
Latest recommendations

| Id | Title | Authors | Abstract | Picture▼ | Thematic fields | Recommender | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
05 May 2021
A primer and discussion on DNA-based microbiome data and related bioinformatics analysesA hitchhiker’s guide to DNA-based microbiome analysisRecommended by Danny Ionescu based on reviews by Nicolas Pollet, Rafael Cuadrat and 1 anonymous reviewer based on reviews by Nicolas Pollet, Rafael Cuadrat and 1 anonymous reviewer
In the last two decades, microbial research in its different fields has been increasingly focusing on microbiome studies. These are defined as studies of complete assemblages of microorganisms in given environments and have been benefiting from increases in sequencing length, quality, and yield, coupled with ever-dropping prices per sequenced nucleotide. Alongside localized microbiome studies, several global collaborative efforts have emerged, including the Human Microbiome Project [1], the Earth Microbiome Project [2], the Extreme Microbiome Project, and MetaSUB [3]. Coupled with the development of sequencing technologies and the ever-increasing amount of data output, multiple standalone or online bioinformatic tools have been designed to analyze these data. Often these tools have been focusing on either of two main tasks: 1) Community analysis, providing information on the organisms present in the microbiome, or 2) Functionality, in the case of shotgun metagenomic data, providing information on the metabolic potential of the microbiome. Bridging between the two types of data, often extracted from the same dataset, is typically a daunting task that has been addressed by a handful of tools only. The extent of tools and approaches to analyze microbiome data is great and may be overwhelming to researchers new to microbiome or bioinformatic studies. In their paper “A primer and discussion on DNA-based microbiome data and related bioinformatics analyses”, Douglas and Langille [4] guide us through the different sequencing approaches useful for microbiome studies. alongside their advantages and caveats and a selection of tools to analyze these data, coupled with examples from their own field of research. Standing out in their primer-style review is the emphasis on the coupling between taxonomic/phylogenetic identification of the organisms and their functionality. This type of analysis, though highly important to understand the role of different microorganisms in an environment as well as to identify potential functional redundancy, is often not conducted. For this, the authors identify two approaches. The first, using shotgun metagenomics, has higher chances of attributing a function to the correct taxon. The second, using amplicon sequencing of marker genes, allows for a deeper coverage of the microbiome at a lower cost, and extrapolates the amplicon data to close relatives with a sequenced genome. As clearly stated, this approach makes the leap between taxonomy and functionality and has been shown to be erroneous in cases where the core genome of the bacterial genus or family does not encompass the functional diversity of the different included species. This practice was already common before the genomic era, but its accuracy is improving thanks to the increasing availability of sequenced reference genomes from cultures, environmentally picked single cells or metagenome-assembled genome. In addition to their description of standalone tools useful for linking taxonomy and functionality, one should mention the existence of online tools that may appeal to researchers who do not have access to adequate bioinformatics infrastructure. Among these are the Integrated Microbial Genomes and Microbiomes (IMG) from the Joint Genome Institute [5], KBase [6] and MG-RAST [7]. A second important point arising from this review is the need for standardization in microbiome data analyses and the complexity of achieving this. As Douglas and Langille [4] state, this has been previously addressed, highlighting the variability in results obtained with different tools. It is often the case that papers describing new bioinformatic tools display their superiority relative to existing alternatives, potentially misleading newcomers to the field that the newest tool is the best and only one to be used. This is often not the case, and while benchmarking against well-defined datasets serves as a powerful testing tool, “real-life” samples are often not comparable. Thus, as done here, future primer-like reviews should highlight possible cross-field caveats, encouraging researchers to employ and test several approaches and validate their results whenever possible. In summary, Douglas and Langille [4] offer both the novice and experienced researcher a detailed guide along the paths of microbiome data analysis, accompanied by informative background information, suggested tools with which analyses can be started, and an insightful view on where the field should be heading. References [1] Turnbaugh PJ, Ley RE, Hamady M, Fraser-Liggett CM, Knight R, Gordon JI (2007) The Human Microbiome Project. Nature, 449, 804–810. https://doi.org/10.1038/nature06244 [2] Gilbert JA, Jansson JK, Knight R (2014) The Earth Microbiome project: successes and aspirations. BMC Biology, 12, 69. https://doi.org/10.1186/s12915-014-0069-1 [3] Mason C, Afshinnekoo E, Ahsannudin S, Ghedin E, Read T, Fraser C, Dudley J, Hernandez M, Bowler C, Stolovitzky G, Chernonetz A, Gray A, Darling A, Burke C, Łabaj PP, Graf A, Noushmehr H, Moraes s., Dias-Neto E, Ugalde J, Guo Y, Zhou Y, Xie Z, Zheng D, Zhou H, Shi L, Zhu S, Tang A, Ivanković T, Siam R, Rascovan N, Richard H, Lafontaine I, Baron C, Nedunuri N, Prithiviraj B, Hyat S, Mehr S, Banihashemi K, Segata N, Suzuki H, Alpuche Aranda CM, Martinez J, Christopher Dada A, Osuolale O, Oguntoyinbo F, Dybwad M, Oliveira M, Fernandes A, Oliveira M, Fernandes A, Chatziefthimiou AD, Chaker S, Alexeev D, Chuvelev D, Kurilshikov A, Schuster S, Siwo GH, Jang S, Seo SC, Hwang SH, Ossowski S, Bezdan D, Udekwu K, Udekwu K, Lungjdahl PO, Nikolayeva O, Sezerman U, Kelly F, Metrustry S, Elhaik E, Gonnet G, Schriml L, Mongodin E, Huttenhower C, Gilbert J, Hernandez M, Vayndorf E, Blaser M, Schadt E, Eisen J, Beitel C, Hirschberg D, Schriml L, Mongodin E, The MetaSUB International Consortium (2016) The Metagenomics and Metadesign of the Subways and Urban Biomes (MetaSUB) International Consortium inaugural meeting report. Microbiome, 4, 24. https://doi.org/10.1186/s40168-016-0168-z [4] Douglas GM, Langille MGI (2021) A primer and discussion on DNA-based microbiome data and related bioinformatics analyses. OSF Preprints, ver. 4 peer-reviewed and recommended by Peer Community In Genomics. https://doi.org/10.31219/osf.io/3dybg [5] Chen I-MA, Markowitz VM, Chu K, Palaniappan K, Szeto E, Pillay M, Ratner A, Huang J, Andersen E, Huntemann M, Varghese N, Hadjithomas M, Tennessen K, Nielsen T, Ivanova NN, Kyrpides NC (2017) IMG/M: integrated genome and metagenome comparative data analysis system. Nucleic Acids Research, 45, D507–D516. https://doi.org/10.1093/nar/gkw929 [6] Arkin AP, Cottingham RW, Henry CS, Harris NL, Stevens RL, Maslov S, Dehal P, Ware D, Perez F, Canon S, Sneddon MW, Henderson ML, Riehl WJ, Murphy-Olson D, Chan SY, Kamimura RT, Kumari S, Drake MM, Brettin TS, Glass EM, Chivian D, Gunter D, Weston DJ, Allen BH, Baumohl J, Best AA, Bowen B, Brenner SE, Bun CC, Chandonia J-M, Chia J-M, Colasanti R, Conrad N, Davis JJ, Davison BH, DeJongh M, Devoid S, Dietrich E, Dubchak I, Edirisinghe JN, Fang G, Faria JP, Frybarger PM, Gerlach W, Gerstein M, Greiner A, Gurtowski J, Haun HL, He F, Jain R, Joachimiak MP, Keegan KP, Kondo S, Kumar V, Land ML, Meyer F, Mills M, Novichkov PS, Oh T, Olsen GJ, Olson R, Parrello B, Pasternak S, Pearson E, Poon SS, Price GA, Ramakrishnan S, Ranjan P, Ronald PC, Schatz MC, Seaver SMD, Shukla M, Sutormin RA, Syed MH, Thomason J, Tintle NL, Wang D, Xia F, Yoo H, Yoo S, Yu D (2018) KBase: The United States Department of Energy Systems Biology Knowledgebase. Nature Biotechnology, 36, 566–569. https://doi.org/10.1038/nbt.4163 [7] Wilke A, Bischof J, Gerlach W, Glass E, Harrison T, Keegan KP, Paczian T, Trimble WL, Bagchi S, Grama A, Chaterji S, Meyer F (2016) The MG-RAST metagenomics database and portal in 2015. Nucleic Acids Research, 44, D590–D594. https://doi.org/10.1093/nar/gkv1322 | A primer and discussion on DNA-based microbiome data and related bioinformatics analyses | Gavin M. Douglas and Morgan G. I. Langille | <p style="text-align: justify;">The past decade has seen an eruption of interest in profiling microbiomes through DNA sequencing. The resulting investigations have revealed myriad insights and attracted an influx of researchers to the research are... | | Bioinformatics, Metagenomics | Danny Ionescu | 2021-02-17 00:26:46 | ||
02 Apr 2021

Semi-artificial datasets as a resource for validation of bioinformatics pipelines for plant virus detectionToward a critical assessment of virus detection in plantsRecommended by Hadi Quesneville based on reviews by Alexander Suh and 1 anonymous reviewerThe advent of High Throughput Sequencing (HTS) since the last decade has revealed previously unsuspected diversity of viruses as well as their (sometimes) unexpected presence in some healthy individuals. These results demonstrate that genomics offers a powerful tool for studying viruses at the individual level, allowing an in-depth inventory of those that are infecting an organism. Such approaches make it possible to study viromes with an unprecedented level of detail, both qualitative and quantitative, which opens new venues for analyses of viruses of humans, animals and plants. Consequently, the diagnostic field is using more and more HTS, fueling the need for efficient and reliable bioinformatics tools. Many such tools have already been developed, but in plant disease diagnostics, validation of the bioinformatics pipelines used for the detection of viruses in HTS datasets is still in its infancy. There is an urgent need for benchmarking the different tools and algorithms using well-designed reference datasets generated for this purpose. This is a crucial step to move forward and to improve existing solutions toward well-standardized bioinformatics protocols. This context has led to the creation of the Plant Health Bioinformatics Network (PHBN), a Euphresco network project aiming to build a bioinformatics community working on plant health. One of their objectives is to provide researchers with open-access reference datasets allowing to compare and validate virus detection pipelines. In this framework, Tamisier et al. [1] present real, semi-artificial, and completely artificial datasets, each aimed at addressing challenges that could affect virus detection. These datasets comprise real RNA-seq reads from virus-infected plants as well as simulated virus reads. Such a work, providing open-access datasets for benchmarking bioinformatics tools, should be encouraged as they are key to software improvement as demonstrated by the well-known success story of the protein structure prediction community: their pioneer community-wide effort, called Critical Assessment of protein Structure Prediction (CASP)[2], has been providing research groups since 1994 with an invaluable way to objectively test their structure prediction methods, thereby delivering an independent assessment of state-of-art protein-structure modelling tools. Following this success, many other bioinformatic community developed similar “competitions”, such as RNA-puzzles [3] to predict RNA structures, Critical Assessment of Function Annotation [4] to predict gene functions, Critical Assessment of Prediction of Interactions [5] to predict protein-protein interactions, Assemblathon [6] for genome assembly, etc. These are just a few examples from a long list of successful initiatives. Such efforts enable rigorous assessments of tools, stimulate the developers’ creativity, but also provide user communities with a state-of-art evaluation of available tools. Inspired by these success stories, the authors propose a “VIROMOCK challenge” [7], asking researchers in the field to test their tools and to provide feedback on each dataset through a repository. This initiative, if well followed, will undoubtedly improve the field of virus detection in plants, but also probably in many other organisms. This will be a major contribution to the field of viruses, leading to better diagnostics and, consequently, a better understanding of viral diseases, thus participating in promoting human, animal and plant health. References [1] Tamisier, L., Haegeman, A., Foucart, Y., Fouillien, N., Al Rwahnih, M., Buzkan, N., Candresse, T., Chiumenti, M., De Jonghe, K., Lefebvre, M., Margaria, P., Reynard, J.-S., Stevens, K., Kutnjak, D. and Massart, S. (2021) Semi-artificial datasets as a resource for validation of bioinformatics pipelines for plant virus detection. Zenodo, 4273791, version 4 peer-reviewed and recommended by Peer community in Genomics. doi: https://doi.org/10.5281/zenodo.4273791 [2] Critical Assessment of protein Structure Prediction” (CASP) - https://en.wikipedia.org/wiki/CASP [3] RNA-puzzles - https://www.rnapuzzles.org [4] Critical Assessment of Function Annotation (CAFA) - https://en.wikipedia.org/wiki/Critical_Assessment_of_Function_Annotation [5] Critical Assessment of Prediction of Interactions (CAPI) - https://en.wikipedia.org/wiki/Critical_Assessment_of_Prediction_of_Interactions [6] Assemblathon - https://assemblathon.org [7] VIROMOCK challenge - https://gitlab.com/ilvo/VIROMOCKchallenge | Semi-artificial datasets as a resource for validation of bioinformatics pipelines for plant virus detection | Lucie Tamisier, Annelies Haegeman, Yoika Foucart, Nicolas Fouillien, Maher Al Rwahnih, Nihal Buzkan, Thierry Candresse, Michela Chiumenti, Kris De Jonghe, Marie Lefebvre, Paolo Margaria, Jean Sébastien Reynard, Kristian Stevens, Denis Kutnjak, Séb... | <p>The widespread use of High-Throughput Sequencing (HTS) for detection of plant viruses and sequencing of plant virus genomes has led to the generation of large amounts of data and of bioinformatics challenges to process them. Many bioinformatics... | | Bioinformatics, Plants, Viruses and transposable elements | Hadi Quesneville | 2020-11-27 14:31:47 | ||
02 Jun 2023
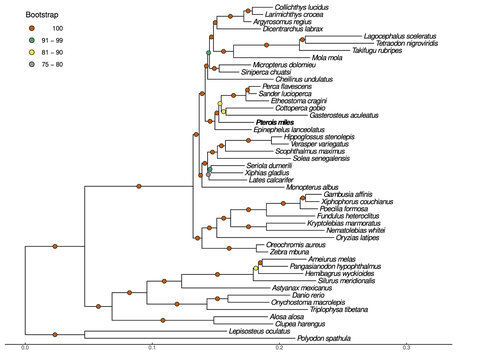
Near-chromosome level genome assembly of devil firefish, Pterois milesThe genome of a dangerous invader (fish) beautyRecommended by Iker Irisarri based on reviews by Maria Recuerda and 1 anonymous reviewer
High-quality genomes are currently being generated at an unprecedented speed powered by long-read sequencing technologies. However, sequencing effort is concentrated unequally across the tree of life and several key evolutionary and ecological groups remain largely unexplored. So is the case for fish species of the family Scorpaenidae (Perciformes). Kitsoulis et al. present the genome of the devil firefish, Pterois miles (1). Following current best practices, the assembly relies largely on Oxford Nanopore long reads, aided by Illumina short reads for polishing to increase the per-base accuracy. PacBio’s IsoSeq was used to sequence RNA from a variety of tissues as direct evidence for annotating genes. The reconstructed genome is 902 Mb in size and has high contiguity (N50=14.5 Mb; 660 scaffolds, 90% of the genome covered by the 83 longest scaffolds) and completeness (98% BUSCO completeness). The new genome is used to assess the phylogenetic position of P. miles, explore gene synteny against zebrafish, look at orthogroup expansion and contraction patterns in Perciformes, as well as to investigate the evolution of toxins in scorpaenid fish (2). In addition to its value for better understanding the evolution of scorpaenid and teleost fishes, this new genome is also an important resource for monitoring its invasiveness through the Mediterranean Sea (3) and the Atlantic Ocean, in the latter case forming the invasive lionfish complex with P. volitans (4). REFERENCES 1. Kitsoulis CV, Papadogiannis V, Kristoffersen JB, Kaitetzidou E, Sterioti E, Tsigenopoulos CS, Manousaki T. (2023) Near-chromosome level genome assembly of devil firefish, Pterois miles. BioRxiv, ver. 6 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.01.10.523469 2. Kiriake A, Shiomi K. (2011) Some properties and cDNA cloning of proteinaceous toxins from two species of lionfish (Pterois antennata and Pterois volitans). Toxicon, 58(6-7):494–501. https://doi.org/10.1016/j.toxicon.2011.08.010 3. Katsanevakis S, et al. (2020) Un- published Mediterranean records of marine alien and cryptogenic species. BioInvasions Records, 9:165–182. https://doi.org/10.3391/bir.2020.9.2.01 4. Lyons TJ, Tuckett QM, Hill JE. (2019) Data quality and quantity for invasive species: A case study of the lionfishes. Fish and Fisheries, 20:748–759. https://doi.org/10.1111/faf.12374 | Near-chromosome level genome assembly of devil firefish, *Pterois miles* | Christos V. Kitsoulis, Vasileios Papadogiannis, Jon B. Kristoffersen, Elisavet Kaitetzidou, Aspasia Sterioti, Costas S. Tsigenopoulos, Tereza Manousaki | <p style="text-align: justify;">Devil firefish (<em>Pterois miles</em>), a member of Scorpaenidae family, is one of the most successful marine non-native species, dominating around the world, that was rapidly spread into the Mediterranean Sea, thr... | | Evolutionary genomics | Iker Irisarri | 2023-01-17 12:37:20 | ||
16 Dec 2022
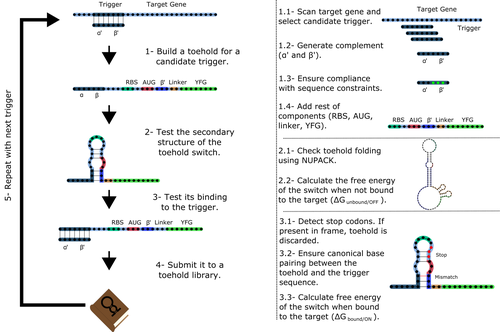
Toeholder: a Software for Automated Design and In Silico Validation of Toehold RiboswitchesA novel approach for engineering biological systems by interfacing computer science with synthetic biologyRecommended by Sahar Melamed based on reviews by Wim Wranken and 1 anonymous reviewerBiological systems depend on finely tuned interactions of their components. Thus, regulating these components is critical for the system's functionality. In prokaryotic cells, riboswitches are regulatory elements controlling transcription or translation. Riboswitches are RNA molecules that are usually located in the 5′-untranslated region of protein-coding genes. They generate secondary structures leading to the regulation of the expression of the downstream protein-coding gene (Kavita and Breaker, 2022). Riboswitches are very versatile and can bind a wide range of small molecules; in many cases, these are metabolic byproducts from the gene’s enzymatic or signaling pathway. Their versatility and abundance in many species make them attractive for synthetic biological circuits. One class that has been drawing the attention of synthetic biologists is toehold switches (Ekdahl et al., 2022; Green et al., 2014). These are single-stranded RNA molecules harboring the necessary elements for translation initiation of the downstream gene: a ribosome-binding site and a start codon. Conformation change of toehold switches is triggered by an RNA molecule, which enables translation. To exploit the most out of toehold switches, automation of their design would be highly advantageous. Cisneros and colleagues (Cisneros et al., 2022) developed a tool, “Toeholder”, that automates the design of toehold switches and performs in silico tests to select switch candidates for a target gene. Toeholder is an open-source tool that provides a comprehensive and automated workflow for the design of toehold switches. While web tools have been developed for designing toehold switches (To et al., 2018), Toeholder represents an intriguing approach to engineering biological systems by coupling synthetic biology with computational biology. Using molecular dynamics simulations, it identified the positions in the toehold switch where hydrogen bonds fluctuate the most. Identifying these regions holds great potential for modifications when refining the design of the riboswitches. To be effective, toehold switches should provide a strong ON signal and a weak OFF signal in the presence or the absence of a target, respectively. Toeholder nicely ranks the candidate toehold switches based on experimental evidence that correlates with toehold performance (based on good ON/OFF ratios). Riboswitches are highly appealing for a broad range of applications, including pharmaceutical and medical purposes (Blount and Breaker, 2006; Giarimoglou et al., 2022; Tickner and Farzan, 2021), thanks to their adaptability and inexpensiveness. The Toeholder tool developed by Cisneros and colleagues is expected to promote the implementation of toehold switches into these various applications. References Blount KF, Breaker RR (2006) Riboswitches as antibacterial drug targets. Nature Biotechnology, 24, 1558–1564. https://doi.org/10.1038/nbt1268 Cisneros AF, Rouleau FD, Bautista C, Lemieux P, Dumont-Leblond N, ULaval 2019 T iGEM (2022) Toeholder: a Software for Automated Design and In Silico Validation of Toehold Riboswitches. bioRxiv, 2021.11.09.467922, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.11.09.467922 Ekdahl AM, Rojano-Nisimura AM, Contreras LM (2022) Engineering Toehold-Mediated Switches for Native RNA Detection and Regulation in Bacteria. Journal of Molecular Biology, 434, 167689. https://doi.org/10.1016/j.jmb.2022.167689 Giarimoglou N, Kouvela A, Maniatis A, Papakyriakou A, Zhang J, Stamatopoulou V, Stathopoulos C (2022) A Riboswitch-Driven Era of New Antibacterials. Antibiotics, 11, 1243. https://doi.org/10.3390/antibiotics11091243 Green AA, Silver PA, Collins JJ, Yin P (2014) Toehold Switches: De-Novo-Designed Regulators of Gene Expression. Cell, 159, 925–939. https://doi.org/10.1016/j.cell.2014.10.002 Kavita K, Breaker RR (2022) Discovering riboswitches: the past and the future. Trends in Biochemical Sciences. https://doi.org/10.1016/j.tibs.2022.08.009 Tickner ZJ, Farzan M (2021) Riboswitches for Controlled Expression of Therapeutic Transgenes Delivered by Adeno-Associated Viral Vectors. Pharmaceuticals, 14, 554. https://doi.org/10.3390/ph14060554 To AC-Y, Chu DH-T, Wang AR, Li FC-Y, Chiu AW-O, Gao DY, Choi CHJ, Kong S-K, Chan T-F, Chan K-M, Yip KY (2018) A comprehensive web tool for toehold switch design. Bioinformatics, 34, 2862–2864. https://doi.org/10.1093/bioinformatics/bty216 | Toeholder: a Software for Automated Design and In Silico Validation of Toehold Riboswitches | Angel F. Cisneros, François D. Rouleau, Carla Bautista, Pascale Lemieux, Nathan Dumont-Leblond | <p>Abstract: Synthetic biology aims to engineer biological circuits, which often involve gene expression. A particularly promising group of regulatory elements are riboswitches because of their versatility with respect to their targets, but e... | | Bioinformatics | Sahar Melamed | 2022-02-16 14:40:13 | ||
10 Jul 2023
SNP discovery by exome capture and resequencing in a pea genetic resource collectionThe value of a large Pisum SNP datasetRecommended by Wanapinun Nawae based on reviews by Rui Borges and 1 anonymous reviewerOne important goal of modern genetics is to establish functional associations between genotype and phenotype. Single nucleotide polymorphisms (SNPs) are numerous and widely distributed in the genome and can be obtained from nucleic acid sequencing (1). SNPs allow for the investigation of genetic diversity, which is critical for increasing crop resilience to the challenges posed by global climate change. The associations between SNPs and phenotypes can be captured in genome-wide association studies. SNPs can also be used in combination with machine learning, which is becoming more popular for predicting complex phenotypic traits like yield and biotic and abiotic stress tolerance from genotypic data (2). The availability of many SNP datasets is important in machine learning predictions because this approach requires big data to build a comprehensive model of the association between genotype and phenotype. Aubert and colleagues have studied, as part of the PeaMUST project, the genetic diversity of 240 Pisum accessions (3). They sequenced exome-enriched genomic libraries, a technique that enables the identification of high-density, high-quality SNPs at a low cost (4). This technique involves capturing and sequencing only the exonic regions of the genome, which are the protein-coding regions. A total of 2,285,342 SNPs were obtained in this study. The analysis of these SNPs with the annotations of the genome sequence of one of the studied pea accessions (5) identified a number of SNPs that could have an impact on gene activity. Additional analyses revealed 647,220 SNPs that were unique to individual pea accessions, which might contribute to the fitness and diversity of accessions in different habitats. Phylogenetic and clustering analyses demonstrated that the SNPs could distinguish Pisum germplasms based on their agronomic and evolutionary histories. These results point out the power of selected SNPs as markers for identifying Pisum individuals. Overall, this study found high-quality SNPs that are meaningful in a biological context. This dataset was derived from a large set of germplasm and is thus particularly useful for studying genotype-phenotype associations, as well as the diversity within Pisum species. These SNPs could also be used in breeding programs to develop new pea varieties that are resilient to abiotic and biotic stressors. References
https://doi.org/10.1139/gen-2021-005
https://doi.org/10.1186/s12870-022-03559-z
https://doi.org/10.1101/2022.08.03.502586
https://doi.org/10.1534/g3.115.018564
| SNP discovery by exome capture and resequencing in a pea genetic resource collection | G. Aubert, J. Kreplak, M. Leveugle, H. Duborjal, A. Klein, K. Boucherot, E. Vieille, M. Chabert-Martinello, C. Cruaud, V. Bourion, I. Lejeune-Hénaut, M.L. Pilet-Nayel, Y. Bouchenak-Khelladi, N. Francillonne, N. Tayeh, J.P. Pichon, N. Rivière, J. B... | <p style="text-align: justify;"><strong>Background & Summary</strong></p> <p style="text-align: justify;">In addition to being the model plant used by Mendel to establish genetic laws, pea (<em>Pisum sativum</em> L., 2n=14) is a major pulse c... | | Plants, Population genomics | Wanapinun Nawae | 2022-11-29 09:29:06 | ||
20 Nov 2023
Building a Portuguese Coalition for Biodiversity GenomicsThe Portuguese genomics community teams up with iconic species to understand the destruction of biodiversityRecommended by Fernando Racimo based on reviews by Svein-Ole Mikalsen and 1 anonymous reviewerThis manuscript describes the ongoing work and plans of Biogenome Portugal: a new network of researchers in the Portuguese biodiversity genomics community. The aims of this network are to jointly train scientists in ecology and evolution, generate new knowledge and understanding of Portuguese biodiversity, and better engage with the public and with international researchers, so as to advance conservation efforts in the region. In collaboration across disciplines and institutions, they are also contributing to the European Reference Genome Atlas (ERGA): a massive scientific effort, seeking to eventually produce reference-quality genomes for all species in the European continent (Mc Cartney et al. 2023). The manuscript centers around six iconic and/or severely threatened species, whose range extends across parts of what is today considered Portuguese territory. Via the Portugal chapter of ERGA (ERGA-Portugal), the researchers will generate high-quality genome sequences from these species. The species are the Iberian hare, the Azores laurel, the Black wheatear, the Portuguese crowberry, the Cave ground beetle and the Iberian minnowcarp. In ignorance of human-made political borders, some of these species also occupy large parts of the rest of the Iberian peninsula, highlighting the importance of transnational collaboration in biodiversity efforts. The researchers extracted samples from members of each of these species, and are building reference genome sequences from them. In some cases, these sequences will also be co-analyzed with additional population genomic data from the same species or genetic data from cohabiting species. The researchers aim to answer a variety of ecological and evolutionary questions using this information, including how genetic diversity is being affected by the destruction of their habitat, and how they are being forced to adapt as a consequence of the climate emergency. The authors did a very good job in providing a justification for the choice of pilot species, a thorough methodological overview of current work, and well thought-out plans for future analyses once the genome sequences are available for study. The authors also describe plans for networking and training activities to foster a well-connected Portuguese biodiversity genomics community. Applying a genomic analysis lens is important for understanding the ever faster process of devastation of our natural world. Governments and corporations around the globe are destroying nature at ever larger scales (Diaz et al. 2019). They are also destabilizing the climatic conditions on which life has existed for thousands of years (Trisos et al. 2020). Thus, genetic diversity is decreasing faster than ever in human history, even when it comes to non-threatened species (Exposito-Alonso et al. 2022), and these decreases are disrupting ecological processes worldwide (Richardson et al. 2023). This, in turn, is threatening the conditions on which the stability of our societies rest (Gardner and Bullock 2021). The efforts of Biogenome Portal and ERGA-Portugal will go a long way in helping us understand in greater detail how this process is unfolding in Portuguese territories.
References Díaz, Sandra, et al. "Pervasive human-driven decline of life on Earth points to the need for transformative change." Science 366.6471 (2019): eaax3100. https://doi.org/10.1126/science.aax3100 Exposito-Alonso, Moises, et al. "Genetic diversity loss in the Anthropocene." Science 377.6613 (2022): 1431-1435. https://doi.org/10.1126/science.abn5642 Gardner, Charlie J., and James M. Bullock. "In the climate emergency, conservation must become survival ecology." Frontiers in Conservation Science 2 (2021): 659912. https://doi.org/10.3389/fcosc.2021.659912 Mc Cartney, Ann M., et al. "The European Reference Genome Atlas: piloting a decentralised approach to equitable biodiversity genomics." bioRxiv (2023): 2023-09, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.32942/X20W3Q Richardson, Katherine, et al. "Earth beyond six of nine planetary boundaries." Science Advances 9.37 (2023): eadh2458. https://doi.org/10.1126/sciadv.adh2458 Trisos, Christopher H., Cory Merow, and Alex L. Pigot. "The projected timing of abrupt ecological disruption from climate change." Nature 580.7804 (2020): 496-501. https://doi.org/10.1038/s41586-020-2189-9 | Building a Portuguese Coalition for Biodiversity Genomics | João Pedro Marques, Paulo Célio Alves, Isabel R. Amorim, Ricardo J. Lopes, Mónica Moura, Gene Meyers, Manuela Sim-Sim, Carla Sousa-Santos, Maria Judite Alves, Paulo AV Borges, Thomas Brown, Miguel Carneiro, Carlos Carrapato, Luís Ceríaco, Claudio ... | <p style="text-align: justify;">The diverse physiography of the Portuguese land and marine territory, spanning from continental Europe to the Atlantic archipelagos, has made it an important repository of biodiversity throughout the Pleistocene gla... | | ERGA, ERGA Pilot | Fernando Racimo | 2023-07-14 11:24:22 | ||
08 Nov 2022

Somatic mutation detection: a critical evaluation through simulations and reanalyses in oaksHow to best call the somatic mosaic tree?Recommended by Nicolas Bierne based on reviews by 2 anonymous reviewersAny multicellular organism is a molecular mosaic with some somatic mutations accumulated between cell lineages. Big long-lived trees have nourished this imaginary of a somatic mosaic tree, from the observation of spectacular phenotypic mosaics and also because somatic mutations are expected to potentially be passed on to gametes in plants (review in Schoen and Schultz 2019). The lower cost of genome sequencing now offers the opportunity to tackle the issue and identify somatic mutations in trees. However, when it comes to characterizing this somatic mosaic from genome sequences, things become much more difficult than one would think in the first place. What separates cell lineages ontogenetically, in cell division number, or in time? How to sample clonal cell populations? How do somatic mutations distribute in a population of cells in an organ or an organ sample? Should they be fixed heterozygotes in the sample of cells sequenced or be polymorphic? Do we indeed expect somatic mutations to be fixed? How should we identify and count somatic mutations? To date, the detection of somatic mutations has mostly been done with a single variant caller in a given study, and we have little perspective on how different callers provide similar or different results. Some studies have used standard SNP callers that assumed a somatic mutation is fixed at the heterozygous state in the sample of cells, with an expected allele coverage ratio of 0.5, and less have used cancer callers, designed to detect mutations in a fraction of the cells in the sample. However, standard SNP callers detect mutations that deviate from a balanced allelic coverage, and different cancer callers can have different characteristics that should affect their outcomes. In order to tackle these issues, Schmitt et al. (2022) conducted an extensive simulation analysis to compare different variant callers. Then, they reanalyzed two large published datasets on pedunculate oak, Quercus robur. The analysis of in silico somatic mutations allowed the authors to evaluate the performance of different variant callers as a function of the allelic fraction of somatic mutations and the sequencing depth. They found one of the seven callers to provide better and more robust calls for a broad set of allelic fractions and sequencing depths. The reanalysis of published datasets in oaks with the most effective cancer caller of the in silico analysis allowed them to identify numerous low-frequency mutations that were missed in the original studies. I recommend the study of Schmitt et al. (2022) first because it shows the benefit of using cancer callers in the study of somatic mutations, whatever the allelic fraction you are interested in at the end. You can select fixed heterozygotes if this is your ultimate target, but cancer callers allow you to have in addition a valuable overview of the allelic fractions of somatic mutations in your sample, and most do as well as SNP callers for fixed heterozygous mutations. In addition, Schmitt et al. (2022) provide the pipelines that allow investigating in silico data that should correspond to a given study design, encouraging to compare different variant callers rather than arbitrarily going with only one. We can anticipate that the study of somatic mutations in non-model species will increasingly attract attention now that multiple tissues of the same individual can be sequenced at low cost, and the study of Schmitt et al. (2022) paves the way for questioning and choosing the best variant caller for the question one wants to address. References Schoen DJ, Schultz ST (2019) Somatic Mutation and Evolution in Plants. Annual Review of Ecology, Evolution, and Systematics, 50, 49–73. https://doi.org/10.1146/annurev-ecolsys-110218-024955 Schmitt S, Leroy T, Heuertz M, Tysklind N (2022) Somatic mutation detection: a critical evaluation through simulations and reanalyses in oaks. bioRxiv, 2021.10.11.462798. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.10.11.462798 | Somatic mutation detection: a critical evaluation through simulations and reanalyses in oaks | Sylvain Schmitt, Thibault Leroy, Myriam Heuertz, Niklas Tysklind | <p style="text-align: justify;">1. Mutation, the source of genetic diversity, is the raw material of evolution; however, the mutation process remains understudied, especially in plants. Using both a simulation and reanalysis framework, we set out ... | | Bioinformatics, Plants | Nicolas Bierne | Anonymous, Anonymous | 2022-04-28 13:24:19 | |
22 May 2023

Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approachScoring symptoms of a plant viral diseaseRecommended by Olivier Panaud based on reviews by Grégoire Aubert and Valérie GeffroyThe paper from Silva et al. (2023) provides new insights into the genetic bases of natural resistance of rice to the Rice Hoja Blanca (RHB) disease, one of its most serious diseases in tropical countries of the American continent and the Caribbean. This disease is caused by the Rice Hoja Blanca Virus, or RHBV, the vector of which is the planthopper insect Tagosodes orizicolus Müir. It is responsible for serious damage to the rice crop (Morales and Jennings 2010). The authors take a Quantitative Trait Loci (QTL) detection approach to find genomic regions statistically associated with the resistant phenotype. To this aim, they use four resistant x susceptible crosses (the susceptible parent being the same in all four crosses) to maximize the chances to find new QTLs. The F2 populations derived from the crosses are genotyped using Single Nucleotide Polymorphisms (SNPs) extracted from whole-genome sequencing (WGS) data of the resistant parents, and the F3 families derived from the F2 individuals are scored for disease symptoms. For this, they use a computer-aided image analysis protocol that they designed so they can estimate the severity of the damages in the plant. They find several new QTLs, some being apparently more associated with disease severity, others with disease incidence. They also find that a previously identified QTL of Oryza sativa ssp. japonica origin is also present in the indica cluster (Romero et al. 2014). Finally, they discuss the candidate genes that could underlie the QTLs and provide a simple model for resistance. It has to be noted that scoring symptoms of a viral disease such as RHB is very challenging. It requires maintaining populations of viruliferous insect vectors, mastering times and conditions for infestation by nymphs, and precise symptom scoring. It also requires the preparation of segregating populations, their genotyping with enough genetic markers, and mastering QTL detection methods. All these aspects are present in this work. In particular, the phenotyping of symptom severity implemented using computer-aided image processing represents an impressive, enormous amount of work. From the genomics side, the fine-scale genotyping is based on the WGS of the parental lines (resistant and susceptible), followed by the application of suitable bioinformatic tools for SNP extraction and primers prediction that can be used on their Fluidigm platform. It also required implementing data correction algorithms to achieve precise genetic maps in the four crosses. The QTL detection itself required careful statistical pre-processing of phenotypic data. The authors then used a combination of several QTL detection methods, including an original meta-QTL method they developed in the software MapDisto. The authors then perform a very complete and convincing analysis of candidate genes, which includes genes already identified for a similar disease (RSV) on chromosome 11 of rice. What remains to elucidate is whether the candidate genes are actually involved or not in the disease resistance process. The team has already started implementing gene knockout strategies to study some of them in more detail. It will be interesting to see whether those genes act against the virus itself, or against the insect vector. Overall the work is of high quality and represents an important advance in the knowledge of disease resistance. In addition, it has many implications for crop breeding, allowing the setup of large-scale, marker-assisted strategies, for new resistant elite varieties of rice. References Morales F and Jennings P (2010) Rice hoja blanca: a complex plant-virus-vector pathosystem. CAB Reviews. https://doi.org/10.1079/PAVSNNR20105043 Romero LE, Lozano I, Garavito A, et al (2014) Major QTLs control resistance to Rice hoja blanca virus and its vector Tagosodes orizicolus. G3 | Genes, Genomes, Genetics 4:133–142. https://doi.org/10.1534/g3.113.009373 Silva A, Montoya ME, Quintero C, Cuasquer J, Tohme J, Graterol E, Cruz M, Lorieux M (2023) Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approach. bioRxiv, 2022.11.07.515427, ver. 2 peer-reviewed and recommended by Peer Community in Genomics https://doi.org/10.1101/2022.11.07.515427 | Genetic bases of resistance to the rice hoja blanca disease deciphered by a QTL approach | Alexander Silva, Maria Elker Montoya, Constanza Quintero, Juan Cuasquer, Joe Tohme, Eduardo Graterol, Maribel Cruz, Mathias Lorieux | <p style="text-align: justify;">Rice hoja blanca (RHB) is one of the most serious diseases in rice growing areas in tropical Americas. Its causal agent is Rice hoja blanca virus (RHBV), transmitted by the planthopper <em>Tagosodes orizicolus </em>... | | Functional genomics, Plants | Olivier Panaud | 2022-11-09 09:13:30 | ||
23 Sep 2022
MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studiesMATEdb: a new phylogenomic-driven database for MetazoaRecommended by Samuel Abalde based on reviews by 2 anonymous reviewers
The development (and standardization) of high-throughput sequencing techniques has revolutionized evolutionary biology, to the point that we almost see as normal fine-detail studies of genome architecture evolution (Robert et al., 2022), adaptation to new habitats (Rahi et al., 2019), or the development of key evolutionary novelties (Hilgers et al., 2018), to name three examples. One of the fields that has benefited the most is phylogenomics, i.e. the use of genome-wide data for inferring the evolutionary relationships among organisms. Dealing with such amount of data, however, has come with important analytical and computational challenges. Likewise, although the steady generation of genomic data from virtually any organism opens exciting opportunities for comparative analyses, it also creates a sort of “information fog”, where it is hard to find the most appropriate and/or the higher quality data. I have personally experienced this not so long ago, when I had to spend several weeks selecting the most complete transcriptomes from several phyla, moving back and forth between the NCBI SRA repository and the relevant literature. In an attempt to deal with this issue, some research labs have committed their time and resources to the generation of taxa- and topic-specific databases (Lathe et al., 2008), such as MolluscDB (Liu et al., 2021), focused on mollusk genomics, or EukProt (Richter et al., 2022), a protein repository representing the diversity of eukaryotes. A new database that promises to become an important resource in the near future is MATEdb (Fernández et al., 2022), a repository of high-quality genomic data from Metazoa. MATEdb has been developed from publicly available and newly generated transcriptomes and genomes, prioritizing quality over quantity. Upon download, the user has access to both raw data and the related datasets: assemblies, several quality metrics, the set of inferred protein-coding genes, and their annotation. Although it is clear to me that this repository has been created with phylogenomic analyses in mind, I see how it could be generalized to other related problems such as analyses of gene content or evolution of specific gene families. In my opinion, the main strengths of MATEdb are threefold:
On a negative note, I see two main drawbacks. First, as of today (September 16th, 2022) this database is in an early stage and it still needs to incorporate a lot of animal groups. This has been discussed during the revision process and the authors are already working on it, so it is only a matter of time until all major taxa are represented. Second, there is a scalability issue. In its current format it is not possible to select the taxa of interest and the full database has to be downloaded, which will become more and more difficult as it grows. Nonetheless, with the appropriate resources it would be easy to find a better solution. There are plenty of examples that could serve as inspiration, so I hope this does not become a big problem in the future. Altogether, I and the researchers that participated in the revision process believe that MATEdb has the potential to become an important and valuable addition to the metazoan phylogenomics community. Personally, I wish it was available just a few months ago, it would have saved me so much time. References Fernández R, Tonzo V, Guerrero CS, Lozano-Fernandez J, Martínez-Redondo GI, Balart-García P, Aristide L, Eleftheriadi K, Vargas-Chávez C (2022) MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studies. bioRxiv, 2022.07.18.500182, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.07.18.500182 Hilgers L, Hartmann S, Hofreiter M, von Rintelen T (2018) Novel Genes, Ancient Genes, and Gene Co-Option Contributed to the Genetic Basis of the Radula, a Molluscan Innovation. Molecular Biology and Evolution, 35, 1638–1652. https://doi.org/10.1093/molbev/msy052 Lathe W, Williams J, Mangan M, Karolchik, D (2008). Genomic data resources: challenges and promises. Nature Education, 1(3), 2. Liu F, Li Y, Yu H, Zhang L, Hu J, Bao Z, Wang S (2021) MolluscDB: an integrated functional and evolutionary genomics database for the hyper-diverse animal phylum Mollusca. Nucleic Acids Research, 49, D988–D997. https://doi.org/10.1093/nar/gkaa918 Rahi ML, Mather PB, Ezaz T, Hurwood DA (2019) The Molecular Basis of Freshwater Adaptation in Prawns: Insights from Comparative Transcriptomics of Three Macrobrachium Species. Genome Biology and Evolution, 11, 1002–1018. https://doi.org/10.1093/gbe/evz045 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Robert NSM, Sarigol F, Zimmermann B, Meyer A, Voolstra CR, Simakov O (2022) Emergence of distinct syntenic density regimes is associated with early metazoan genomic transitions. BMC Genomics, 23, 143. https://doi.org/10.1186/s12864-022-08304-2 | MATEdb, a data repository of high-quality metazoan transcriptome assemblies to accelerate phylogenomic studies | Rosa Fernandez, Vanina Tonzo, Carolina Simon Guerrero, Jesus Lozano-Fernandez, Gemma I Martinez-Redondo, Pau Balart-Garcia, Leandro Aristide, Klara Eleftheriadi, Carlos Vargas-Chavez | <p style="text-align: justify;">With the advent of high throughput sequencing, the amount of genomic data available for animals (Metazoa) species has bloomed over the last decade, especially from transcriptomes due to lower sequencing costs and ea... | | Bioinformatics, Evolutionary genomics, Functional genomics | Samuel Abalde | 2022-07-20 07:30:39 | ||
18 Feb 2021
Traces of transposable element in genome dark matter co-opted by flowering gene regulation networksUsing small fragments to discover old TE remnants: the Duster approach empowers the TE detectionRecommended by Francois Sabot based on reviews by Josep Casacuberta and 1 anonymous reviewer
Transposable elements are the raw material of the dark matter of the genome, the foundation of the next generation of genes and regulation networks". This sentence could be the essence of the paper of Baud et al. (2021). Transposable elements (TEs) are endogenous mobile genetic elements found in almost all genomes, which were discovered in 1948 by Barbara McClintock (awarded in 1983 the only unshared Medicine Nobel Prize so far). TEs are present everywhere, from a single isolated copy for some elements to more than millions for others, such as Alu. They are founders of major gene lineages (HET-A, TART and telomerases, RAG1/RAG2 proteins from mammals immune system; Diwash et al, 2017), and even of retroviruses (Xiong & Eickbush, 1988). However, most TEs appear as selfish elements that replicate, land in a new genomic region, then start to decay and finally disappear in the midst of the genome, turning into genomic ‘dark matter’ (Vitte et al, 2007). The mutations (single point, deletion, recombination, and so on) that occur during this slow death erase some of their most notable features and signature sequences, rendering them completely unrecognizable after a few million years. Numerous TE detection tools have tried to optimize their detection (Goerner-Potvin & Bourque, 2018), but further improvement is definitely challenging. This is what Baud et al. (2021) accomplished in their paper. They used a simple, elegant and efficient k-mer based approach to find small signatures that, when accumulated, allow identifying very old TEs. Using this method, called Duster, they improved the amount of annotated TEs in the model plant Arabidopsis thaliana by 20%, pushing the part of this genome occupied by TEs up from 40 to almost 50%. They further observed that these very old Duster-specific TEs (i.e., TEs that are only detected by Duster) are, among other properties, close to genes (much more than recent TEs), not targeted by small RNA pathways, and highly associated with conserved regions across the rosid family. In addition, they are highly associated with flowering or stress response genes, and may be involved through exaptation in the evolution of responses to environmental changes. TEs are not just selfish elements: more and more studies have shown their key role in the evolution of their hosts, and tools such as Duster will help us better understand their impact. References Baud, A., Wan, M., Nouaud, D., Francillonne, N., Anxolabéhère, D. and Quesneville, H. (2021). Traces of transposable elements in genome dark matter co-opted by flowering gene regulation networks. bioRxiv, 547877, ver. 5 peer-reviewed and recommended by PCI Genomics.doi: https://doi.org/10.1101/547877 | Traces of transposable element in genome dark matter co-opted by flowering gene regulation networks | Agnes Baud, Mariene Wan, Danielle Nouaud, Nicolas Francillonne, Dominique Anxolabehere, Hadi Quesneville | <p>Transposable elements (TEs) are mobile, repetitive DNA sequences that make the largest contribution to genome bulk. They thus contribute to the so-called 'dark matter of the genome', the part of the genome in which nothing is immediately recogn... | | Bioinformatics, Evolutionary genomics, Functional genomics, Plants, Structural genomics, Viruses and transposable elements | Francois Sabot | Anonymous, Josep Casacuberta | 2020-04-07 17:12:12 |




