
Latest recommendations

| Id | Title * | Authors * | Abstract * | Picture * | Thematic fields * | Recommender▲ | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
15 Mar 2024
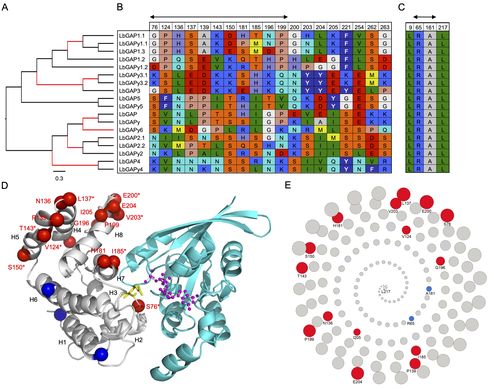
Convergent origin and accelerated evolution of vesicle-associated RhoGAP proteins in two unrelated parasitoid waspsUsing transcriptomics and proteomics to understand the expansion of a secreted poisonous armoury in parasitoid wasps genomesRecommended by Ignacio Bravo based on reviews by Inacio Azevedo and 2 anonymous reviewers based on reviews by Inacio Azevedo and 2 anonymous reviewers
Parasitoid wasps lay their eggs inside another arthropod, whose body is physically consumed by the parasitoid larvae. Phylogenetic inference suggests that Parasitoida are monophyletic, and that this clade underwent a strong radiation shortly after branching off from the Apocrita stem, some 236 million years ago (Peters et al. 2017). The increase in taxonomic diversity during evolutionary radiations is usually concurrent with an increase in genetic/genomic diversity, and is often associated with an increase in phenotypic diversity. Gene (or genome) duplication provides the evolutionary potential for such increase of genomic diversity by neo/subfunctionalisation of one of the gene paralogs, and is often proposed to be related to evolutionary radiations (Ohno 1970; Francino 2005).
References
| Convergent origin and accelerated evolution of vesicle-associated RhoGAP proteins in two unrelated parasitoid wasps | Dominique Colinet, Fanny Cavigliasso, Matthieu Leobold, Appoline Pichon, Serge Urbach, Dominique Cazes, Marine Poullet, Maya Belghazi, Anne-Nathalie Volkoff, Jean-Michel Drezen, Jean-Luc Gatti, and Marylène Poirié | <p>Animal venoms and other protein-based secretions that perform a variety of functions, from predation to defense, are highly complex cocktails of bioactive compounds. Gene duplication, accompanied by modification of the expression and/or functio... | | Evolutionary genomics | Ignacio Bravo | 2023-06-12 11:08:31 | ||
13 Jul 2022
Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codonsAn accident frozen in time: the ambiguous stop/sense genetic code of karyorelict ciliatesRecommended by Iker Irisarri based on reviews by Vittorio Boscaro and 2 anonymous reviewers
Several variations of the “universal” genetic code are known. Among the most striking are those where a codon can either encode for an amino acid or a stop signal depending on the context. Such ambiguous codes are known to have evolved in eukaryotes multiple times independently, particularly in ciliates – eight different codes have so far been discovered (1). We generally view such genetic codes are rare ‘variants’ of the standard code restricted to single species or strains, but this might as well reflect a lack of study of closely related species. In this study, Seah and co-authors (2) explore the possibility of codon reassignment in karyorelict ciliates closely related to Parduczia sp., which has been shown to contain an ambiguous genetic code (1). Here, single-cell transcriptomics are used, along with similar available data, to explore the possibility of codon reassignment across the diversity of Karyorelictea (four out of the six recognized families). Codon reassignments were inferred from their frequencies within conserved Pfam (3) protein domains, whereas stop codons were inferred from full-length transcripts with intact 3’-UTRs. Results show the reassignment of UAA and UAG stop codons to code for glutamine (Q) and the reassignment of the UGA stop codon into tryptophan (W). This occurs only within the coding sequences, whereas the end of transcription is marked by UGA as the main stop codon, and to a lesser extent by UAA. In agreement with a previous model proposed that explains the functioning of ambiguous codes (1,4), the authors observe a depletion of in-frame UGAs before the UGA codon that indicates the stop, thus avoiding premature termination of transcription. The inferred codon reassignments occur in all studied karyorelicts, including the previously studied Parduczia sp. Despite the overall clear picture, some questions remain. Data for two out of six main karyorelict lineages are so far absent and the available data for Cryptopharyngidae was inconclusive; the phylogenetic affinities of Cryptopharyngidae have also been questioned (5). This indicates the need for further study of this interesting group of organisms. As nicely discussed by the authors, experimental evidence could further strengthen the conclusions of this paper, including ribosome profiling, mass spectrometry – as done for Condylostoma (1) – or even direct genetic manipulation. The uniformity of the ambiguous genetic code across karyorelicts might at first seem dull, but when viewed in a phylogenetic context character distribution strongly suggest that this genetic code has an ancient origin in the karyorelict ancestor ~455 Ma in the Proterozoic (6). This ambiguous code is also not a rarity of some obscure species, but it is shared by ciliates that are very diverse and ecologically important. The origin of the karyorelict code is also intriguing. Adaptive arguments suggest that it could confer robustness to mutations causing premature stop codons. However, we lack evidence for ambiguous codes being linked to specific habitats of lifestyles that could account for it. Instead, the authors favor the neutral view of an ancient “frozen accident”, fixed stochastically simply because it did not pose a significant selective disadvantage. Once a stop codon is reassigned to an amino acid, it is increasingly difficult to revert this without the deleterious effect of prematurely terminating translation. At the end, the origin of the genetic code itself is thought to be a frozen accident too (7). References 1. Swart EC, Serra V, Petroni G, Nowacki M. Genetic codes with no dedicated stop codon: Context-dependent translation termination. Cell 2016;166: 691–702. https://doi.org/10.1016/j.cell.2016.06.020 2. Seah BKB, Singh A, Swart EC (2022) Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons. bioRxiv, 2022.04.12.488043. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.12.488043 3. Mistry J, Chuguransky S, Williams L, Qureshi M, Salazar GA, Sonnhammer ELL, Tosatto SCE, Paladin L, Raj S, Richardson LJ, Finn RD, Bateman A. Pfam: The protein families database in 2021, Nuc Acids Res 2020;49: D412-D419. https://doi.org/10.1093/nar/gkaa913 4. Alkalaeva E, Mikhailova T. Reassigning stop codons via translation termination: How a few eukaryotes broke the dogma. Bioessays. 2017;39. https://doi.org/10.1002/bies.201600213 5. Xu Y, Li J, Song W, Warren A. Phylogeny and establishment of a new ciliate family, Wilbertomorphidae fam. nov. (Ciliophora, Karyorelictea), a highly specialized taxon represented by Wilbertomorpha colpoda gen. nov., spec. nov. J Eukaryot Microbiol. 2013;60: 480–489. https://doi.org/10.1111/jeu.12055 6. Fernandes NM, Schrago CG. A multigene timescale and diversification dynamics of Ciliophora evolution. Mol Phylogenet Evol. 2019;139: 106521. https://doi.org/10.1016/j.ympev.2019.106521 7. Crick FH. The origin of the genetic code. J Mol Biol. 1968;38: 367–379. https://doi.org/10.1016/0022-2836(68)90392-6 | Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons | Brandon Kwee Boon Seah, Aditi Singh, Estienne Carl Swart | <p style="text-align: justify;">In ambiguous stop/sense genetic codes, the stop codon(s) not only terminate translation but can also encode amino acids. Such codes have evolved at least four times in eukaryotes, twice among ciliates (<em>Condylost... | | Bioinformatics, Evolutionary genomics | Iker Irisarri | 2022-05-02 11:06:10 | ||
02 Jun 2023
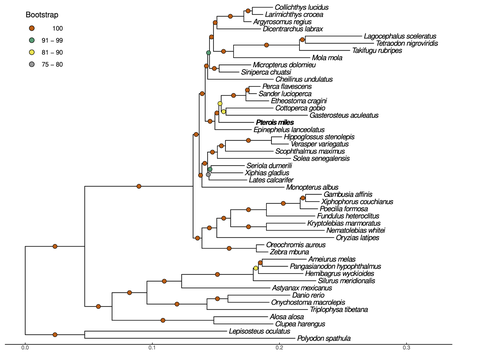
Near-chromosome level genome assembly of devil firefish, Pterois milesThe genome of a dangerous invader (fish) beautyRecommended by Iker Irisarri based on reviews by Maria Recuerda and 1 anonymous reviewer
High-quality genomes are currently being generated at an unprecedented speed powered by long-read sequencing technologies. However, sequencing effort is concentrated unequally across the tree of life and several key evolutionary and ecological groups remain largely unexplored. So is the case for fish species of the family Scorpaenidae (Perciformes). Kitsoulis et al. present the genome of the devil firefish, Pterois miles (1). Following current best practices, the assembly relies largely on Oxford Nanopore long reads, aided by Illumina short reads for polishing to increase the per-base accuracy. PacBio’s IsoSeq was used to sequence RNA from a variety of tissues as direct evidence for annotating genes. The reconstructed genome is 902 Mb in size and has high contiguity (N50=14.5 Mb; 660 scaffolds, 90% of the genome covered by the 83 longest scaffolds) and completeness (98% BUSCO completeness). The new genome is used to assess the phylogenetic position of P. miles, explore gene synteny against zebrafish, look at orthogroup expansion and contraction patterns in Perciformes, as well as to investigate the evolution of toxins in scorpaenid fish (2). In addition to its value for better understanding the evolution of scorpaenid and teleost fishes, this new genome is also an important resource for monitoring its invasiveness through the Mediterranean Sea (3) and the Atlantic Ocean, in the latter case forming the invasive lionfish complex with P. volitans (4). REFERENCES 1. Kitsoulis CV, Papadogiannis V, Kristoffersen JB, Kaitetzidou E, Sterioti E, Tsigenopoulos CS, Manousaki T. (2023) Near-chromosome level genome assembly of devil firefish, Pterois miles. BioRxiv, ver. 6 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.01.10.523469 2. Kiriake A, Shiomi K. (2011) Some properties and cDNA cloning of proteinaceous toxins from two species of lionfish (Pterois antennata and Pterois volitans). Toxicon, 58(6-7):494–501. https://doi.org/10.1016/j.toxicon.2011.08.010 3. Katsanevakis S, et al. (2020) Un- published Mediterranean records of marine alien and cryptogenic species. BioInvasions Records, 9:165–182. https://doi.org/10.3391/bir.2020.9.2.01 4. Lyons TJ, Tuckett QM, Hill JE. (2019) Data quality and quantity for invasive species: A case study of the lionfishes. Fish and Fisheries, 20:748–759. https://doi.org/10.1111/faf.12374 | Near-chromosome level genome assembly of devil firefish, *Pterois miles* | Christos V. Kitsoulis, Vasileios Papadogiannis, Jon B. Kristoffersen, Elisavet Kaitetzidou, Aspasia Sterioti, Costas S. Tsigenopoulos, Tereza Manousaki | <p style="text-align: justify;">Devil firefish (<em>Pterois miles</em>), a member of Scorpaenidae family, is one of the most successful marine non-native species, dominating around the world, that was rapidly spread into the Mediterranean Sea, thr... | | Evolutionary genomics | Iker Irisarri | 2023-01-17 12:37:20 | ||
13 Jul 2024
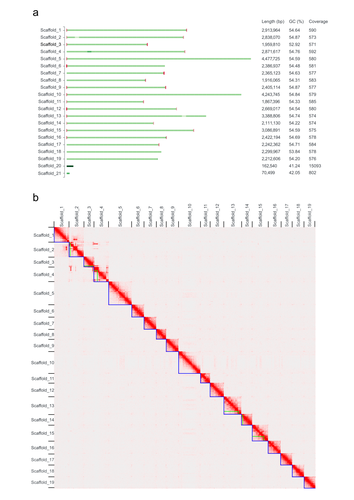
High quality genome assembly and annotation (v1) of the eukaryotic terrestrial microalga Coccomyxa viridis SAG 216-4Reference genome for the lichen-forming green alga Coccomyxa viridis SAG 216–4Recommended by Iker Irisarri based on reviews by Elisa Goldbecker, Fabian Haas and 2 anonymous reviewers
Green algae of the genus Coccomyxa (family Trebouxiophyceae) are extremely diverse in their morphology, habitat (i.e., in marine, freshwater, and terrestrial environments) and lifestyle, including free-living and mutualistic forms. Coccomyxa viridis (strain SAG 216–4) is a photobiont in the lichen Peltigera aphthosa, which was isolated in Switzerland more than 70 years ago (cf. SAG, the Culture Collection of Algae at the University of Göttingen, Germany). Despite the high diversity and plasticity in Coccomyxa, integrative taxonomic analyses led Darienko et al. (2015) to propose clear species boundaries. These authors also showed that symbiotic strains that form lichens evolved multiple times independently in Coccomyxa. Using state-of-the-art sequencing data and bioinformatic methods, including Pac-Bio HiFi and ONT long reads, as well as Hi-C chromatin conformation information, Kraege et al. (2024) generated a high-quality genome assembly for the Coccomyxa viridis strain SAG 216–4. They reconstructed 19 complete nuclear chromosomes, flanked by telomeric regions, totaling 50.9 Mb, plus the plastid and mitochondrial genomes. The performed quality controls leave no doubt of the high quality of the genome assemblies and structural annotations. An interesting observation is the lack of conserved synteny with the close relative Coccomyxa subellipsoidea, but further comparative studies with additional Coccomyxa strains will be required to grasp the genomic evolution in this genus of green algae. This project is framed within the ERGA pilot project, which aims to establish a pan-European genomics infrastructure and contribute to cataloging genomic biodiversity and producing resources that can inform conservation strategies (Formenti et al. 2022). This complete reference genome represents an important step towards this goal, in addition to contributing to future genomic analyses of Coccomyxa more generally.
References Darienko T, Gustavs L, Eggert A, Wolf W, Pröschold T (2015) Evaluating the species boundaries of green microalgae (Coccomyxa, Trebouxiophyceae, Chlorophyta) using integrative taxonomy and DNA barcoding with further implications for the species identification in environmental samples. PLOS ONE, 10, e0127838. https://doi.org/10.1371/journal.pone.0127838 Formenti G, Theissinger K, Fernandes C, Bista I, Bombarely A, Bleidorn C, Ciofi C, Crottini A, Godoy JA, Höglund J, Malukiewicz J, Mouton A, Oomen RA, Paez S, Palsbøll PJ, Pampoulie C, Ruiz-López MJ, Svardal H, Theofanopoulou C, de Vries J, Waldvogel A-M, Zhang G, Mazzoni CJ, Jarvis ED, Bálint M, European Reference Genome Atlas Consortium (2022) The era of reference genomes in conservation genomics. Trends in Ecology & Evolution, 37, 197–202. https://doi.org/10.1016/j.tree.2021.11.008 Kraege A, Chavarro-Carrero EA, Guiglielmoni N, Schnell E, Kirangwa J, Heilmann-Heimbach S, Becker K, Köhrer K, WGGC Team, DeRGA Community, Schiffer P, Thomma BPHJ, Rovenich H (2024) High quality genome assembly and annotation (v1) of the eukaryotic terrestrial microalga Coccomyxa viridis SAG 216-4. bioRxiv, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.07.11.548521 | High quality genome assembly and annotation (v1) of the eukaryotic terrestrial microalga *Coccomyxa viridis* SAG 216-4 | Anton Kraege, Edgar Chavarro-Carrero, Nadège Guiglielmoni, Eva Schnell, Joseph Kirangwa, Stefanie Heilmann-Heimbach, Kerstin Becker, Karl Köhrer, Philipp Schiffer, Bart P. H. J. Thomma, Hanna Rovenich | <p>Unicellular green algae of the genus Coccomyxa are recognized for their worldwide distribution and ecological versatility. Most species described to date live in close association with various host species, such as in lichen associations. Howev... | | ERGA Pilot | Iker Irisarri | 2023-11-09 11:54:43 | ||
11 May 2024
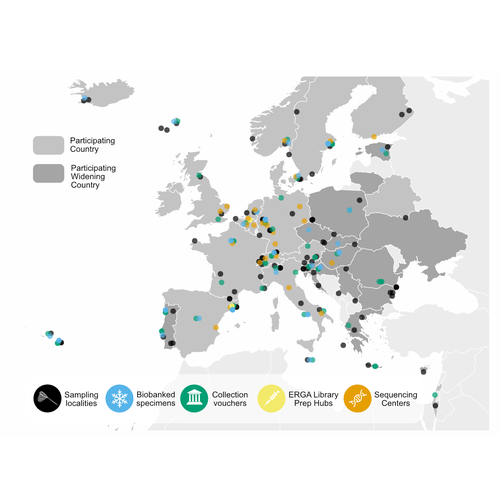
The European Reference Genome Atlas: piloting a decentralised approach to equitable biodiversity genomicsInformed Choices, Cohesive Future: Decisions and Recommendations for ERGARecommended by Jitendra Narayan based on reviews by Justin Ideozu and Eric Crandall
The European Reference Genome Atlas (ERGA) (Mc Cartney et al, 2024, Mazzoni et al, 2023) demonstrates the collaborative spirit and intellectual abilities of researchers from 33 European countries. This ambitious project, which is part of the Earth BioGenome Project (Lewin et al., 2018) Phase II, has embarked on an unprecedented mission: to decipher the genetic makeup of 150,000 species over a span of four years. At the heart of ERGA is a decentralized pilot infrastructure specifically built to assist the production of high-quality reference genomes. This structure acts as a scaffold for the massive task of genome sequencing, giving the necessary framework to manage the complexity of genomic research. The research paper under consideration offers a comprehensive narrative of ERGA's evolution, outlining both successes and challenges encountered along the road. One of the most significant issues addressed in the manuscript is the equitable distribution of resources and expertise among participating laboratories and countries. In a project of this magnitude, it is critical to leverage the pooled talents and capacities of researchers from across Europe. ERGA's pan-European network promotes communications and collaboration, creating an environment in which knowledge flows freely and barriers are overcome. This adoption of strong coordination and communication tactics will be essential to ERGA's success. Scientific collaboration depends on efficient communication channels because they allow researchers to share resources, collaborate on new initiatives, and exchange ideas. Through a diverse range of gatherings, courses, and virtual discussion boards, ERGA fosters an environment of transparency and cooperation among members, enabling scientists to overcome challenges and make significant discoveries. The importance ERGA places on training and information transfer programmes is a pillar of its strategy. Understanding the importance of capacity development, ERGA invests in providing researchers with the knowledge and abilities necessary for effectively navigating the complicated terrain of genomic research. A wide range of subjects are covered in training programmes (Larivière et al. 2023), from sample preparation and collection to data processing methods and sequencing technology. Through the development of a group of highly qualified experts, ERGA creates the foundation for continued advancement and creativity in the genomics sector. This manuscript also covers in detail the technological workflows and sequencing techniques used in ERGA's pilot infrastructure. With the aid of cutting-edge sequencing technologies based on both long-read and short-read sequencing, they are working to unravel the complex structure of the genetic code with a level of accuracy and precision never before possible. To guarantee the accuracy of genetic data and prevent mistakes and flaws that can jeopardize the findings' integrity, quality control methods are put in place. Despite having a focus on genome sequencing due to its technological complexities, ERGA also remains firm in its dedication to metadata collection and sample validation. Metadata serves as a critical link between raw genetic data and useful scientific insights, giving necessary context and allowing researchers to draw practical findings from their investigations. Sample validation approaches improve the reliability and reproducibility of the results, providing users confidence in the quality of the genetic data provided by ERGA. Looking ahead, ERGA envisions its decentralized infrastructure serving as a model for global collaborative research efforts. By embracing diversity, encouraging cooperation, and pushing for open access to data and resources, ERGA hopes to catalyze scientific discovery and generate positive change in the field of biodiversity genomics. ERGA aims to promote a more equitable and sustainable future for all by ongoing interaction with stakeholders, intensive outreach and education activities, and policy change advocacy. In addition to its immediate goals, ERGA considers the long-term implications of its work. As genomic technology progresses, the potential application of high-quality reference genomes will continue to grow. From informing conservation efforts and illuminating evolutionary histories to revolutionizing healthcare and agriculture, it is likely that ERGA's contributions will have far-reaching consequences for people and the planet as a whole. Furthermore, ERGA understands the importance of interdisciplinary collaboration in addressing the difficult challenges of the twenty-first century. ERGA aims to integrate genetic research into larger initiatives to promote sustainability and biodiversity conservation by forming relationships with stakeholders from other areas, such as policymakers, conservationists, and indigenous groups. Through shared knowledge and community action, ERGA seeks to create a future in which mankind coexists peacefully with the natural world, guided by a thorough grasp of its genetic legacy and ecological interconnectivity. Finally, the manuscript exemplifies ERGA's collaborative ambitions and achievements, capturing the spirit of creativity and collaboration that defines this ground-breaking effort. As ERGA continues to push the boundaries of genetic research, it remains dedicated to scientific excellence, inclusivity, and the quest of knowledge for the benefit of society. I wholeheartedly recommend the publication of this groundbreaking initiative, offering my enthusiastic endorsement for its valuable contribution to the scientific community. References Lewin, H. A., Robinson, G. E., Kress, W. J., Baker, W. J., Coddington, J., Crandall, K. A., Durbin, R., Edwards, S. V., Forest, F., Gilbert, M. T. P., Goldstein, M. M., Grigoriev, I. V., Hackett, K. J., Haussler, D., Jarvis, E. D., Johnson, W. E., Patrinos, A., Richards, S., Castilla-Rubio, J. C., … Zhang, G. (2018). Earth BioGenome Project: Sequencing life for the future of life. Proceedings of the National Academy of Sciences, 115(17), 4325–4333. https://doi.org/10.1073/pnas.1720115115 Mazzoni, C. J., Claudio, C.i, Waterhouse, R. M. (2023). Biodiversity: an atlas of European reference genomes. Nature 619 : 252-252. https://doi.org/10.1038/d41586-023-02229-w Mc Cartney, A. M., Formenti, G., Mouton, A., Panis, D. de, Marins, L. S., Leitão, H. G., Diedericks, G., Kirangwa, J., Morselli, M., Salces-Ortiz, J., Escudero, N., Iannucci, A., Natali, C., Svardal, H., Fernández, R., Pooter, T. de, Joris, G., Strazisar, M., Wood, J., … Mazzoni, C. J. (2024). The European Reference Genome Atlas: piloting a decentralised approach to equitable biodiversity genomics. bioRxiv, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.09.25.559365 | The European Reference Genome Atlas: piloting a decentralised approach to equitable biodiversity genomics | Ann M Mc Cartney, Giulio Formenti, Alice Mouton, Claudio Ciofi, Robert M Waterhouse, Camila J Mazzoni, Diego De Panis, Luisa S Schlude Marins, Henrique G Leitao, Genevieve Diedericks, Joseph Kirangwa, Marco Morselli, Judit Salces, Nuria Escudero, ... | <p>English: A global genome database of all of Earth's species diversity could be a treasure trove of scientific discoveries. However, regardless of the major advances in genome sequencing technologies, only a tiny fraction of species have genomic... | | Bioinformatics, ERGA Pilot | Jitendra Narayan | Justin Ideozu, Eric Crandall | 2023-10-01 01:03:58 | |
07 Sep 2023
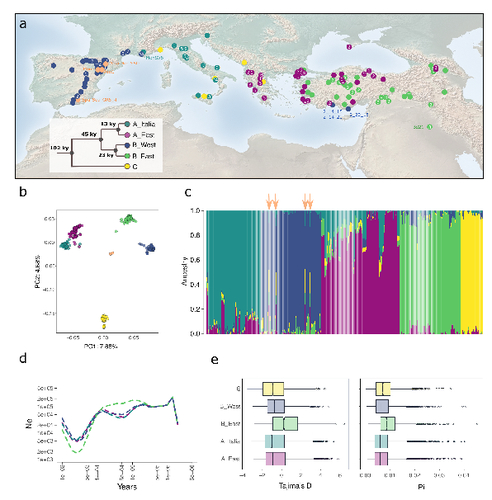
The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological nichesNatural variation and adaptation in Brachypodium distachyonRecommended by Josep Casacuberta based on reviews by Thibault Leroy and 1 anonymous reviewerIdentifying the genetic factors that allow plant adaptation is a major scientific question that is particularly relevant in the face of the climate change that we are already experiencing. To address this, it is essential to have genetic information on a high number of accessions (i.e., plants registered with unique accession numbers) growing under contrasting environmental conditions. There is already an important number of studies addressing these issues in the plant Arabidopsis thaliana, but there is a need to expand these analyses to species that play key roles in wild ecosystems and are close to very relevant crops, as is the case of grasses. The work of Minadakis, Roulin and co-workers (1) presents a Brachypodium distachyon panel of 332 fully sequences accessions that covers the whole species distribution across a wide range of bioclimatic conditions, which will be an invaluable tool to fill this gap. In addition, the authors use this data to start analyzing the population structure and demographic history of this plant, suggesting that the species experienced a shift of its distribution following the Last Glacial Maximum, which may have forced the species into new habitats. The authors also present a modeling of the niches occupied by B. distachyon together with an analysis of the genetic clades found in each of them, and start analyzing the different adaptive loci that may have allowed the species’ expansion into different bioclimatic areas. In addition to the importance of the resources made available by the authors for the scientific community, the analyses presented are well done and carefully discussed, and they highlight the potential of these new resources to investigate the genetic bases of plant adaptation. References 1. Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin. The demographic history of the wild crop relative Brachypodium distachyon is shaped by distinct past and present ecological niches. bioRxiv, 2023.06.01.543285, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.01.543285 | The demographic history of the wild crop relative *Brachypodium distachyon* is shaped by distinct past and present ecological niches | Nikolaos Minadakis, Hefin Williams, Robert Horvath, Danka Caković, Christoph Stritt, Michael Thieme, Yann Bourgeois, Anne C. Roulin | <p style="text-align: justify;">Closely related to economically important crops, the grass <em>Brachypodium distachyon</em> has been originally established as a pivotal species for grass genomics but more recently flourished as a model for develop... | | Evolutionary genomics, Functional genomics, Plants, Population genomics | Josep Casacuberta | 2023-06-14 15:28:30 | ||
15 Jan 2024
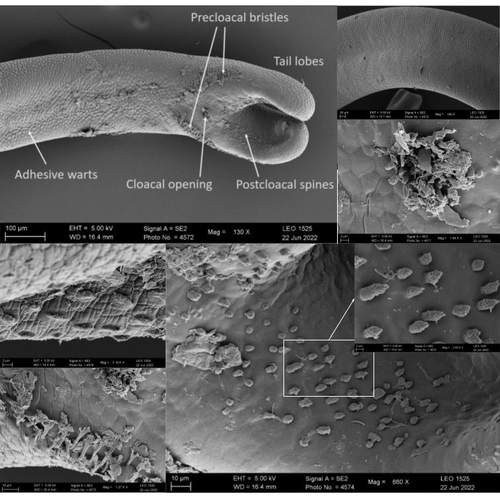
The genome sequence of the Montseny horsehair worm, Gordionus montsenyensis sp. nov., a key resource to investigate Ecdysozoa evolutionEmbarking on a novel journey in Metazoa evolution through the pioneering sequencing of a key underrepresented lineageRecommended by Juan C. Opazo based on reviews by Gonzalo Riadi and 2 anonymous reviewers
Whole genome sequences are revolutionizing our understanding across various biological fields. They not only shed light on the evolution of genetic material but also uncover the genetic basis of phenotypic diversity. The sequencing of underrepresented lineages, such as the one presented in this study, is of critical importance. It is crucial in filling significant gaps in our understanding of Metazoa evolution. Despite the wealth of genome sequences in public databases, it is crucial to acknowledge that some lineages across the Tree of Life are underrepresented or absent. This research represents a significant step towards addressing this imbalance, contributing to the collective knowledge of the global scientific community. In this genome note, as part of the European Reference Genome Atlas pilot effort to generate reference genomes for European biodiversity (Mc Cartney et al. 2023), Klara Eleftheriadi and colleagues (Eleftheriadi et al. 2023) make a significant effort to add a genome sequence of an unrepresented group in the animal Tree of Life. More specifically, they present a taxonomic description and chromosome-level genome assembly of a newly described species of horsehair worm (Gordionus montsenyensis). Their sequence methodology gave rise to an assembly of 396 scaffolds totaling 288 Mb, with an N50 value of 64.4 Mb, where 97% of this assembly is grouped into five pseudochromosomes. The nuclear genome annotation predicted 10,320 protein-coding genes, and they also assembled the circular mitochondrial genome into a 15-kilobase sequence. The selection of a species representing the phylum Nematomorpha, a group of parasitic organisms belonging to the Ecdysozoa lineage, is good, since today, there is only one publicly available genome for this animal phylum (Cunha et al. 2023). Interestingly, this article shows, among other things, that the species analyzed has lost ∼30% of the universal Metazoan genes. Efforts, like the one performed by Eleftheriadi and colleagues, are necessary to gain more insights, for example, on the evolution of this massive gene lost in this group of animals.
Cunha, T. J., de Medeiros, B. A. S, Lord, A., Sørensen, M. V., and Giribet, G. (2023). Rampant Loss of Universal Metazoan Genes Revealed by a Chromosome-Level Genome Assembly of the Parasitic Nematomorpha. Current Biology, 33 (16): 3514–21.e4. https://doi.org/10.1016/j.cub.2023.07.003 Eleftheriadi, K., Guiglielmoni, N., Salces-Ortiz, J., Vargas-Chavez, C., Martínez-Redondo, G. I., Gut, M., Flot, J.-F., Schmidt-Rhaesa, A., and Fernández, R. (2023). The Genome Sequence of the Montseny Horsehair worm, Gordionus montsenyensis sp. Nov., a Key Resource to Investigate Ecdysozoa Evolution. bioRxiv, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.26.546503 Mc Cartney, A. M., Formenti, G., Mouton, A., De Panis, D., Marins, L. S., Leitão, H. G., Diedericks, G., et al. (2023). The European Reference Genome Atlas: Piloting a Decentralised Approach to Equitable Biodiversity Genomics. bioRxiv. https://doi.org/10.1101/2023.09.25.559365 | The genome sequence of the Montseny horsehair worm, *Gordionus montsenyensis* sp. nov., a key resource to investigate Ecdysozoa evolution | Eleftheriadi Klara, Guiglielmoni Nadège, Salces-Ortiz Judit, Vargas-Chávez Carlos, Martínez-Redondo Gemma I, Gut Marta, Flot Jean François, Schmidt-Rhaesa Andreas, Fernández Rosa | <p>Nematomorpha, also known as Gordiacea or Gordian worms, are a phylum of parasitic organisms that belong to the Ecdysozoa, a clade of invertebrate animals characterized by molting. They are one of the less scientifically studied animal phyla, an... | | ERGA Pilot | Juan C. Opazo | 2023-06-29 10:31:36 | ||
23 Aug 2022

A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomicsGoat ancient DNA analysis unveils a new lineage that may have hybridized with domestic goatsRecommended by Laura Botigué based on reviews by Torsten Günther and 1 anonymous reviewerThe genomic analysis of ancient remains has revolutionized the study of the past over the last decade. On top of the discoveries related to human evolution, plant and animal archaeogenomics has been used to gain new insights into the domestication process and the dispersal of domestic forms. In this study, Daly and colleagues analyse the genomic data from seven goat specimens from the Epipalaeolithic recovered from the Direkli Cave in the Taurus Mountains in southern Turkey. They also generate new genomic data from Capra lineages across the phylogeny, contributing to the availability of genomic resources for this genus. Analysis of the ancient remains is compared to modern genomic variability and sheds light on the complexity of the Tur wild Capra lineages and their relationship with domestic goats and their wild ancestors. Authors find that during the Late Pleistocene in the Taurus Mountains wild goats from the Tur lineage, today restricted to the Caucasus region, were not rare and cohabited with Bezoar, the wild goats that are the ancestors of domestic goats. They identify the Direkli Cave specimens as a lineage separate from the A modified D statistic, Dex, is developed to examine the contribution of the ancient Tur lineage in domestic goats through time and space. Dex measures the relative degree of allele sharing, derived specifically in a selected genome or group of genomes, and may have some utility in genera with complex admixture histories or admixture from ghost lineages. Results confirm that Neolithic European goat had an excess of allele sharing with this ancient Tur lineage, something that is absent in contemporary goats eastwards or in modern goats. Interspecific gene flow is not uncommon among mammals, but the case of Capra has the additional motivation of understanding the origins of the domestic species. This work uncovers an ancient Tur lineage that is different from the modern ones and is additionally found in another geographic area. Furthermore, evidence shows that this ancient lineage exhibits substantial amounts of allele sharing with the wild ancestor of the domestic goat, but also with the Neolithic Eurasian domestic goats, highlighting the complexity of the domestication process. This work has also important implications in understanding the effect of over-hunting and habitat disruption during the Anthropocene on the evolution of the Capra genus. The availability of more ancient specimens and better coverage of the modern genomic variability can help quantifying the lineages that went lost and identify the causes of their extinction. This work is limited by the current availability of whole genomes from modern Capra specimens, but pieces of evidence as well that an effort is needed to obtain more genomic data from ancient goats from different geographic ranges to determine to what extent these lineages contributed to goat domestication. References Daly KG, Arbuckle BS, Rossi C, Mattiangeli V, Lawlor PA, Mashkour M, Sauer E, Lesur J, Atici L, Cevdet CM and Bradley DG (2022) A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomics. bioRxiv, 2022.04.08.487619, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.08.487619 | A novel lineage of the Capra genus discovered in the Taurus Mountains of Turkey using ancient genomics | Kevin G. Daly, Benjamin S. Arbuckle, Conor Rossi, Valeria Mattiangeli, Phoebe A. Lawlor, Marjan Mashkour, Eberhard Sauer, Joséphine Lesur, Levent Atici, Cevdet Merih Erek, Daniel G. Bradley | <p>Direkli Cave, located in the Taurus Mountains of southern Turkey, was occupied by Late Epipaleolithic hunters-gatherers for the seasonal hunting and processing of game including large numbers of wild goats. We report genomic data from new and p... | | Evolutionary genomics, Population genomics, Vertebrates | Laura Botigué | 2022-04-15 12:05:47 | ||
12 Jul 2022

Chromosome-level genome assembly and annotation of two lineages of the ant Cataglyphis hispanica: steppingstones towards genomic studies of hybridogenesis and thermal adaptation in desert antsA genomic resource for ants, and moreRecommended by Nadia Ponts based on reviews by Isabel Almudi and Nicolas NègreThe ant species Cataglyphis hispanica is remarkably well adapted to arid habitats of the Iberian Peninsula where two hybridogenetic lineages co-occur, i.e., queens mating with males from the other lineage produce only non-reproductive hybrid workers whereas reproductive males and females are produced by parthenogenesis (Lavanchy and Schwander, 2019). For these two reasons, the genomes of these lineages, Chis1 and Chis2, are potential gold mines to explore the genetic bases of thermal adaptation and the evolution of alternative reproductive modes. Nowadays, sequencing technology enables assembling all kinds of genomes provided genomic DNA can be extracted. More difficult to achieve is high-quality assemblies with just as high-quality annotations that are readily available to the community to be used and re-used at will (Byrne et al., 2019; Salzberg, 2019). The challenge was successfully completed by Darras and colleagues, the generated resource being fully available to the community, including scripts and command lines used to obtain the proposed results. The authors particularly describe that lineage Chis2 has 27 chromosomes, against 26 or 27 for lineage Chis1, with a Robertsonian translocation identified by chromosome conformation capture (Duan et al., 2010, 2012) in the two Queens sequenced. Transcript-supported gene annotation provided 11,290 high-quality gene models. In addition, an ant-tailored annotation pipeline identified 56 different families of repetitive elements in both Chis1 and Chis2 lineages of C. hispanica spread in a little over 15 % of the genome. Altogether, the genomes of Chis1 and Chis2 are highly similar and syntenic, with some level of polymorphism raising questions about their evolutionary story timeline. In particular, the uniform distribution of polymorphisms along the genomes shakes up a previous hypothesis of hybridogenetic lineage pairs determined by ancient non-recombining regions (Linksvayer, Busch and Smith, 2013). I recommend this paper because the science behind is both solid and well-explained. The provided resource is of high quality, and accompanied by a critical exploration of the perspectives brought by the results. These genomes are excellent resources to now go further in exploring the possible events at the genome level that accompanied the remarkable thermal adaptation of the ants Cataglyphis, as well as insights into the genetics of hybridogenetic lineages. Beyond the scientific value of the resources and insights provided by the work performed, I also recommend this article because it is an excellent example of Open Science (Allen and Mehler, 2019; Sarabipour et al., 2019), all data methods and tools being fully and easily accessible to whoever wants/needs it. References Allen C, Mehler DMA (2019) Open science challenges, benefits and tips in early career and beyond. PLOS Biology, 17, e3000246. https://doi.org/10.1371/journal.pbio.3000246 Byrne A, Cole C, Volden R, Vollmers C (2019) Realizing the potential of full-length transcriptome sequencing. Philosophical Transactions of the Royal Society B: Biological Sciences, 374, 20190097. https://doi.org/10.1098/rstb.2019.0097 Darras H, de Souza Araujo N, Baudry L, Guiglielmoni N, Lorite P, Marbouty M, Rodriguez F, Arkhipova I, Koszul R, Flot J-F, Aron S (2022) Chromosome-level genome assembly and annotation of two lineages of the ant Cataglyphis hispanica: stepping stones towards genomic studies of hybridogenesis and thermal adaptation in desert ants. bioRxiv, 2022.01.07.475286, ver. 3 peer-reviewed and recommended by Peer community in Genomics. https://doi.org/10.1101/2022.01.07.475286 Duan Z, Andronescu M, Schutz K, Lee C, Shendure J, Fields S, Noble WS, Anthony Blau C (2012) A genome-wide 3C-method for characterizing the three-dimensional architectures of genomes. Methods, 58, 277–288. https://doi.org/10.1016/j.ymeth.2012.06.018 Duan Z, Andronescu M, Schutz K, McIlwain S, Kim YJ, Lee C, Shendure J, Fields S, Blau CA, Noble WS (2010) A three-dimensional model of the yeast genome. Nature, 465, 363–367. https://doi.org/10.1038/nature08973 Lavanchy G, Schwander T (2019) Hybridogenesis. Current Biology, 29, R9–R11. https://doi.org/10.1016/j.cub.2018.11.046 Linksvayer TA, Busch JW, Smith CR (2013) Social supergenes of superorganisms: Do supergenes play important roles in social evolution? BioEssays, 35, 683–689. https://doi.org/10.1002/bies.201300038 Salzberg SL (2019) Next-generation genome annotation: we still struggle to get it right. Genome Biology, 20, 92. https://doi.org/10.1186/s13059-019-1715-2 Sarabipour S, Debat HJ, Emmott E, Burgess SJ, Schwessinger B, Hensel Z (2019) On the value of preprints: An early career researcher perspective. PLOS Biology, 17, e3000151. https://doi.org/10.1371/journal.pbio.3000151 | Chromosome-level genome assembly and annotation of two lineages of the ant Cataglyphis hispanica: steppingstones towards genomic studies of hybridogenesis and thermal adaptation in desert ants | Hugo Darras, Natalia de Souza Araujo, Lyam Baudry, Nadège Guiglielmoni, Pedro Lorite, Martial Marbouty, Fernando Rodriguez, Irina Arkhipova, Romain Koszul, Jean-François Flot, Serge Aron | <p style="text-align: justify;"><em>Cataglyphis</em> are thermophilic ants that forage during the day when temperatures are highest and sometimes close to their critical thermal limit. Several Cataglyphis species have evolved unusual reproductive ... | | Evolutionary genomics | Nadia Ponts | Nicolas Nègre, Isabel Almudi | 2022-01-13 16:47:30 | |
08 Nov 2022

Somatic mutation detection: a critical evaluation through simulations and reanalyses in oaksHow to best call the somatic mosaic tree?Recommended by Nicolas Bierne based on reviews by 2 anonymous reviewersAny multicellular organism is a molecular mosaic with some somatic mutations accumulated between cell lineages. Big long-lived trees have nourished this imaginary of a somatic mosaic tree, from the observation of spectacular phenotypic mosaics and also because somatic mutations are expected to potentially be passed on to gametes in plants (review in Schoen and Schultz 2019). The lower cost of genome sequencing now offers the opportunity to tackle the issue and identify somatic mutations in trees. However, when it comes to characterizing this somatic mosaic from genome sequences, things become much more difficult than one would think in the first place. What separates cell lineages ontogenetically, in cell division number, or in time? How to sample clonal cell populations? How do somatic mutations distribute in a population of cells in an organ or an organ sample? Should they be fixed heterozygotes in the sample of cells sequenced or be polymorphic? Do we indeed expect somatic mutations to be fixed? How should we identify and count somatic mutations? To date, the detection of somatic mutations has mostly been done with a single variant caller in a given study, and we have little perspective on how different callers provide similar or different results. Some studies have used standard SNP callers that assumed a somatic mutation is fixed at the heterozygous state in the sample of cells, with an expected allele coverage ratio of 0.5, and less have used cancer callers, designed to detect mutations in a fraction of the cells in the sample. However, standard SNP callers detect mutations that deviate from a balanced allelic coverage, and different cancer callers can have different characteristics that should affect their outcomes. In order to tackle these issues, Schmitt et al. (2022) conducted an extensive simulation analysis to compare different variant callers. Then, they reanalyzed two large published datasets on pedunculate oak, Quercus robur. The analysis of in silico somatic mutations allowed the authors to evaluate the performance of different variant callers as a function of the allelic fraction of somatic mutations and the sequencing depth. They found one of the seven callers to provide better and more robust calls for a broad set of allelic fractions and sequencing depths. The reanalysis of published datasets in oaks with the most effective cancer caller of the in silico analysis allowed them to identify numerous low-frequency mutations that were missed in the original studies. I recommend the study of Schmitt et al. (2022) first because it shows the benefit of using cancer callers in the study of somatic mutations, whatever the allelic fraction you are interested in at the end. You can select fixed heterozygotes if this is your ultimate target, but cancer callers allow you to have in addition a valuable overview of the allelic fractions of somatic mutations in your sample, and most do as well as SNP callers for fixed heterozygous mutations. In addition, Schmitt et al. (2022) provide the pipelines that allow investigating in silico data that should correspond to a given study design, encouraging to compare different variant callers rather than arbitrarily going with only one. We can anticipate that the study of somatic mutations in non-model species will increasingly attract attention now that multiple tissues of the same individual can be sequenced at low cost, and the study of Schmitt et al. (2022) paves the way for questioning and choosing the best variant caller for the question one wants to address. References Schoen DJ, Schultz ST (2019) Somatic Mutation and Evolution in Plants. Annual Review of Ecology, Evolution, and Systematics, 50, 49–73. https://doi.org/10.1146/annurev-ecolsys-110218-024955 Schmitt S, Leroy T, Heuertz M, Tysklind N (2022) Somatic mutation detection: a critical evaluation through simulations and reanalyses in oaks. bioRxiv, 2021.10.11.462798. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.10.11.462798 | Somatic mutation detection: a critical evaluation through simulations and reanalyses in oaks | Sylvain Schmitt, Thibault Leroy, Myriam Heuertz, Niklas Tysklind | <p style="text-align: justify;">1. Mutation, the source of genetic diversity, is the raw material of evolution; however, the mutation process remains understudied, especially in plants. Using both a simulation and reanalysis framework, we set out ... | | Bioinformatics, Plants | Nicolas Bierne | Anonymous, Anonymous | 2022-04-28 13:24:19 |




