up a previous hypothesis of hybridogenetic lineage pairs determined by ancient non-recombining regions (Linksvayer, Busch and Smith, 2013). I recommend this paper because the science behind is both solid and well-explained. The provided resource is of high quality, and accompanied by a critical exploration of the perspectives brought by the results. These genomes are excellent resources to now go further in exploring the possible events at the genome level that accompanied the remarkable thermal adaptation of the ants Cataglyphis, as well as insights into the genetics of hybridogenetic lineages. Beyond the scientific value of the resources and insights provided by the work performed, I also recommend this article because it is an excellent example of Open Science (Allen and Mehler, 2019; Sarabipour et al., 2019), all data methods and tools being fully and easily accessible to whoever wants/needs it. References Allen C, Mehler DMA (2019) Open science challenges, benefits and tips in early career and beyond. PLOS Biology, 17, e3000246. https://doi.org/10.1371/journal.pbio.3000246 Byrne A, Cole C, Volden R, Vollmers C (2019) Realizing the potential of full-length transcriptome sequencing. Philosophical Transactions of the Royal Society B: Biological Sciences, 374, 20190097. https://doi.org/10.1098/rstb.2019.0097 Darras H, de Souza Araujo N, Baudry L, Guiglielmoni N, Lorite P, Marbouty M, Rodriguez F, Arkhipova I, Koszul R, Flot J-F, Aron S (2022) Chromosome-level genome assembly and annotation of two lineages of the ant Cataglyphis hispanica: stepping stones towards genomic studies of hybridogenesis and thermal adaptation in desert ants. bioRxiv, 2022.01.07.475286, ver. 3 peer-reviewed and recommended by Peer community in Genomics. https://doi.org/10.1101/2022.01.07.475286 Duan Z, Andronescu M, Schutz K, Lee C, Shendure J, Fields S, Noble WS, Anthony Blau C (2012) A genome-wide 3C-method for characterizing the three-dimensional architectures of genomes. Methods, 58, 277–288. https://doi.org/10.1016/j.ymeth.2012.06.018 Duan Z, Andronescu M, Schutz K, McIlwain S, Kim YJ, Lee C, Shendure J, Fields S, Blau CA, Noble WS (2010) A three-dimensional model of the yeast genome. Nature, 465, 363–367. https://doi.org/10.1038/nature08973 Lavanchy G, Schwander T (2019) Hybridogenesis. Current Biology, 29, R9–R11. https://doi.org/10.1016/j.cub.2018.11.046 Linksvayer TA, Busch JW, Smith CR (2013) Social supergenes of superorganisms: Do supergenes play important roles in social evolution? BioEssays, 35, 683–689. https://doi.org/10.1002/bies.201300038 Salzberg SL (2019) Next-generation genome annotation: we still struggle to get it right. Genome Biology, 20, 92. https://doi.org/10.1186/s13059-019-1715-2 Sarabipour S, Debat HJ, Emmott E, Burgess SJ, Schwessinger B, Hensel Z (2019) On the value of preprints: An early career researcher perspective. PLOS Biology, 17, e3000151. https://doi.org/10.1371/journal.pbio.3000151 | Chromosome-level genome assembly and annotation of two lineages of the ant Cataglyphis hispanica: steppingstones towards genomic studies of hybridogenesis and thermal adaptation in desert ants | Hugo Darras, Natalia de Souza Araujo, Lyam Baudry, Nadège Guiglielmoni, Pedro Lorite, Martial Marbouty, Fernando Rodriguez, Irina Arkhipova, Romain Koszul, Jean-François Flot, Serge Aron | <p style="text-align: justify;"><em>Cataglyphis</em> are thermophilic ants that forage during the day when temperatures are highest and sometimes close to their critical thermal limit. Several Cataglyphis species have evolved unusual reproductive ... | | Evolutionary genomics | Nadia Ponts | Nicolas Nègre, Isabel Almudi | 2022-01-13 16:47:30 | |
02 Jun 2023
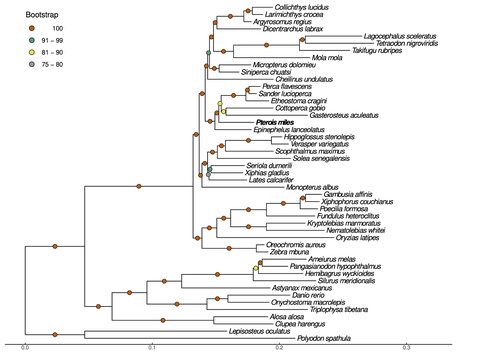
Near-chromosome level genome assembly of devil firefish, Pterois milesThe genome of a dangerous invader (fish) beautyRecommended by Iker Irisarri based on reviews by Maria Recuerda and 1 anonymous reviewer
High-quality genomes are currently being generated at an unprecedented speed powered by long-read sequencing technologies. However, sequencing effort is concentrated unequally across the tree of life and several key evolutionary and ecological groups remain largely unexplored. So is the case for fish species of the family Scorpaenidae (Perciformes). Kitsoulis et al. present the genome of the devil firefish, Pterois miles (1). Following current best practices, the assembly relies largely on Oxford Nanopore long reads, aided by Illumina short reads for polishing to increase the per-base accuracy. PacBio’s IsoSeq was used to sequence RNA from a variety of tissues as direct evidence for annotating genes. The reconstructed genome is 902 Mb in size and has high contiguity (N50=14.5 Mb; 660 scaffolds, 90% of the genome covered by the 83 longest scaffolds) and completeness (98% BUSCO completeness). The new genome is used to assess the phylogenetic position of P. miles, explore gene synteny against zebrafish, look at orthogroup expansion and contraction patterns in Perciformes, as well as to investigate the evolution of toxins in scorpaenid fish (2). In addition to its value for better understanding the evolution of scorpaenid and teleost fishes, this new genome is also an important resource for monitoring its invasiveness through the Mediterranean Sea (3) and the Atlantic Ocean, in the latter case forming the invasive lionfish complex with P. volitans (4). REFERENCES 1. Kitsoulis CV, Papadogiannis V, Kristoffersen JB, Kaitetzidou E, Sterioti E, Tsigenopoulos CS, Manousaki T. (2023) Near-chromosome level genome assembly of devil firefish, Pterois miles. BioRxiv, ver. 6 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.01.10.523469 2. Kiriake A, Shiomi K. (2011) Some properties and cDNA cloning of proteinaceous toxins from two species of lionfish (Pterois antennata and Pterois volitans). Toxicon, 58(6-7):494–501. https://doi.org/10.1016/j.toxicon.2011.08.010 3. Katsanevakis S, et al. (2020) Un- published Mediterranean records of marine alien and cryptogenic species. BioInvasions Records, 9:165–182. https://doi.org/10.3391/bir.2020.9.2.01 4. Lyons TJ, Tuckett QM, Hill JE. (2019) Data quality and quantity for invasive species: A case study of the lionfishes. Fish and Fisheries, 20:748–759. https://doi.org/10.1111/faf.12374 | Near-chromosome level genome assembly of devil firefish, *Pterois miles* | Christos V. Kitsoulis, Vasileios Papadogiannis, Jon B. Kristoffersen, Elisavet Kaitetzidou, Aspasia Sterioti, Costas S. Tsigenopoulos, Tereza Manousaki | <p style="text-align: justify;">Devil firefish (<em>Pterois miles</em>), a member of Scorpaenidae family, is one of the most successful marine non-native species, dominating around the world, that was rapidly spread into the Mediterranean Sea, thr... | | Evolutionary genomics | Iker Irisarri | 2023-01-17 12:37:20 | ||
14 Sep 2023
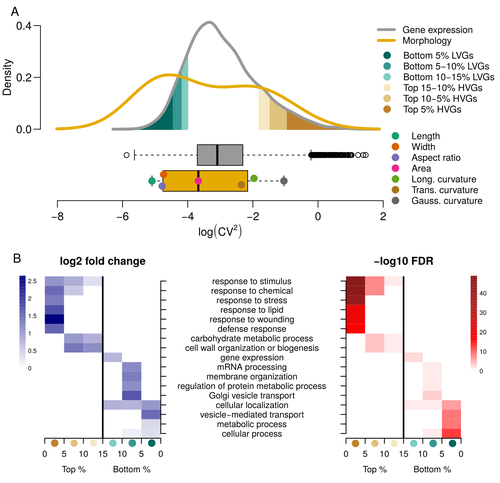
Expression of cell-wall related genes is highly variable and correlates with sepal morphologyThe same but different: How small scale hidden variations can have large effectsRecommended by Francois Sabot based on reviews by Sandra Corjito and 1 anonymous reviewer
For ages, we considered only single genes, or just a few, in order to understand the relationship between phenotype and genotype in response to environmental challenges. Recently, the use of meaningful groups of genes, e.g. gene regulatory networks, or modules of co-expression, allowed scientists to have a larger view of gene regulation. However, all these findings were based on contrasted genotypes, e.g. between wild-types and mutants, as the implicit assumption often made is that there is little transcriptomic variability within the same genotype context. Hartasànchez and collaborators (2023) decided to challenge both views: they used a single genotype instead of two, the famous A. thaliana Col0, and numerous plants, and considered whole gene networks related to sepal morphology and its variations. They used a clever approach, combining high-level phenotyping and gene expression to better understand phenomena and regulations underlying sepal morphologies. Using multiple controls, they showed that basic variations in the expression of genes related to the cell wall regulation, as well as the ones involved in chloroplast metabolism, influenced the global transcriptomic pattern observed in sepal while being in near-identical genetic background and controlling for all other experimental conditions. The paper of Hartasànchez et al. is thus a tremendous call for humility in biology, as we saw in their work that we just understand the gross machinery. However, the Devil is in the details: understanding those very small variations that may have a large influence on phenotypes, and thus on local adaptation to environmental challenges, is of great importance in these times of climatic changes. References Hartasánchez DA, Kiss A, Battu V, Soraru C, Delgado-Vaquera A, Massinon F, Brasó-Vives M, Mollier C, Martin-Magniette M-L, Boudaoud A, Monéger F. 2023. Expression of cell-wall related genes is highly variable and correlates with sepal morphology. bioRxiv, ver. 4, peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.26.489498 | Expression of cell-wall related genes is highly variable and correlates with sepal morphology | Diego A. Hartasánchez, Annamaria Kiss, Virginie Battu, Charline Soraru, Abigail Delgado-Vaquera, Florian Massinon, Marina Brasó-Vives, Corentin Mollier, Marie-Laure Martin-Magniette, Arezki Boudaoud, Françoise Monéger | <p style="text-align: justify;">Control of organ morphology is a fundamental feature of living organisms. There is, however, observable variation in organ size and shape within a given genotype. Taking the sepal of Arabidopsis as a model, we inves... | | Bioinformatics, Epigenomics, Plants | Francois Sabot | 2023-03-14 19:10:15 | ||
24 Feb 2023

MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomesA unique and customizable approach for functionally annotating prokaryotic genomesRecommended by Gavin Douglas based on reviews by Kwee Boon Brandon Seah and Max Emil Schön
Macromolecular System Finder (MacSyFinder) v2 (Néron et al., 2023) is a newly updated approach for performing functional annotation of prokaryotic genomes (Abby et al., 2014). This tool parses an input file of protein sequences from a single genome (either ordered by genome location or unordered) and identifies the presence of specific cellular functions (referred to as “systems”). These systems are called based on two criteria: (1) that the "quorum" of a minimum set of core proteins involved is reached the “quorum” of a minimum set of core proteins being involved that are present, and (2) that the genes encoding these proteins are in the expected genomic organization (e.g., within the same order in an operon), when ordered data is provided. I believe the MacSyFinder approach represents an improvement over more commonly used methods exactly because it can incorporate such information on genomic organization, and also because it is more customizable. Before properly appreciating these points, it is worth noting the norms and key challenges surrounding high-throughput functional annotation of prokaryotic genomes. Genome sequences are being added to online repositories at increasing rates, which has led to an enormous amount of bacterial genome diversity available to investigate (Altermann et al., 2022). A key aspect of understanding this diversity is the functional annotation step, which enables genes to be grouped into more biologically interpretable categories. For instance, gene calls can be mapped against existing Clusters of Orthologous Genes, which are themselves grouped into general categories such as ‘Transcription’ and ‘Lipid metabolism’ (Galperin et al., 2021). This approach is valuable but is primarily used for global summaries of functional annotations within a genome: for example, it could be useful to know that a genome is particularly enriched for genes involved in lipid metabolism. However, knowing that a particular gene is involved in the general process of lipid metabolism is less likely to be actionable. In other words, the desired specificity of a gene’s functional annotation will depend on the exact question being investigated. There is no shortage of functional ontologies in genomics that can be applied for this purpose (Douglas and Langille, 2021), and researchers are often overwhelmed by the choice of which functional ontology to use. In this context, giving researchers the ability to precisely specify the gene families and operon structures they are interested in identifying across genomes provides useful control over what precise functions they are profiling. Of course, most researchers will lack the information and/or expertise to fully take advantage of MacSyFinder’s customizable features, but having this option for specialized purposes is valuable. The other MacSyFinder feature that I find especially noteworthy is that it can incorporate genomic organization (e.g., of genes ordered in operons) when calling systems. This is a rare feature among commonly used tools for functional annotation and likely results in much higher specificity. As the authors note, this capability makes the co-occurrence of paralogs, and other divergent genes that share sequence similarity, to contribute less noise (i.e., they result in fewer false positive calls). It is important to emphasize that these features are not new additions in MacSyFinder v2, but there are many other valuable changes. Most practically, this release is written in Python 3, rather than the obsolete Python 2.7, and was made more computationally efficient, which will enable MacSyFinder to be more widely used and more easily maintained moving forward. In addition, the search algorithm for analyzing individual proteins was fundamentally updated as well. The authors show that their improvements to the search algorithm result in an 8% and 20% increase in the number of identified calls for single and multi-locus secretion systems, respectively. Taken together, MacSyFinder v2 represents both practical and scientific improvements over the previous version, which will be of great value to the field. References Abby SS, Néron B, Ménager H, Touchon M, Rocha EPC (2014) MacSyFinder: A Program to Mine Genomes for Molecular Systems with an Application to CRISPR-Cas Systems. PLOS ONE, 9, e110726. https://doi.org/10.1371/journal.pone.0110726 Altermann E, Tegetmeyer HE, Chanyi RM (2022) The evolution of bacterial genome assemblies - where do we need to go next? Microbiome Research Reports, 1, 15. https://doi.org/10.20517/mrr.2022.02 Douglas GM, Langille MGI (2021) A primer and discussion on DNA-based microbiome data and related bioinformatics analyses. Peer Community Journal, 1. https://doi.org/10.24072/pcjournal.2 Galperin MY, Wolf YI, Makarova KS, Vera Alvarez R, Landsman D, Koonin EV (2021) COG database update: focus on microbial diversity, model organisms, and widespread pathogens. Nucleic Acids Research, 49, D274–D281. https://doi.org/10.1093/nar/gkaa1018 Néron B, Denise R, Coluzzi C, Touchon M, Rocha EPC, Abby SS (2023) MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes. bioRxiv, 2022.09.02.506364, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.09.02.506364 | MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes | Bertrand Néron, Rémi Denise, Charles Coluzzi, Marie Touchon, Eduardo P. C. Rocha, Sophie S. Abby | <p style="text-align: justify;">Complex cellular functions are usually encoded by a set of genes in one or a few organized genetic loci in microbial genomes. Macromolecular System Finder (MacSyFinder) is a program that uses these properties to mod... | | Bacteria and archaea, Bioinformatics, Functional genomics | Gavin Douglas | Kwee Boon Brandon Seah, Max Emil Schön | 2022-09-09 10:30:31 | |
07 Feb 2023
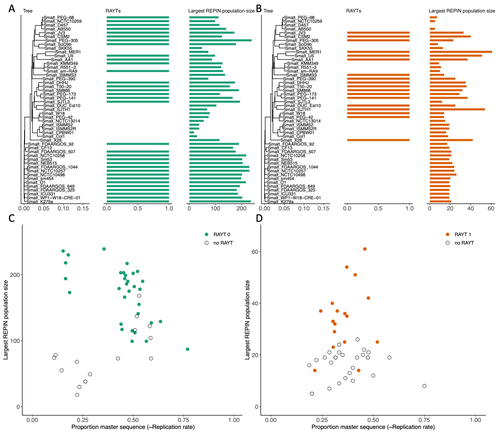
RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomesA workflow for studying enigmatic non-autonomous transposable elements across bacteriaRecommended by Gavin Douglas based on reviews by Sophie Abby and 1 anonymous reviewer
Repetitive extragenic palindromic sequences (REPs) are common repetitive elements in bacterial genomes (Gilson et al., 1984; Stern et al., 1984). In 2011, Bertels and Rainey identified that REPs are overrepresented in pairs of inverted repeats, which likely form hairpin structures, that they referred to as “REP doublets forming hairpins” (REPINs). Based on bioinformatics analyses, they argued that REPINs are likely selfish elements that evolved from REPs flanking particular transposes (Bertels and Rainey, 2011). These transposases, so-called REP-associated tyrosine transposases (RAYTs), were known to be highly associated with the REP content in a genome and to have characteristic upstream and downstream flanking REPs (Nunvar et al., 2010). The flanking REPs likely enable RAYT transposition, and their horizontal replication is physically linked to this process. In contrast, Bertels and Rainey hypothesized that REPINs are selfish elements that are highly replicated due to the similarity in arrangement to these RAYT-flanking REPs, but independent of RAYT transposition and generally with no impact on bacterial fitness (Bertels and Rainey, 2011). This last point was especially contentious, as REPINs are highly conserved within species (Bertels and Rainey, 2023), which is unusual for non-beneficial bacterial DNA (Mira et al., 2001). Bertels and Rainey have since refined their argument to be that REPINs must provide benefits to host cells, but that there are nonetheless signatures of intragenomic conflict in genomes associated with these elements (Bertels and Rainey, 2023). These signatures reflect the divergent levels of selections driving REPIN distribution: selection at the level of each DNA element and selection on each individual bacterium. I found this observation particularly interesting as I and my colleague recently argued that these divergent levels of selection, and the interaction between them, is key to understanding bacterial pangenome diversity (Douglas and Shapiro, 2021). REPINs could be an excellent system for investigating these levels of selection across bacteria more generally. The problem is that REPINs have not been widely characterized in bacterial genomes, partially because no bioinformatic workflow has been available for this purpose. To address this problem, Fortmann-Grote et al. (2023) developed RAREFAN, which is a web server for identifying RAYTs and associated REPINs in a set of input genomes. The authors showcase their tool by applying it to 49 Stenotrophomonas maltophilia genomes and providing examples of how to identify and assess RAYT-REPIN hits. The workflow requires several manual steps, but nonetheless represents a straightforward and standardized approach. Overall, this workflow should enable RAYTs and REPINs to be identified across diverse bacterial species, which will facilitate further investigation into the mechanisms driving their maintenance and spread. References Bertels F, Rainey PB (2023) Ancient Darwinian replicators nested within eubacterial genomes. BioEssays, 45, 2200085. https://doi.org/10.1002/bies.202200085 Bertels F, Rainey PB (2011) Within-Genome Evolution of REPINs: a New Family of Miniature Mobile DNA in Bacteria. PLOS Genetics, 7, e1002132. https://doi.org/10.1371/journal.pgen.1002132 Douglas GM, Shapiro BJ (2021) Genic Selection Within Prokaryotic Pangenomes. Genome Biology and Evolution, 13, evab234. https://doi.org/10.1093/gbe/evab234 Fortmann-Grote C, Irmer J von, Bertels F (2023) RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes. bioRxiv, 2022.05.22.493013, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.05.22.493013 Gilson E, Clément J m., Brutlag D, Hofnung M (1984) A family of dispersed repetitive extragenic palindromic DNA sequences in E. coli. The EMBO Journal, 3, 1417–1421. https://doi.org/10.1002/j.1460-2075.1984.tb01986.x Mira A, Ochman H, Moran NA (2001) Deletional bias and the evolution of bacterial genomes. Trends in Genetics, 17, 589–596. https://doi.org/10.1016/S0168-9525(01)02447-7 Nunvar J, Huckova T, Licha I (2010) Identification and characterization of repetitive extragenic palindromes (REP)-associated tyrosine transposases: implications for REP evolution and dynamics in bacterial genomes. BMC Genomics, 11, 44. https://doi.org/10.1186/1471-2164-11-44 Stern MJ, Ames GF-L, Smith NH, Clare Robinson E, Higgins CF (1984) Repetitive extragenic palindromic sequences: A major component of the bacterial genome. Cell, 37, 1015–1026. https://doi.org/10.1016/0092-8674(84)90436-7 | RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes | Frederic Bertels, Julia von Irmer, Carsten Fortmann-Grote | <p style="text-align: justify;">Compared to eukaryotes, repetitive sequences are rare in bacterial genomes and usually do not persist for long. Yet, there is at least one class of persistent prokaryotic mobile genetic elements: REPINs. REPINs are ... | | Bacteria and archaea, Bioinformatics, Evolutionary genomics, Viruses and transposable elements | Gavin Douglas | 2022-06-07 08:21:34 | ||
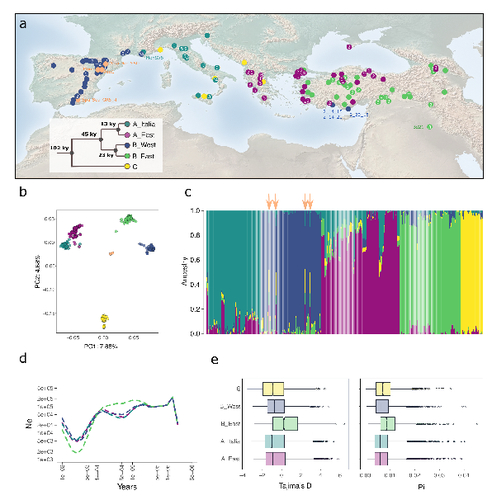
07 Sep 2023
The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological nichesNatural variation and adaptation in Brachypodium distachyonRecommended by Josep Casacuberta based on reviews by Thibault Leroy and 1 anonymous reviewerIdentifying the genetic factors that allow plant adaptation is a major scientific question that is particularly relevant in the face of the climate change that we are already experiencing. To address this, it is essential to have genetic information on a high number of accessions (i.e., plants registered with unique accession numbers) growing under contrasting environmental conditions. There is already an important number of studies addressing these issues in the plant Arabidopsis thaliana, but there is a need to expand these analyses to species that play key roles in wild ecosystems and are close to very relevant crops, as is the case of grasses. The work of Minadakis, Roulin and co-workers (1) presents a Brachypodium distachyon panel of 332 fully sequences accessions that covers the whole species distribution across a wide range of bioclimatic conditions, which will be an invaluable tool to fill this gap. In addition, the authors use this data to start analyzing the population structure and demographic history of this plant, suggesting that the species experienced a shift of its distribution following the Last Glacial Maximum, which may have forced the species into new habitats. The authors also present a modeling of the niches occupied by B. distachyon together with an analysis of the genetic clades found in each of them, and start analyzing the different adaptive loci that may have allowed the species’ expansion into different bioclimatic areas. In addition to the importance of the resources made available by the authors for the scientific community, the analyses presented are well done and carefully discussed, and they highlight the potential of these new resources to investigate the genetic bases of plant adaptation. References 1. Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin. The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological niches. bioRxiv, 2023.06.01.543285, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.01.543285 | The demographic history of the wild crop relative *Brachypodium distachyon* is shaped by distinct past and present ecological niches | Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin | <p style="text-align: justify;">Closely related to economically important crops, the grass <em>Brachypodium distachyon</em> has been originally established as a pivotal species for grass genomics but more recently flourished as a model for develop... | | Evolutionary genomics, Functional genomics, Plants, Population genomics | Josep Casacuberta | 2023-06-14 15:28:30 |




