
Latest recommendations

| Id | Title * | Authors * | Abstract * | Picture * | Thematic fields * | Recommender | Reviewers▲ | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
20 Jul 2021
Genetic mapping of sex and self-incompatibility determinants in the androdioecious plant Phillyrea angustifoliaIdentification of distinct YX-like loci for sex determination and self-incompatibility in an androdioecious shrubRecommended by Tatiana Giraud and Ricardo C. Rodríguez de la Vega based on reviews by 2 anonymous reviewersA wide variety of systems have evolved to control mating compatibility in sexual organisms. Their genetic determinism and the factors controlling their evolution represent fascinating questions in evolutionary biology and genomics. The plant Phillyrea angustifolia (Oleaeceae family) represents an exciting model organism, as it displays two distinct and rare mating compatibility systems [1]: 1) males and hermaphrodites co-occur in populations of this shrub (a rare system called androdioecy), while the evolution and maintenance of purely hermaphroditic plants or mixtures of females and hermaphrodites (a system called gynodioecy) are easier to explain [2]; 2) a homomorphic diallelic self-incompatibility system acts in hermaphrodites, while such systems are usually multi-allelic, as rare alleles are advantageous, being compatible with all other alleles. Previous analyses of crosses brought some interesting answers to these puzzles, showing that males benefit from the ability to mate with all hermaphrodites regardless of their allele at the self-incompatibility system, and suggesting that both sex and self incompatibility are determined by XY-like genetic systems, i.e. with each a dominant allele; homozygotes for a single allele and heterozygotes therefore co-occur in natural populations at both sex and self-incompatibility loci [3]. Here, Carré et al. used genotyping-by-sequencing to build a genome linkage map of P. angustifolia [4]. The elegant and original use of a probabilistic model of segregating alleles (implemented in the SEX-DETector method) allowed to identify both the sex and self-incompatibility loci [4], while this tool was initially developed for detecting sex-linked genes in species with strictly separated sexes (dioecy) [5]. Carré et al. [4] confirmed that the sex and self-incompatibility loci are located in two distinct linkage groups and correspond to XY-like systems. A comparison with the genome of the closely related Olive tree indicated that their self-incompatibility systems were homologous. Such a XY-like system represents a rare genetic determination mechanism for self-incompatibility and has also been recently found to control mating types in oomycetes [6]. This study [4] paves the way for identifying the genes controlling the sex and self-incompatibility phenotypes and for understanding why and how self-incompatibility is only expressed in hermaphrodites and not in males. It will also be fascinating to study more finely the degree and extent of genomic differentiation at these two loci and to assess whether recombination suppression has extended stepwise away from the sex and self-incompatibility loci, as can be expected under some hypotheses, such as the sheltering of deleterious alleles near permanently heterozygous alleles [7]. Furthermore, the co-occurrence in P. angustifolia of sex and mating types can contribute to our understanding of the factor controlling their evolution [8]. References [1] Saumitou-Laprade P, Vernet P, Vassiliadis C, Hoareau Y, Magny G de, Dommée B, Lepart J (2010) A Self-Incompatibility System Explains High Male Frequencies in an Androdioecious Plant. Science, 327, 1648–1650. https://doi.org/10.1126/science.1186687 [2] Pannell JR, Voillemot M (2015) Plant Mating Systems: Female Sterility in the Driver’s Seat. Current Biology, 25, R511–R514. https://doi.org/10.1016/j.cub.2015.04.044 [3] Billiard S, Husse L, Lepercq P, Godé C, Bourceaux A, Lepart J, Vernet P, Saumitou-Laprade P (2015) Selfish male-determining element favors the transition from hermaphroditism to androdioecy. Evolution, 69, 683–693. https://doi.org/10.1111/evo.12613 [4] Carre A, Gallina S, Santoni S, Vernet P, Gode C, Castric V, Saumitou-Laprade P (2021) Genetic mapping of sex and self-incompatibility determinants in the androdioecious plant Phillyrea angustifolia. bioRxiv, 2021.04.15.439943, ver. 7 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.04.15.439943 [5] Muyle A, Käfer J, Zemp N, Mousset S, Picard F, Marais GA (2016) SEX-DETector: A Probabilistic Approach to Study Sex Chromosomes in Non-Model Organisms. Genome Biology and Evolution, 8, 2530–2543. https://doi.org/10.1093/gbe/evw172 [6] Dussert Y, Legrand L, Mazet ID, Couture C, Piron M-C, Serre R-F, Bouchez O, Mestre P, Toffolatti SL, Giraud T, Delmotte F (2020) Identification of the First Oomycete Mating-type Locus Sequence in the Grapevine Downy Mildew Pathogen, Plasmopara viticola. Current Biology, 30, 3897-3907.e4. https://doi.org/10.1016/j.cub.2020.07.057 [7] Jay P, Tezenas E, Giraud T (2021) A deleterious mutation-sheltering theory for the evolution of sex chromosomes and supergenes. bioRxiv, 2021.05.17.444504. https://doi.org/10.1101/2021.05.17.444504 [8] Billiard S, López-Villavicencio M, Devier B, Hood ME, Fairhead C, Giraud T (2011) Having sex, yes, but with whom? Inferences from fungi on the evolution of anisogamy and mating types. Biological Reviews, 86, 421–442. https://doi.org/10.1111/j.1469-185X.2010.00153.x | Genetic mapping of sex and self-incompatibility determinants in the androdioecious plant Phillyrea angustifolia | Amelie Carre, Sophie Gallina, Sylvain Santoni, Philippe Vernet, Cecile Gode, Vincent Castric, Pierre Saumitou-Laprade | <p style="text-align: justify;">The diversity of mating and sexual systems in angiosperms is spectacular, but the factors driving their evolution remain poorly understood. In plants of the Oleaceae family, an unusual self-incompatibility (SI) syst... | | Evolutionary genomics, Plants | Tatiana Giraud | 2021-05-04 10:37:26 | ||
07 Oct 2021

Fine-scale quantification of GC-biased gene conversion intensity in mammalsA systematic approach to the study of GC-biased gene conversion in mammalsRecommended by Carina Farah Mugal based on reviews by Fanny Pouyet , David Castellano and 1 anonymous reviewerThe role of GC-biased gene conversion (gBGC) in molecular evolution has interested scientists for the last two decades since its discovery in 1999 (Eyre-Walker 1999; Galtier et al. 2001). gBGC is a process that is associated with meiotic recombination, and is characterized by a transmission distortion in favor of G and C over A and T alleles at GC/AT heterozygous sites that occur in the vicinity of recombination-inducing double-strand breaks (Duret and Galtier 2009; Mugal et al. 2015). This transmission distortion results in a fixation bias of G and C alleles, equivalent to directional selection for G and C (Nagylaki 1983). The fixation bias subsequently leads to a correlation between recombination rate and GC content across the genome, which has served as indirect evidence for the prevalence of gBGC in many organisms. The fixation bias also produces shifts in the allele frequency spectrum (AFS) towards higher frequencies of G and C alleles. These molecular signatures of gBGC provide a means to quantify the strength of gBGC and study its variation among species and across the genome. Following this idea, first Lartillot (2013) and Capra et al. (2013) developed phylogenetic methodology to quantify gBGC based on substitutions, and De Maio et al. (2013) combined information on polymorphism into a phylogenetic setting. Complementary to the phylogenetic methods, later Glemin et al. (2015) developed a method that draws information solely from polymorphism data and the shape of the AFS. Application of these methods to primates (Capra et al. 2013; De Maio et al. 2013; Glemin et al. 2015) and mammals (Lartillot 2013) supported the notion that variation in the strength of gBGC across the genome reflects the dynamics of the recombination landscape, while variation among species correlates with proxies of the effective population size. However, application of the polymorphism-based method by Glemin et al. (2015) to distantly related Metazoa did not confirm the correlation with effective population size (Galtier et al. 2018). Here, Galtier (2021) introduces a novel phylogenetic approach applicable to the study of closely related species. Specifically, Galtier introduces a statistical framework that enables the systematic study of variation in the strength of gBGC among species and among genes. In addition, Galtier assesses fine-scale variation of gBGC across the genome by means of spatial autocorrelation analysis. This puts Galtier in a position to study variation in the strength of gBGC at three different scales, i) among species, ii) among genes, and iii) within genes. Galtier applies his method to four families of mammals, Hominidae, Cercopithecidae, Bovidae, and Muridae and provides a thorough discussion of his findings and methodology. Galtier found that the strength of gBGC correlates with proxies of the effective population size (Ne), but that the slope of the relationship differs among the four families of mammals. Given the relationship between the population-scaled strength of gBGC B = 4Neb, this finding suggests that the conversion bias (b) could vary among mammalian species. Variation in b could either result from differences in the strength of the transmission distortion (Galtier et al. 2018) or evolutionary changes in the rate of recombination (Boman et al. 2021). Alternatively, Galtier suggests that also systematic variation in proxies of Ne could lead to similar observations. Finally, the present study reports intriguing inter-species differences between the extent of variation in the strength of gBGC among and within genes, which are interpreted in consideration of the recombination dynamics in mammals. References Boman J, Mugal CF, Backström N (2021) The Effects of GC-Biased Gene Conversion on Patterns of Genetic Diversity among and across Butterfly Genomes. Genome Biology and Evolution, 13. https://doi.org/10.1093/gbe/evab064 Capra JA, Hubisz MJ, Kostka D, Pollard KS, Siepel A (2013) A Model-Based Analysis of GC-Biased Gene Conversion in the Human and Chimpanzee Genomes. PLOS Genetics, 9, e1003684. https://doi.org/10.1371/journal.pgen.1003684 De Maio N, Schlötterer C, Kosiol C (2013) Linking Great Apes Genome Evolution across Time Scales Using Polymorphism-Aware Phylogenetic Models. Molecular Biology and Evolution, 30, 2249–2262. https://doi.org/10.1093/molbev/mst131 Duret L, Galtier N (2009) Biased Gene Conversion and the Evolution of Mammalian Genomic Landscapes. Annual Review of Genomics and Human Genetics, 10, 285–311. https://doi.org/10.1146/annurev-genom-082908-150001 Eyre-Walker A (1999) Evidence of Selection on Silent Site Base Composition in Mammals: Potential Implications for the Evolution of Isochores and Junk DNA. Genetics, 152, 675–683. https://doi.org/10.1093/genetics/152.2.675 Galtier N (2021) Fine-scale quantification of GC-biased gene conversion intensity in mammals. bioRxiv, 2021.05.05.442789, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.05.05.442789 Galtier N, Piganeau G, Mouchiroud D, Duret L (2001) GC-Content Evolution in Mammalian Genomes: The Biased Gene Conversion Hypothesis. Genetics, 159, 907–911. https://doi.org/10.1093/genetics/159.2.907 Galtier N, Roux C, Rousselle M, Romiguier J, Figuet E, Glémin S, Bierne N, Duret L (2018) Codon Usage Bias in Animals: Disentangling the Effects of Natural Selection, Effective Population Size, and GC-Biased Gene Conversion. Molecular Biology and Evolution, 35, 1092–1103. https://doi.org/10.1093/molbev/msy015 Glémin S, Arndt PF, Messer PW, Petrov D, Galtier N, Duret L (2015) Quantification of GC-biased gene conversion in the human genome. Genome Research, 25, 1215–1228. https://doi.org/10.1101/gr.185488.114 Lartillot N (2013) Phylogenetic Patterns of GC-Biased Gene Conversion in Placental Mammals and the Evolutionary Dynamics of Recombination Landscapes. Molecular Biology and Evolution, 30, 489–502. https://doi.org/10.1093/molbev/mss239 Mugal CF, Weber CC, Ellegren H (2015) GC-biased gene conversion links the recombination landscape and demography to genomic base composition. BioEssays, 37, 1317–1326. https://doi.org/10.1002/bies.201500058 Nagylaki T (1983) Evolution of a finite population under gene conversion. Proceedings of the National Academy of Sciences, 80, 6278–6281. https://doi.org/10.1073/pnas.80.20.6278 | Fine-scale quantification of GC-biased gene conversion intensity in mammals | Nicolas Galtier | <p style="text-align: justify;">GC-biased gene conversion (gBGC) is a molecular evolutionary force that favours GC over AT alleles irrespective of their fitness effect. Quantifying the variation in time and across genomes of its intensity is key t... | | Evolutionary genomics, Population genomics, Vertebrates | Carina Farah Mugal | 2021-05-25 09:25:52 | ||
16 Dec 2022
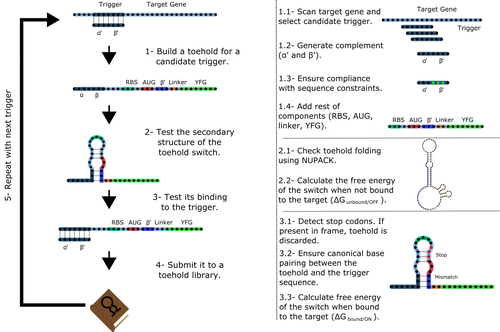
Toeholder: a Software for Automated Design and In Silico Validation of Toehold RiboswitchesA novel approach for engineering biological systems by interfacing computer science with synthetic biologyRecommended by Sahar Melamed based on reviews by Wim Wranken and 1 anonymous reviewerBiological systems depend on finely tuned interactions of their components. Thus, regulating these components is critical for the system's functionality. In prokaryotic cells, riboswitches are regulatory elements controlling transcription or translation. Riboswitches are RNA molecules that are usually located in the 5′-untranslated region of protein-coding genes. They generate secondary structures leading to the regulation of the expression of the downstream protein-coding gene (Kavita and Breaker, 2022). Riboswitches are very versatile and can bind a wide range of small molecules; in many cases, these are metabolic byproducts from the gene’s enzymatic or signaling pathway. Their versatility and abundance in many species make them attractive for synthetic biological circuits. One class that has been drawing the attention of synthetic biologists is toehold switches (Ekdahl et al., 2022; Green et al., 2014). These are single-stranded RNA molecules harboring the necessary elements for translation initiation of the downstream gene: a ribosome-binding site and a start codon. Conformation change of toehold switches is triggered by an RNA molecule, which enables translation. To exploit the most out of toehold switches, automation of their design would be highly advantageous. Cisneros and colleagues (Cisneros et al., 2022) developed a tool, “Toeholder”, that automates the design of toehold switches and performs in silico tests to select switch candidates for a target gene. Toeholder is an open-source tool that provides a comprehensive and automated workflow for the design of toehold switches. While web tools have been developed for designing toehold switches (To et al., 2018), Toeholder represents an intriguing approach to engineering biological systems by coupling synthetic biology with computational biology. Using molecular dynamics simulations, it identified the positions in the toehold switch where hydrogen bonds fluctuate the most. Identifying these regions holds great potential for modifications when refining the design of the riboswitches. To be effective, toehold switches should provide a strong ON signal and a weak OFF signal in the presence or the absence of a target, respectively. Toeholder nicely ranks the candidate toehold switches based on experimental evidence that correlates with toehold performance (based on good ON/OFF ratios). Riboswitches are highly appealing for a broad range of applications, including pharmaceutical and medical purposes (Blount and Breaker, 2006; Giarimoglou et al., 2022; Tickner and Farzan, 2021), thanks to their adaptability and inexpensiveness. The Toeholder tool developed by Cisneros and colleagues is expected to promote the implementation of toehold switches into these various applications. References Blount KF, Breaker RR (2006) Riboswitches as antibacterial drug targets. Nature Biotechnology, 24, 1558–1564. https://doi.org/10.1038/nbt1268 Cisneros AF, Rouleau FD, Bautista C, Lemieux P, Dumont-Leblond N, ULaval 2019 T iGEM (2022) Toeholder: a Software for Automated Design and In Silico Validation of Toehold Riboswitches. bioRxiv, 2021.11.09.467922, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.11.09.467922 Ekdahl AM, Rojano-Nisimura AM, Contreras LM (2022) Engineering Toehold-Mediated Switches for Native RNA Detection and Regulation in Bacteria. Journal of Molecular Biology, 434, 167689. https://doi.org/10.1016/j.jmb.2022.167689 Giarimoglou N, Kouvela A, Maniatis A, Papakyriakou A, Zhang J, Stamatopoulou V, Stathopoulos C (2022) A Riboswitch-Driven Era of New Antibacterials. Antibiotics, 11, 1243. https://doi.org/10.3390/antibiotics11091243 Green AA, Silver PA, Collins JJ, Yin P (2014) Toehold Switches: De-Novo-Designed Regulators of Gene Expression. Cell, 159, 925–939. https://doi.org/10.1016/j.cell.2014.10.002 Kavita K, Breaker RR (2022) Discovering riboswitches: the past and the future. Trends in Biochemical Sciences. https://doi.org/10.1016/j.tibs.2022.08.009 Tickner ZJ, Farzan M (2021) Riboswitches for Controlled Expression of Therapeutic Transgenes Delivered by Adeno-Associated Viral Vectors. Pharmaceuticals, 14, 554. https://doi.org/10.3390/ph14060554 To AC-Y, Chu DH-T, Wang AR, Li FC-Y, Chiu AW-O, Gao DY, Choi CHJ, Kong S-K, Chan T-F, Chan K-M, Yip KY (2018) A comprehensive web tool for toehold switch design. Bioinformatics, 34, 2862–2864. https://doi.org/10.1093/bioinformatics/bty216 | Toeholder: a Software for Automated Design and In Silico Validation of Toehold Riboswitches | Angel F. Cisneros, François D. Rouleau, Carla Bautista, Pascale Lemieux, Nathan Dumont-Leblond | <p>Abstract: Synthetic biology aims to engineer biological circuits, which often involve gene expression. A particularly promising group of regulatory elements are riboswitches because of their versatility with respect to their targets, but e... | | Bioinformatics | Sahar Melamed | 2022-02-16 14:40:13 | ||
08 Apr 2022

POSTPRINT
Phylogenetics in the Genomic Era“Phylogenetics in the Genomic Era” brings together experts in the field to present a comprehensive synthesisRecommended by Robert Waterhouse and Karen MeusemannE-book: Phylogenetics in the Genomic Era (Scornavacca et al. 2021) This book was not peer-reviewed by PCI Genomics. It has undergone an internal review by the editors. Accurate reconstructions of the relationships amongst species and the genes encoded in their genomes are an essential foundation for almost all evolutionary inferences emerging from downstream analyses. Molecular phylogenetics has developed as a field over many decades to build suites of models and methods to reconstruct reliable trees that explain, support, or refute such inferences. The genomic era has brought new challenges and opportunities to the field, opening up new areas of research and algorithm development to take advantage of the accumulating large-scale data. Such ‘big-data’ phylogenetics has come to be known as phylogenomics, which broadly aims to connect molecular and evolutionary biology research to address questions centred on relationships amongst taxa, mechanisms of molecular evolution, and the biological functions of genes and other genomic elements. This book brings together experts in the field to present a comprehensive synthesis of Phylogenetics in the Genomic Era, covering key conceptual and methodological aspects of how to build accurate phylogenies and how to apply them in molecular and evolutionary research. The paragraphs below briefly summarise the five constituent parts of the book, highlighting the key concepts, methods, and applications that each part addresses. Being organised in an accessible style, while presenting details to provide depth where necessary, and including guides describing real-world examples of major phylogenomic tools, this collection represents an invaluable resource, particularly for students and newcomers to the field of phylogenomics. Part 1: Phylogenetic analyses in the genomic era Modelling how sequences evolve is a fundamental cornerstone of phylogenetic reconstructions. This part of the book introduces the reader to phylogenetic inference methods and algorithmic optimisations in the contexts of Markov, Maximum Likelihood, and Bayesian models of sequence evolution. The main concepts and theoretical considerations are mapped out for probabilistic Markov models, efficient tree building with Maximum Likelihood methods, and the flexibility and robustness of Bayesian approaches. These are supported with practical examples of phylogenomic applications using the popular tools RAxML and PhyloBayes. By considering theoretical, algorithmic, and practical aspects, these chapters provide readers with a holistic overview of the challenges and recent advances in developing scalable phylogenetic analyses in the genomic era. Part 2: Data quality, model adequacy This part focuses on the importance of considering the appropriateness of the evolutionary models used and the accuracy of the underlying molecular and genomic data. Both these aspects can profoundly affect the results when applying current phylogenomic methods to make inferences about complex biological and evolutionary processes. A clear example is presented for methods for building multiple sequence alignments and subsequent filtering approaches that can greatly impact phylogeny inference. The importance of error detection in (meta)barcode sequencing data is also highlighted, with solutions offered by the MACSE_BARCODE pipeline for accurate taxonomic assignments. Orthology datasets are essential markers for phylogenomic inferences, but the overview of concepts and methods presented shows that they too face challenges with respect to model selection and data quality. Finally, an innovative approach using ancestral gene order reconstructions provides new perspectives on how to assess gene tree accuracy for phylogenomic analyses. By emphasising through examples the importance of using appropriate evolutionary models and assessing input data quality, these chapters alert readers to key limitations that the field as a whole strives to address. Part 3: Resolving phylogenomic conflicts Conflicting phylogenetic signals are commonplace and may derive from statistical or systematic bias. This part of the book addresses possible causes of conflict, discordance between gene trees and species trees and how processes that lead to such conflicts can be described by phylogenetic models. Furthermore, it provides an overview of various models and methods with examples in phylogenomics including their pros and cons. Outlined in detail is the multispecies coalescent model (MSC) and its applications in phylogenomics. An interesting aspect is that different phylogenetic signals leading to conflict are in fact a key source of information rather than a problem that can – and should – be used to point to events like introgression or hybridisation, highlighting possible future trends in this research area. Last but not least, this part of the book also addresses inferring species trees by concatenating single multiple sequence alignments (gene alignments) versus inferring the species tree based on ensembles of single gene trees pointing out advantages and disadvantages of both approaches. As an important take home message from these chapters, it is recommended to be flexible and identify the most appropriate approach for each dataset to be analysed since this may tremendously differ depending on the dataset, setting, taxa, and phylogenetic level addressed by the researcher. Part 4: Functional evolutionary genomics In this part of the book the focus shifts to functional considerations of phylogenomics approaches both in terms of molecular evolution and adaptation and with respect to gene expression. The utility of multi-species analysis is clearly presented in the context of annotating functional genomic elements through quantifying evolutionary constraint and protein-coding potential. An historical perspective on characterising rates of change highlights how phylogenomic datasets help to understand the modes of molecular evolution across the genome, over time, and between lineages. These are contextualised with respect to the specific aim of detecting signatures of adaptation from protein-coding DNA alignments using the example of the MutSelDP-ω∗ model. This is extended with the presentation of the generally rare case of adaptive sequence convergence, where consideration of appropriate models and knowledge of gene functions and phenotypic effects are needed. Constrained or relaxed, selection pressures on sequence or copy-number affect genomic elements in different ways, making the very concept of function difficult to pin down despite it being fundamental to relate the genome to the phenotype and organismal fitness. Here gene expression provides a measurable intermediate, for which the Expression Comparison tool from the Bgee suite allows exploration of expression patterns across multiple animal species taking into account anatomical homology. Overall, phylogenomics applications in functional evolutionary genomics build on a rich theoretical history from molecular analyses where integration with knowledge of gene functions is challenging but critical. Part 5: Phylogenomic applications Rather than attempting to review the full extent of applications linked to phylogenomics, this part of the book focuses on providing detailed specific insights into selected examples and methods concerning i) estimating divergence times, and ii) species delimitation in the era of ‘omics’ data. With respect to estimating divergence times, an exemplary overview is provided for fossil data recovered from geological records, either using fossil data as calibration points with an extant-species-inferred phylogeny, or using a fossilised birth-death process as a mechanistic model that accounts for lineage diversification. Included is a tutorial for a joint approach to infer phylogenies and estimate divergence times using the RevBayes software with various models implemented for different applications and datasets incorporating molecular and morphological data. An interesting excursion is outlined focusing on timescale estimates with respect to viral evolution introducing BEAGLE, a high-performance likelihood-calculation platform that can be used on multi-core systems. As a second major subject, species delimitation is addressed since currently the increasing amount of available genomic data enables extensive inferences, for instance about the degree of genetic isolation among species and ancient and recent introgression events. Describing the history of molecular species delimitation up to the current genomic era and presenting widely used computational methods incorporating single- and multi-locus genomic data, pros and cons are addressed. Finally, a proposal for a new method for delimiting species based on empirical criteria is outlined. In the closing chapter of this part of the book, BPP (Bayesian Markov chain Monte Carlo program) for analysing multi-locus sequence data under the multispecies coalescent (MSC) model with and without introgression is introduced, including a tutorial. These examples together provide accessible details on key conceptual and methodological aspects related to the application of phylogenetics in the genomic era. References Scornavacca C, Delsuc F, Galtier N (2021) Phylogenetics in the Genomic Era. https://hal.inria.fr/PGE/ | Phylogenetics in the Genomic Era | Céline Scornavacca, Frédéric Delsuc, Nicolas Galtier | <p style="text-align: justify;">Molecular phylogenetics was born in the middle of the 20th century, when the advent of protein and DNA sequencing offered a novel way to study the evolutionary relationships between living organisms. The first 50 ye... | | Bacteria and archaea, Bioinformatics, Evolutionary genomics, Functional genomics, Fungi, Plants, Population genomics, Vertebrates, Viruses and transposable elements | Robert Waterhouse | 2022-03-15 17:43:52 | ||
24 Feb 2023
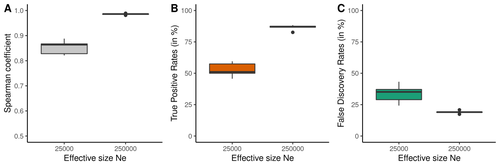
Performance and limitations of linkage-disequilibrium-based methods for inferring the genomic landscape of recombination and detecting hotspots: a simulation studyHow to interpret the inference of recombination landscapes on methods based on linkage disequilibrium?Recommended by Sebastian Ernesto Ramos-Onsins based on reviews by 2 anonymous reviewers based on reviews by 2 anonymous reviewers
Data interpretation depends on previously established and validated tools, designed for a specific type of data. These methods, however, are usually based on simple models with validity subject to a set of theoretical parameterized conditions and data types. Accordingly, the tool developers provide the potential users with guidelines for data interpretations within the tools’ limitation. Nevertheless, once the methodology is accepted by the community, it is employed in a large variety of empirical studies outside of the method’s original scope or that typically depart from the standard models used for its design, thus potentially leading to the wrong interpretation of the results. Numerous empirical studies inferred recombination rates across genomes, detecting hotspots of recombination and comparing related species (e.g., Shanfelter et al. 2019, Spence and Song 2019). These studies used indirect methodologies based on the signals that recombination left in the genome, such as linkage disequilibrium and the patterns of haplotype segregation (e.g.,Chan et al. 2012). The conclusions from these analyses have been used, for example, to interpret the evolution of the chromosomal structure or the evolution of recombination among closely related species. Indirect methods have the advantage of collecting a large quantity of recombination events, and thus have a better resolution than direct methods (which only detect the few recombination events occurring at that time). On the other hand, indirect methods are affected by many different evolutionary events, such as demographic changes and selection. Indeed, the inference of recombination levels across the genome has not been studied accurately in non-standard conditions. Linkage disequilibrium is affected by several factors that can modify the recombination inference, such as demographic history, events of selection, population size, and mutation rate, but is also related to the size of the studied sample, and other technical parameters defined for each specific methodology. Raynaud et al (2023) analyzed the reliability of the recombination rate inference when considering the violation of several standard assumptions (evolutionary and methodological) in one of the most popular families of methods based on LDhat (McVean et al. 2004), specifically its improved version, LDhelmet (Chan et al. 2012). These methods cover around 70 % of the studies that infer recombination rates. The authors used recombination maps, obtained from empirical studies on humans, and included hotspots, to perform a detailed simulation study of the capacity of this methodology to correctly infer the pattern of recombination and the location of these hotspots. Correlations between the real, and inferred values from simulations were obtained, as well as several rates, such as the true positive and false discovery rate to detect hotspots. The authors of this work send a message of caution to researchers that are applying this methodology to interpret data from the inference of recombination landscapes and the location of hotspots. The inference of recombination landscapes and hotspots can differ considerably even in standard model conditions. In addition, demographic processes, like bottleneck or admixture, but also the level of population size and mutation rates, can substantially affect the estimation accuracy of the level of recombination and the location of hotspots. Indeed, the inference of the location of hotspots in simulated data with the same landscape, can be very imprecise when standard assumptions are violated or not considered. These effects may lead to incorrect interpretations, for example about the conservation of recombination maps between closely related species. Finally, Raynaud et al (2023) included a useful guide with advice on how to obtain accurate recombination estimations with methods based on linkage disequilibrium, also emphasizing the limitations of such approaches. REFERENCES Chan AH, Jenkins PA, Song YS (2012) Genome-Wide Fine-Scale Recombination Rate Variation in Drosophila melanogaster. PLOS Genetics, 8, e1003090. https://doi.org/10.1371/journal.pgen.1003090 McVean GAT, Myers SR, Hunt S, Deloukas P, Bentley DR, Donnelly P (2004) The Fine-Scale Structure of Recombination Rate Variation in the Human Genome. Science, 304, 581–584. https://doi.org/10.1126/science.1092500 Raynaud M, Gagnaire P-A, Galtier N (2023) Performance and limitations of linkage-disequilibrium-based methods for inferring the genomic landscape of recombination and detecting hotspots: a simulation study. bioRxiv, 2022.03.30.486352, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.03.30.486352 Spence JP, Song YS (2019) Inference and analysis of population-specific fine-scale recombination maps across 26 diverse human populations. Science Advances, 5, eaaw9206. https://doi.org/10.1126/sciadv.aaw9206 | Performance and limitations of linkage-disequilibrium-based methods for inferring the genomic landscape of recombination and detecting hotspots: a simulation study | Marie Raynaud, Pierre-Alexandre Gagnaire, Nicolas Galtier | <p style="text-align: justify;">Knowledge of recombination rate variation along the genome provides important insights into genome and phenotypic evolution. Population genomic approaches offer an attractive way to infer the population-scaled recom... | | Bioinformatics, Evolutionary genomics, Population genomics | Sebastian Ernesto Ramos-Onsins | 2022-04-05 14:59:14 | ||
23 Aug 2022

A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomicsGoat ancient DNA analysis unveils a new lineage that may have hybridized with domestic goatsRecommended by Laura Botigué based on reviews by Torsten Günther and 1 anonymous reviewerThe genomic analysis of ancient remains has revolutionized the study of the past over the last decade. On top of the discoveries related to human evolution, plant and animal archaeogenomics has been used to gain new insights into the domestication process and the dispersal of domestic forms. In this study, Daly and colleagues analyse the genomic data from seven goat specimens from the Epipalaeolithic recovered from the Direkli Cave in the Taurus Mountains in southern Turkey. They also generate new genomic data from Capra lineages across the phylogeny, contributing to the availability of genomic resources for this genus. Analysis of the ancient remains is compared to modern genomic variability and sheds light on the complexity of the Tur wild Capra lineages and their relationship with domestic goats and their wild ancestors. Authors find that during the Late Pleistocene in the Taurus Mountains wild goats from the Tur lineage, today restricted to the Caucasus region, were not rare and cohabited with Bezoar, the wild goats that are the ancestors of domestic goats. They identify the Direkli Cave specimens as a lineage separate from the A modified D statistic, Dex, is developed to examine the contribution of the ancient Tur lineage in domestic goats through time and space. Dex measures the relative degree of allele sharing, derived specifically in a selected genome or group of genomes, and may have some utility in genera with complex admixture histories or admixture from ghost lineages. Results confirm that Neolithic European goat had an excess of allele sharing with this ancient Tur lineage, something that is absent in contemporary goats eastwards or in modern goats. Interspecific gene flow is not uncommon among mammals, but the case of Capra has the additional motivation of understanding the origins of the domestic species. This work uncovers an ancient Tur lineage that is different from the modern ones and is additionally found in another geographic area. Furthermore, evidence shows that this ancient lineage exhibits substantial amounts of allele sharing with the wild ancestor of the domestic goat, but also with the Neolithic Eurasian domestic goats, highlighting the complexity of the domestication process. This work has also important implications in understanding the effect of over-hunting and habitat disruption during the Anthropocene on the evolution of the Capra genus. The availability of more ancient specimens and better coverage of the modern genomic variability can help quantifying the lineages that went lost and identify the causes of their extinction. This work is limited by the current availability of whole genomes from modern Capra specimens, but pieces of evidence as well that an effort is needed to obtain more genomic data from ancient goats from different geographic ranges to determine to what extent these lineages contributed to goat domestication. References Daly KG, Arbuckle BS, Rossi C, Mattiangeli V, Lawlor PA, Mashkour M, Sauer E, Lesur J, Atici L, Cevdet CM and Bradley DG (2022) A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomics. bioRxiv, 2022.04.08.487619, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.08.487619 | A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomics | Kevin G. Daly, Benjamin S. Arbuckle, Conor Rossi, Valeria Mattiangeli, Phoebe A. Lawlor, Marjan Mashkour, Eberhard Sauer, Joséphine Lesur, Levent Atici, Cevdet Merih Erek, Daniel G. Bradley | <p>Direkli Cave, located in the Taurus Mountains of southern Turkey, was occupied by Late Epipaleolithic hunters-gatherers for the seasonal hunting and processing of game including large numbers of wild goats. We report genomic data from new and p... | | Evolutionary genomics, Population genomics, Vertebrates | Laura Botigué | 2022-04-15 12:05:47 | ||
13 Jul 2022
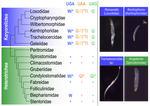
Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codonsAn accident frozen in time: the ambiguous stop/sense genetic code of karyorelict ciliatesRecommended by Iker Irisarri based on reviews by Vittorio Boscaro and 2 anonymous reviewers
Several variations of the “universal” genetic code are known. Among the most striking are those where a codon can either encode for an amino acid or a stop signal depending on the context. Such ambiguous codes are known to have evolved in eukaryotes multiple times independently, particularly in ciliates – eight different codes have so far been discovered (1). We generally view such genetic codes are rare ‘variants’ of the standard code restricted to single species or strains, but this might as well reflect a lack of study of closely related species. In this study, Seah and co-authors (2) explore the possibility of codon reassignment in karyorelict ciliates closely related to Parduczia sp., which has been shown to contain an ambiguous genetic code (1). Here, single-cell transcriptomics are used, along with similar available data, to explore the possibility of codon reassignment across the diversity of Karyorelictea (four out of the six recognized families). Codon reassignments were inferred from their frequencies within conserved Pfam (3) protein domains, whereas stop codons were inferred from full-length transcripts with intact 3’-UTRs. Results show the reassignment of UAA and UAG stop codons to code for glutamine (Q) and the reassignment of the UGA stop codon into tryptophan (W). This occurs only within the coding sequences, whereas the end of transcription is marked by UGA as the main stop codon, and to a lesser extent by UAA. In agreement with a previous model proposed that explains the functioning of ambiguous codes (1,4), the authors observe a depletion of in-frame UGAs before the UGA codon that indicates the stop, thus avoiding premature termination of transcription. The inferred codon reassignments occur in all studied karyorelicts, including the previously studied Parduczia sp. Despite the overall clear picture, some questions remain. Data for two out of six main karyorelict lineages are so far absent and the available data for Cryptopharyngidae was inconclusive; the phylogenetic affinities of Cryptopharyngidae have also been questioned (5). This indicates the need for further study of this interesting group of organisms. As nicely discussed by the authors, experimental evidence could further strengthen the conclusions of this paper, including ribosome profiling, mass spectrometry – as done for Condylostoma (1) – or even direct genetic manipulation. The uniformity of the ambiguous genetic code across karyorelicts might at first seem dull, but when viewed in a phylogenetic context character distribution strongly suggest that this genetic code has an ancient origin in the karyorelict ancestor ~455 Ma in the Proterozoic (6). This ambiguous code is also not a rarity of some obscure species, but it is shared by ciliates that are very diverse and ecologically important. The origin of the karyorelict code is also intriguing. Adaptive arguments suggest that it could confer robustness to mutations causing premature stop codons. However, we lack evidence for ambiguous codes being linked to specific habitats of lifestyles that could account for it. Instead, the authors favor the neutral view of an ancient “frozen accident”, fixed stochastically simply because it did not pose a significant selective disadvantage. Once a stop codon is reassigned to an amino acid, it is increasingly difficult to revert this without the deleterious effect of prematurely terminating translation. At the end, the origin of the genetic code itself is thought to be a frozen accident too (7). References 1. Swart EC, Serra V, Petroni G, Nowacki M. Genetic codes with no dedicated stop codon: Context-dependent translation termination. Cell 2016;166: 691–702. https://doi.org/10.1016/j.cell.2016.06.020 2. Seah BKB, Singh A, Swart EC (2022) Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons. bioRxiv, 2022.04.12.488043. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.12.488043 3. Mistry J, Chuguransky S, Williams L, Qureshi M, Salazar GA, Sonnhammer ELL, Tosatto SCE, Paladin L, Raj S, Richardson LJ, Finn RD, Bateman A. Pfam: The protein families database in 2021, Nuc Acids Res 2020;49: D412-D419. https://doi.org/10.1093/nar/gkaa913 4. Alkalaeva E, Mikhailova T. Reassigning stop codons via translation termination: How a few eukaryotes broke the dogma. Bioessays. 2017;39. https://doi.org/10.1002/bies.201600213 5. Xu Y, Li J, Song W, Warren A. Phylogeny and establishment of a new ciliate family, Wilbertomorphidae fam. nov. (Ciliophora, Karyorelictea), a highly specialized taxon represented by Wilbertomorpha colpoda gen. nov., spec. nov. J Eukaryot Microbiol. 2013;60: 480–489. https://doi.org/10.1111/jeu.12055 6. Fernandes NM, Schrago CG. A multigene timescale and diversification dynamics of Ciliophora evolution. Mol Phylogenet Evol. 2019;139: 106521. https://doi.org/10.1016/j.ympev.2019.106521 7. Crick FH. The origin of the genetic code. J Mol Biol. 1968;38: 367–379. https://doi.org/10.1016/0022-2836(68)90392-6 | Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons | Brandon Kwee Boon Seah, Aditi Singh, Estienne Carl Swart | <p style="text-align: justify;">In ambiguous stop/sense genetic codes, the stop codon(s) not only terminate translation but can also encode amino acids. Such codes have evolved at least four times in eukaryotes, twice among ciliates (<em>Condylost... | | Bioinformatics, Evolutionary genomics | Iker Irisarri | 2022-05-02 11:06:10 | ||
07 Feb 2023
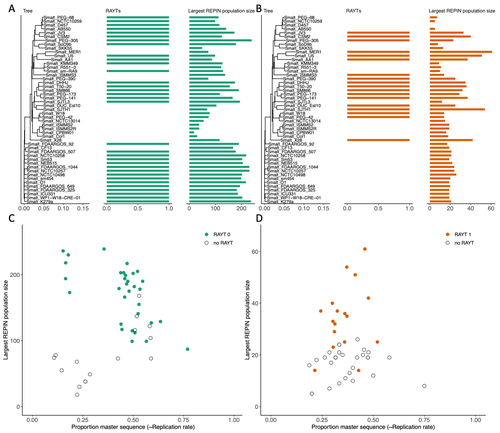
RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomesA workflow for studying enigmatic non-autonomous transposable elements across bacteriaRecommended by Gavin Douglas based on reviews by Sophie Abby and 1 anonymous reviewer
Repetitive extragenic palindromic sequences (REPs) are common repetitive elements in bacterial genomes (Gilson et al., 1984; Stern et al., 1984). In 2011, Bertels and Rainey identified that REPs are overrepresented in pairs of inverted repeats, which likely form hairpin structures, that they referred to as “REP doublets forming hairpins” (REPINs). Based on bioinformatics analyses, they argued that REPINs are likely selfish elements that evolved from REPs flanking particular transposes (Bertels and Rainey, 2011). These transposases, so-called REP-associated tyrosine transposases (RAYTs), were known to be highly associated with the REP content in a genome and to have characteristic upstream and downstream flanking REPs (Nunvar et al., 2010). The flanking REPs likely enable RAYT transposition, and their horizontal replication is physically linked to this process. In contrast, Bertels and Rainey hypothesized that REPINs are selfish elements that are highly replicated due to the similarity in arrangement to these RAYT-flanking REPs, but independent of RAYT transposition and generally with no impact on bacterial fitness (Bertels and Rainey, 2011). This last point was especially contentious, as REPINs are highly conserved within species (Bertels and Rainey, 2023), which is unusual for non-beneficial bacterial DNA (Mira et al., 2001). Bertels and Rainey have since refined their argument to be that REPINs must provide benefits to host cells, but that there are nonetheless signatures of intragenomic conflict in genomes associated with these elements (Bertels and Rainey, 2023). These signatures reflect the divergent levels of selections driving REPIN distribution: selection at the level of each DNA element and selection on each individual bacterium. I found this observation particularly interesting as I and my colleague recently argued that these divergent levels of selection, and the interaction between them, is key to understanding bacterial pangenome diversity (Douglas and Shapiro, 2021). REPINs could be an excellent system for investigating these levels of selection across bacteria more generally. The problem is that REPINs have not been widely characterized in bacterial genomes, partially because no bioinformatic workflow has been available for this purpose. To address this problem, Fortmann-Grote et al. (2023) developed RAREFAN, which is a web server for identifying RAYTs and associated REPINs in a set of input genomes. The authors showcase their tool by applying it to 49 Stenotrophomonas maltophilia genomes and providing examples of how to identify and assess RAYT-REPIN hits. The workflow requires several manual steps, but nonetheless represents a straightforward and standardized approach. Overall, this workflow should enable RAYTs and REPINs to be identified across diverse bacterial species, which will facilitate further investigation into the mechanisms driving their maintenance and spread. References Bertels F, Rainey PB (2023) Ancient Darwinian replicators nested within eubacterial genomes. BioEssays, 45, 2200085. https://doi.org/10.1002/bies.202200085 Bertels F, Rainey PB (2011) Within-Genome Evolution of REPINs: a New Family of Miniature Mobile DNA in Bacteria. PLOS Genetics, 7, e1002132. https://doi.org/10.1371/journal.pgen.1002132 Douglas GM, Shapiro BJ (2021) Genic Selection Within Prokaryotic Pangenomes. Genome Biology and Evolution, 13, evab234. https://doi.org/10.1093/gbe/evab234 Fortmann-Grote C, Irmer J von, Bertels F (2023) RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes. bioRxiv, 2022.05.22.493013, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.05.22.493013 Gilson E, Clément J m., Brutlag D, Hofnung M (1984) A family of dispersed repetitive extragenic palindromic DNA sequences in E. coli. The EMBO Journal, 3, 1417–1421. https://doi.org/10.1002/j.1460-2075.1984.tb01986.x Mira A, Ochman H, Moran NA (2001) Deletional bias and the evolution of bacterial genomes. Trends in Genetics, 17, 589–596. https://doi.org/10.1016/S0168-9525(01)02447-7 Nunvar J, Huckova T, Licha I (2010) Identification and characterization of repetitive extragenic palindromes (REP)-associated tyrosine transposases: implications for REP evolution and dynamics in bacterial genomes. BMC Genomics, 11, 44. https://doi.org/10.1186/1471-2164-11-44 Stern MJ, Ames GF-L, Smith NH, Clare Robinson E, Higgins CF (1984) Repetitive extragenic palindromic sequences: A major component of the bacterial genome. Cell, 37, 1015–1026. https://doi.org/10.1016/0092-8674(84)90436-7 | RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes | Frederic Bertels, Julia von Irmer, Carsten Fortmann-Grote | <p style="text-align: justify;">Compared to eukaryotes, repetitive sequences are rare in bacterial genomes and usually do not persist for long. Yet, there is at least one class of persistent prokaryotic mobile genetic elements: REPINs. REPINs are ... | | Bacteria and archaea, Bioinformatics, Evolutionary genomics, Viruses and transposable elements | Gavin Douglas | 2022-06-07 08:21:34 | ||
15 Sep 2022
EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotesEukProt enables reproducible Eukaryota-wide protein sequence analysesRecommended by Gavin Douglas based on reviews by 2 anonymous reviewers
Comparative genomics is a general approach for understanding how genomes differ, which can be considered from many angles. For instance, this approach can delineate how gene content varies across organisms, which can lead to novel hypotheses regarding what those organisms do. It also enables investigations into the sequence-level divergence of orthologous DNA, which can provide insight into how evolutionary forces differentially shape genome content and structure across lineages. Burki F, Roger AJ, Brown MW, Simpson AGB (2020) The New Tree of Eukaryotes. Trends in Ecology & Evolution, 35, 43–55. https://doi.org/10.1016/j.tree.2019.08.008 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE, Bouwman J, Brookes AJ, Clark T, Crosas M, Dillo I, Dumon O, Edmunds S, Evelo CT, Finkers R, Gonzalez-Beltran A, Gray AJG, Groth P, Goble C, Grethe JS, Heringa J, ’t Hoen PAC, Hooft R, Kuhn T, Kok R, Kok J, Lusher SJ, Martone ME, Mons A, Packer AL, Persson B, Rocca-Serra P, Roos M, van Schaik R, Sansone S-A, Schultes E, Sengstag T, Slater T, Strawn G, Swertz MA, Thompson M, van der Lei J, van Mulligen E, Velterop J, Waagmeester A, Wittenburg P, Wolstencroft K, Zhao J, Mons B (2016) The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18 | EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes | Daniel J. Richter, Cédric Berney, Jürgen F. H. Strassert, Yu-Ping Poh, Emily K. Herman, Sergio A. Muñoz-Gómez, Jeremy G. Wideman, Fabien Burki, Colomban de Vargas | <p style="text-align: justify;">EukProt is a database of published and publicly available predicted protein sets selected to represent the breadth of eukaryotic diversity, currently including 993 species from all major supergroups as well as orpha... | | Bioinformatics, Evolutionary genomics | Gavin Douglas | 2022-06-08 14:19:28 | ||
23 Sep 2022
MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studiesMATEdb: a new phylogenomic-driven database for MetazoaRecommended by Samuel Abalde based on reviews by 2 anonymous reviewers
The development (and standardization) of high-throughput sequencing techniques has revolutionized evolutionary biology, to the point that we almost see as normal fine-detail studies of genome architecture evolution (Robert et al., 2022), adaptation to new habitats (Rahi et al., 2019), or the development of key evolutionary novelties (Hilgers et al., 2018), to name three examples. One of the fields that has benefited the most is phylogenomics, i.e. the use of genome-wide data for inferring the evolutionary relationships among organisms. Dealing with such amount of data, however, has come with important analytical and computational challenges. Likewise, although the steady generation of genomic data from virtually any organism opens exciting opportunities for comparative analyses, it also creates a sort of “information fog”, where it is hard to find the most appropriate and/or the higher quality data. I have personally experienced this not so long ago, when I had to spend several weeks selecting the most complete transcriptomes from several phyla, moving back and forth between the NCBI SRA repository and the relevant literature. In an attempt to deal with this issue, some research labs have committed their time and resources to the generation of taxa- and topic-specific databases (Lathe et al., 2008), such as MolluscDB (Liu et al., 2021), focused on mollusk genomics, or EukProt (Richter et al., 2022), a protein repository representing the diversity of eukaryotes. A new database that promises to become an important resource in the near future is MATEdb (Fernández et al., 2022), a repository of high-quality genomic data from Metazoa. MATEdb has been developed from publicly available and newly generated transcriptomes and genomes, prioritizing quality over quantity. Upon download, the user has access to both raw data and the related datasets: assemblies, several quality metrics, the set of inferred protein-coding genes, and their annotation. Although it is clear to me that this repository has been created with phylogenomic analyses in mind, I see how it could be generalized to other related problems such as analyses of gene content or evolution of specific gene families. In my opinion, the main strengths of MATEdb are threefold:
On a negative note, I see two main drawbacks. First, as of today (September 16th, 2022) this database is in an early stage and it still needs to incorporate a lot of animal groups. This has been discussed during the revision process and the authors are already working on it, so it is only a matter of time until all major taxa are represented. Second, there is a scalability issue. In its current format it is not possible to select the taxa of interest and the full database has to be downloaded, which will become more and more difficult as it grows. Nonetheless, with the appropriate resources it would be easy to find a better solution. There are plenty of examples that could serve as inspiration, so I hope this does not become a big problem in the future. Altogether, I and the researchers that participated in the revision process believe that MATEdb has the potential to become an important and valuable addition to the metazoan phylogenomics community. Personally, I wish it was available just a few months ago, it would have saved me so much time. References Fernández R, Tonzo V, Guerrero CS, Lozano-Fernandez J, Martínez-Redondo GI, Balart-García P, Aristide L, Eleftheriadi K, Vargas-Chávez C (2022) MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studies. bioRxiv, 2022.07.18.500182, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.07.18.500182 Hilgers L, Hartmann S, Hofreiter M, von Rintelen T (2018) Novel Genes, Ancient Genes, and Gene Co-Option Contributed to the Genetic Basis of the Radula, a Molluscan Innovation. Molecular Biology and Evolution, 35, 1638–1652. https://doi.org/10.1093/molbev/msy052 Lathe W, Williams J, Mangan M, Karolchik, D (2008). Genomic data resources: challenges and promises. Nature Education, 1(3), 2. Liu F, Li Y, Yu H, Zhang L, Hu J, Bao Z, Wang S (2021) MolluscDB: an integrated functional and evolutionary genomics database for the hyper-diverse animal phylum Mollusca. Nucleic Acids Research, 49, D988–D997. https://doi.org/10.1093/nar/gkaa918 Rahi ML, Mather PB, Ezaz T, Hurwood DA (2019) The Molecular Basis of Freshwater Adaptation in Prawns: Insights from Comparative Transcriptomics of Three Macrobrachium Species. Genome Biology and Evolution, 11, 1002–1018. https://doi.org/10.1093/gbe/evz045 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Robert NSM, Sarigol F, Zimmermann B, Meyer A, Voolstra CR, Simakov O (2022) Emergence of distinct syntenic density regimes is associated with early metazoan genomic transitions. BMC Genomics, 23, 143. https://doi.org/10.1186/s12864-022-08304-2 | MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studies | Rosa Fernandez, Vanina Tonzo, Carolina Simon Guerrero, Jesus Lozano-Fernandez, Gemma I Martinez-Redondo, Pau Balart-Garcia, Leandro Aristide, Klara Eleftheriadi, Carlos Vargas-Chavez | <p style="text-align: justify;">With the advent of high throughput sequencing, the amount of genomic data available for animals (Metazoa) species has bloomed over the last decade, especially from transcriptomes due to lower sequencing costs and ea... | | Bioinformatics, Evolutionary genomics, Functional genomics | Samuel Abalde | 2022-07-20 07:30:39 |




