
Latest recommendations

| Id | Title | Authors | Abstract | Picture▼ | Thematic fields | Recommender | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
24 Sep 2020

A rapid and simple method for assessing and representing genome sequence relatednessA quick alternative method for resolving bacterial taxonomy using short identical DNA sequences in genomes or metagenomesRecommended by B. Jesse Shapiro based on reviews by Gavin Douglas and 1 anonymous reviewerThe bacterial species problem can be summarized as follows: bacteria recombine too little, and yet too much (Shapiro 2019). References Arevalo P, VanInsberghe D, Elsherbini J, Gore J, Polz MF (2019) A Reverse Ecology Approach Based on a Biological Definition of Microbial Populations. Cell, 178, 820-834.e14. https://doi.org/10.1016/j.cell.2019.06.033 | A rapid and simple method for assessing and representing genome sequence relatedness | M Briand, M Bouzid, G Hunault, M Legeay, M Fischer-Le Saux, M Barret | <p>Coherent genomic groups are frequently used as a proxy for bacterial species delineation through computation of overall genome relatedness indices (OGRI). Average nucleotide identity (ANI) is a widely employed method for estimating relatedness ... | | Bioinformatics, Metagenomics | B. Jesse Shapiro | Gavin Douglas | 2019-11-07 16:37:56 | |
13 Jul 2022
Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codonsAn accident frozen in time: the ambiguous stop/sense genetic code of karyorelict ciliatesRecommended by Iker Irisarri based on reviews by Vittorio Boscaro and 2 anonymous reviewers based on reviews by Vittorio Boscaro and 2 anonymous reviewers
Several variations of the “universal” genetic code are known. Among the most striking are those where a codon can either encode for an amino acid or a stop signal depending on the context. Such ambiguous codes are known to have evolved in eukaryotes multiple times independently, particularly in ciliates – eight different codes have so far been discovered (1). We generally view such genetic codes are rare ‘variants’ of the standard code restricted to single species or strains, but this might as well reflect a lack of study of closely related species. In this study, Seah and co-authors (2) explore the possibility of codon reassignment in karyorelict ciliates closely related to Parduczia sp., which has been shown to contain an ambiguous genetic code (1). Here, single-cell transcriptomics are used, along with similar available data, to explore the possibility of codon reassignment across the diversity of Karyorelictea (four out of the six recognized families). Codon reassignments were inferred from their frequencies within conserved Pfam (3) protein domains, whereas stop codons were inferred from full-length transcripts with intact 3’-UTRs. Results show the reassignment of UAA and UAG stop codons to code for glutamine (Q) and the reassignment of the UGA stop codon into tryptophan (W). This occurs only within the coding sequences, whereas the end of transcription is marked by UGA as the main stop codon, and to a lesser extent by UAA. In agreement with a previous model proposed that explains the functioning of ambiguous codes (1,4), the authors observe a depletion of in-frame UGAs before the UGA codon that indicates the stop, thus avoiding premature termination of transcription. The inferred codon reassignments occur in all studied karyorelicts, including the previously studied Parduczia sp. Despite the overall clear picture, some questions remain. Data for two out of six main karyorelict lineages are so far absent and the available data for Cryptopharyngidae was inconclusive; the phylogenetic affinities of Cryptopharyngidae have also been questioned (5). This indicates the need for further study of this interesting group of organisms. As nicely discussed by the authors, experimental evidence could further strengthen the conclusions of this paper, including ribosome profiling, mass spectrometry – as done for Condylostoma (1) – or even direct genetic manipulation. The uniformity of the ambiguous genetic code across karyorelicts might at first seem dull, but when viewed in a phylogenetic context character distribution strongly suggest that this genetic code has an ancient origin in the karyorelict ancestor ~455 Ma in the Proterozoic (6). This ambiguous code is also not a rarity of some obscure species, but it is shared by ciliates that are very diverse and ecologically important. The origin of the karyorelict code is also intriguing. Adaptive arguments suggest that it could confer robustness to mutations causing premature stop codons. However, we lack evidence for ambiguous codes being linked to specific habitats of lifestyles that could account for it. Instead, the authors favor the neutral view of an ancient “frozen accident”, fixed stochastically simply because it did not pose a significant selective disadvantage. Once a stop codon is reassigned to an amino acid, it is increasingly difficult to revert this without the deleterious effect of prematurely terminating translation. At the end, the origin of the genetic code itself is thought to be a frozen accident too (7). References 1. Swart EC, Serra V, Petroni G, Nowacki M. Genetic codes with no dedicated stop codon: Context-dependent translation termination. Cell 2016;166: 691–702. https://doi.org/10.1016/j.cell.2016.06.020 2. Seah BKB, Singh A, Swart EC (2022) Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons. bioRxiv, 2022.04.12.488043. ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.12.488043 3. Mistry J, Chuguransky S, Williams L, Qureshi M, Salazar GA, Sonnhammer ELL, Tosatto SCE, Paladin L, Raj S, Richardson LJ, Finn RD, Bateman A. Pfam: The protein families database in 2021, Nuc Acids Res 2020;49: D412-D419. https://doi.org/10.1093/nar/gkaa913 4. Alkalaeva E, Mikhailova T. Reassigning stop codons via translation termination: How a few eukaryotes broke the dogma. Bioessays. 2017;39. https://doi.org/10.1002/bies.201600213 5. Xu Y, Li J, Song W, Warren A. Phylogeny and establishment of a new ciliate family, Wilbertomorphidae fam. nov. (Ciliophora, Karyorelictea), a highly specialized taxon represented by Wilbertomorpha colpoda gen. nov., spec. nov. J Eukaryot Microbiol. 2013;60: 480–489. https://doi.org/10.1111/jeu.12055 6. Fernandes NM, Schrago CG. A multigene timescale and diversification dynamics of Ciliophora evolution. Mol Phylogenet Evol. 2019;139: 106521. https://doi.org/10.1016/j.ympev.2019.106521 7. Crick FH. The origin of the genetic code. J Mol Biol. 1968;38: 367–379. https://doi.org/10.1016/0022-2836(68)90392-6 | Karyorelict ciliates use an ambiguous genetic code with context-dependent stop/sense codons | Brandon Kwee Boon Seah, Aditi Singh, Estienne Carl Swart | <p style="text-align: justify;">In ambiguous stop/sense genetic codes, the stop codon(s) not only terminate translation but can also encode amino acids. Such codes have evolved at least four times in eukaryotes, twice among ciliates (<em>Condylost... | | Bioinformatics, Evolutionary genomics | Iker Irisarri | 2022-05-02 11:06:10 | ||
15 Sep 2022
EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotesEukProt enables reproducible Eukaryota-wide protein sequence analysesRecommended by Gavin Douglas based on reviews by 2 anonymous reviewers
Comparative genomics is a general approach for understanding how genomes differ, which can be considered from many angles. For instance, this approach can delineate how gene content varies across organisms, which can lead to novel hypotheses regarding what those organisms do. It also enables investigations into the sequence-level divergence of orthologous DNA, which can provide insight into how evolutionary forces differentially shape genome content and structure across lineages. Burki F, Roger AJ, Brown MW, Simpson AGB (2020) The New Tree of Eukaryotes. Trends in Ecology & Evolution, 35, 43–55. https://doi.org/10.1016/j.tree.2019.08.008 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE, Bouwman J, Brookes AJ, Clark T, Crosas M, Dillo I, Dumon O, Edmunds S, Evelo CT, Finkers R, Gonzalez-Beltran A, Gray AJG, Groth P, Goble C, Grethe JS, Heringa J, ’t Hoen PAC, Hooft R, Kuhn T, Kok R, Kok J, Lusher SJ, Martone ME, Mons A, Packer AL, Persson B, Rocca-Serra P, Roos M, van Schaik R, Sansone S-A, Schultes E, Sengstag T, Slater T, Strawn G, Swertz MA, Thompson M, van der Lei J, van Mulligen E, Velterop J, Waagmeester A, Wittenburg P, Wolstencroft K, Zhao J, Mons B (2016) The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18 | EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes | Daniel J. Richter, Cédric Berney, Jürgen F. H. Strassert, Yu-Ping Poh, Emily K. Herman, Sergio A. Muñoz-Gómez, Jeremy G. Wideman, Fabien Burki, Colomban de Vargas | <p style="text-align: justify;">EukProt is a database of published and publicly available predicted protein sets selected to represent the breadth of eukaryotic diversity, currently including 993 species from all major supergroups as well as orpha... | | Bioinformatics, Evolutionary genomics | Gavin Douglas | 2022-06-08 14:19:28 | ||
20 Jul 2021
Genetic mapping of sex and self-incompatibility determinants in the androdioecious plant Phillyrea angustifoliaIdentification of distinct YX-like loci for sex determination and self-incompatibility in an androdioecious shrubRecommended by Tatiana Giraud and Ricardo C. Rodríguez de la Vega based on reviews by 2 anonymous reviewersA wide variety of systems have evolved to control mating compatibility in sexual organisms. Their genetic determinism and the factors controlling their evolution represent fascinating questions in evolutionary biology and genomics. The plant Phillyrea angustifolia (Oleaeceae family) represents an exciting model organism, as it displays two distinct and rare mating compatibility systems [1]: 1) males and hermaphrodites co-occur in populations of this shrub (a rare system called androdioecy), while the evolution and maintenance of purely hermaphroditic plants or mixtures of females and hermaphrodites (a system called gynodioecy) are easier to explain [2]; 2) a homomorphic diallelic self-incompatibility system acts in hermaphrodites, while such systems are usually multi-allelic, as rare alleles are advantageous, being compatible with all other alleles. Previous analyses of crosses brought some interesting answers to these puzzles, showing that males benefit from the ability to mate with all hermaphrodites regardless of their allele at the self-incompatibility system, and suggesting that both sex and self incompatibility are determined by XY-like genetic systems, i.e. with each a dominant allele; homozygotes for a single allele and heterozygotes therefore co-occur in natural populations at both sex and self-incompatibility loci [3]. Here, Carré et al. used genotyping-by-sequencing to build a genome linkage map of P. angustifolia [4]. The elegant and original use of a probabilistic model of segregating alleles (implemented in the SEX-DETector method) allowed to identify both the sex and self-incompatibility loci [4], while this tool was initially developed for detecting sex-linked genes in species with strictly separated sexes (dioecy) [5]. Carré et al. [4] confirmed that the sex and self-incompatibility loci are located in two distinct linkage groups and correspond to XY-like systems. A comparison with the genome of the closely related Olive tree indicated that their self-incompatibility systems were homologous. Such a XY-like system represents a rare genetic determination mechanism for self-incompatibility and has also been recently found to control mating types in oomycetes [6]. This study [4] paves the way for identifying the genes controlling the sex and self-incompatibility phenotypes and for understanding why and how self-incompatibility is only expressed in hermaphrodites and not in males. It will also be fascinating to study more finely the degree and extent of genomic differentiation at these two loci and to assess whether recombination suppression has extended stepwise away from the sex and self-incompatibility loci, as can be expected under some hypotheses, such as the sheltering of deleterious alleles near permanently heterozygous alleles [7]. Furthermore, the co-occurrence in P. angustifolia of sex and mating types can contribute to our understanding of the factor controlling their evolution [8]. References [1] Saumitou-Laprade P, Vernet P, Vassiliadis C, Hoareau Y, Magny G de, Dommée B, Lepart J (2010) A Self-Incompatibility System Explains High Male Frequencies in an Androdioecious Plant. Science, 327, 1648–1650. https://doi.org/10.1126/science.1186687 [2] Pannell JR, Voillemot M (2015) Plant Mating Systems: Female Sterility in the Driver’s Seat. Current Biology, 25, R511–R514. https://doi.org/10.1016/j.cub.2015.04.044 [3] Billiard S, Husse L, Lepercq P, Godé C, Bourceaux A, Lepart J, Vernet P, Saumitou-Laprade P (2015) Selfish male-determining element favors the transition from hermaphroditism to androdioecy. Evolution, 69, 683–693. https://doi.org/10.1111/evo.12613 [4] Carre A, Gallina S, Santoni S, Vernet P, Gode C, Castric V, Saumitou-Laprade P (2021) Genetic mapping of sex and self-incompatibility determinants in the androdioecious plant Phillyrea angustifolia. bioRxiv, 2021.04.15.439943, ver. 7 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2021.04.15.439943 [5] Muyle A, Käfer J, Zemp N, Mousset S, Picard F, Marais GA (2016) SEX-DETector: A Probabilistic Approach to Study Sex Chromosomes in Non-Model Organisms. Genome Biology and Evolution, 8, 2530–2543. https://doi.org/10.1093/gbe/evw172 [6] Dussert Y, Legrand L, Mazet ID, Couture C, Piron M-C, Serre R-F, Bouchez O, Mestre P, Toffolatti SL, Giraud T, Delmotte F (2020) Identification of the First Oomycete Mating-type Locus Sequence in the Grapevine Downy Mildew Pathogen, Plasmopara viticola. Current Biology, 30, 3897-3907.e4. https://doi.org/10.1016/j.cub.2020.07.057 [7] Jay P, Tezenas E, Giraud T (2021) A deleterious mutation-sheltering theory for the evolution of sex chromosomes and supergenes. bioRxiv, 2021.05.17.444504. https://doi.org/10.1101/2021.05.17.444504 [8] Billiard S, López-Villavicencio M, Devier B, Hood ME, Fairhead C, Giraud T (2011) Having sex, yes, but with whom? Inferences from fungi on the evolution of anisogamy and mating types. Biological Reviews, 86, 421–442. https://doi.org/10.1111/j.1469-185X.2010.00153.x | Genetic mapping of sex and self-incompatibility determinants in the androdioecious plant Phillyrea angustifolia | Amelie Carre, Sophie Gallina, Sylvain Santoni, Philippe Vernet, Cecile Gode, Vincent Castric, Pierre Saumitou-Laprade | <p style="text-align: justify;">The diversity of mating and sexual systems in angiosperms is spectacular, but the factors driving their evolution remain poorly understood. In plants of the Oleaceae family, an unusual self-incompatibility (SI) syst... | | Evolutionary genomics, Plants | Tatiana Giraud | 2021-05-04 10:37:26 | ||
01 May 2024
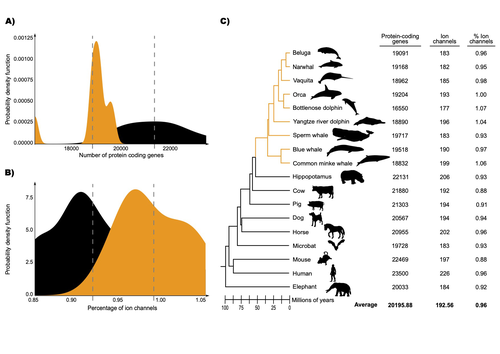
Evolution of ion channels in cetaceans: A natural experiment in the tree of lifePositive selection acted upon cetacean ion channels during the aquatic transitionRecommended by Gavin Douglas based on reviews by 2 anonymous reviewers
The transition of cetaceans (whales, dolphins, and porpoises) from terrestrial to aquatic lifestyles is a striking example of natural selection driving major phenotypic changes (Figure 1). For instance, cetaceans have evolved the ability to withstand high pressure and to store oxygen for long periods, among other adaptations (Das et al. 2023). Many phenotypic changes, such as shifts in organ structure, have been well-characterized through fossils (Thewissen et al. 2009). Although such phenotypic transitions are now well understood, we have only a partial understanding of the underlying genetic mechanisms. Scanning for signatures of adaptation in genes related to phenotypes of interest is one approach to better understand these mechanisms. This was the focus of Uribe and colleagues’ (2024) work, who tested for such signatures across cetacean protein-coding genes.
Figure 1: The skeletons of Ambulocetus (an early whale; top) and Pakicetus (the earliest known cetacean, which lived about 50 million years ago; bottom). Copyright: J. G. M. Thewissen. Displayed here with permission from the copyright holder.
The authors were specifically interested in investigating the evolution of ion channels, as these proteins play fundamental roles in physiological processes. An important aspect of their work was to develop a bioinformatic pipeline to identify orthologous ion channel genes across a set of genomes. After applying their bioinformatic workflow to 18 mammalian species (including nine cetaceans), they conducted tests to find out whether these genes showed signatures of positive selection in the cetacean lineage. For many ion channel genes, elevated ratios of non-synonymous to synonymous substitution rates were detected (for at least a subset of sites, and not necessarily the entire coding region of the genes). The genes concerned were enriched for several functions, including heart and nervous system-related phenotypes. One top gene hit among the putatively selected genes was SCN5A, which encodes a sodium channel expressed in the heart. Interestingly, the authors noted a specific amino acid replacement, which is associated with sensitivity to the toxin tetrodotoxin in other lineages. This substitution appears to have occurred in the common ancestor of toothed whales, and then was reversed in the ancestor of bottlenose dolphins. The authors describe known bottlenose dolphin interactions with toxin-producing pufferfish that could result in high tetrodotoxin exposure, and thus perhaps higher selection for tetrodotoxin resistance. Although this observation is intriguing, the authors emphasize it requires experimental confirmation. The authors also recapitulated the previously described observation (Yim et al. 2014; Huelsmann et al. 2019) that cetaceans have fewer protein-coding genes compared to terrestrial mammals, on average. This signal has previously been hypothesized to partially reflect adaptive gene loss. For example, specific gene loss events likely decreased the risk of developing blood clots while diving (Huelsmann et al. 2019). Uribe and colleagues also considered overall gene turnover rate, which encompasses gene copy number variation across lineages, and found the cetacean gene turnover rate to be three times higher than that of terrestrial mammals. Finally, they found that cetaceans have a higher proportion of ion channel genes (relative to all protein-coding genes in a genome) compared to terrestrial mammals. Similar investigations of the relative non-synonymous to synonymous substitution rates across cetacean and terrestrial mammal orthologs have been conducted previously, but these have primarily focused on dolphins as the sole cetacean representative (McGowen et al. 2012; Nery et al. 2013; Sun et al. 2013). These projects have also been conducted across a large proportion of orthologous genes, rather than a subset with a particular function. Performing proteome-wide investigations can be valuable in that they summarize the genome-wide signal, but can suffer from a high multiple testing burden. More generally, investigating a more targeted question, such as the extent of positive selection acting on ion channels in this case, or on genes potentially linked to cetaceans’ increased brain sizes (McGowen et al. 2011) or hypoxia tolerance (Tian et al. 2016), can be easier to interpret, as opposed to summarizing broader signals. However, these smaller-scale studies can also experience a high multiple testing burden, especially as similar tests are conducted across numerous studies, which often is not accounted for (Ioannidis 2005). In addition, integrating signals across the entire genome will ultimately be needed given that many genetic changes undoubtedly underlie cetaceans’ phenotypic diversification. As highlighted by the fact that past genome-wide analyses have produced some differing biological interpretations (McGowen et al. 2012; Nery et al. 2013; Sun et al. 2013), this is not a trivial undertaking. Nonetheless, the work performed in this preprint, and in related research, is valuable for (at least) three reasons. First, although it is a challenging task, a better understanding of the genetic basis of cetacean phenotypes could have benefits for many aspects of cetacean biology, including conservation efforts. In addition, the remarkable phenotypic shifts in cetaceans make the question of what genetic mechanisms underlie these changes intrinsically interesting to a wide audience. Last, since the cetacean fossil record is especially well-documented (Thewissen et al. 2009), cetaceans represent an appealing system to validate and further develop statistical methods for inferring adaptation from genetic data. Uribe and colleagues’ (2024) analyses provide useful insights relevant to each of these points, and have generated intriguing hypotheses for further investigation.
Das, K., Sköld, H., Lorenz, A., Parmentier, E. 2023. Who are the marine mammals? In: “Marine Mammals: A Deep Dive into the World of Science”. Brennecke, D., Knickmeier, K., Pawliczka, I., Siebert, U., Wahlberg, M (editors). Springer, Cham. p. 1–14. https://doi.org/10.1007/978-3-031-06836-2_1 Huelsmann, M., Hecker, N., Springer, M., S., Gatesy, J., Sharma, V., Hiller, M. 2019. Genes lost during the transition from land to water in cetaceans highlight genomic changes associated with aquatic adaptations. Science Advances. 5(9):eaaw6671. https://doi.org/10.1126/sciadv.aaw6671 Ioannidis, J., P., A. 2005. Why most published research findings are false. PLOS Medicine. 2(8):e124. https://doi.org/10.1371/journal.pmed.0020124 McGowen MR, Montgomery SH, Clark C, Gatesy J. 2011. Phylogeny and adaptive evolution of the brain-development gene microcephalin (MCPH1) in cetaceans. BMC Evolutionary Biology. 11(1):98. https://doi.org/10.1186/1471-2148-11-98 McGowen MR, Grossman LI, Wildman DE. 2012. Dolphin genome provides evidence for adaptive evolution of nervous system genes and a molecular rate slowdown. Proceedings of the Royal Society B: Biological Sciences. 279(1743):3643–3651. https://doi.org/10.1098/rspb.2012.0869 Nery, M., F., González, D., J., Opazo, J., C. 2013. How to make a dolphin: molecular signature of positive selection in cetacean genome. PLOS ONE. 8(6):e65491. https://doi.org/10.1371/journal.pone.0065491 Sun, Y.-B., Zhou, W.-P., Liu, H.-Q., Irwin, D., M., Shen, Y.-Y., Zhang, Y.-P. 2013. Genome-wide scans for candidate genes involved in the aquatic adaptation of dolphins. Genome Biology and Evolution. 5(1):130–139. https://doi.org/10.1093/gbe/evs123 Tian, R., Wang, Z., Niu, X., Zhou, K., Xu, S., Yang, G. 2016. Evolutionary genetics of hypoxia tolerance in cetaceans during diving. Genome Biology and Evolution. 8(3):827–839. https://doi.org/10.1093/gbe/evw037 Thewissen, J., G., M., Cooper, L., N., George, J., C., Bajpai, S. 2009. From land to water: the origin of whales, dolphins, and porpoises. Evolution: Education and Outreach. 2(2):272–288. https://doi.org/10.1007/s12052-009-0135-2 Uribe, C., Nery, M., Zavala, K., Mardones, G., Riadi, G., Opazo, J. 2024. Evolution of ion channels in cetaceans: A natural experiment in the tree of life. bioRxiv, ver. 8 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.15.545160 Yim, H.-S., Cho, Y., S., Guang, X., Kang, S., G., Jeong, J.-Y., Cha, S.-S., Oh, H.-M., Lee, J.-H., Yang, E., C., Kwon, K., K., et al. 2014. Minke whale genome and aquatic adaptation in cetaceans. Nature Genetics. 46(1):88–92. https://doi.org/10.1038/ng.2835
| Evolution of ion channels in cetaceans: A natural experiment in the tree of life | Cristóbal Uribe, Mariana F. Nery, Kattina Zavala, Gonzalo A. Mardones, Gonzalo Riadi & Juan C. Opazo | <p>Cetaceans could be seen as a natural experiment within the tree of life in which a mammalian lineage changed from terrestrial to aquatic habitats. This shift involved extensive phenotypic modifications, which represent an opportunity to explore... | | Evolutionary genomics | Gavin Douglas | 2023-07-04 20:53:46 |





