
Latest recommendations

| Id | Title | Authors | Abstract | Picture | Thematic fields | Recommender▼ | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
18 Feb 2021
Traces of transposable element in genome dark matter co-opted by flowering gene regulation networksUsing small fragments to discover old TE remnants: the Duster approach empowers the TE detectionRecommended by Francois Sabot based on reviews by Josep Casacuberta and 1 anonymous reviewer based on reviews by Josep Casacuberta and 1 anonymous reviewer
Transposable elements are the raw material of the dark matter of the genome, the foundation of the next generation of genes and regulation networks". This sentence could be the essence of the paper of Baud et al. (2021). Transposable elements (TEs) are endogenous mobile genetic elements found in almost all genomes, which were discovered in 1948 by Barbara McClintock (awarded in 1983 the only unshared Medicine Nobel Prize so far). TEs are present everywhere, from a single isolated copy for some elements to more than millions for others, such as Alu. They are founders of major gene lineages (HET-A, TART and telomerases, RAG1/RAG2 proteins from mammals immune system; Diwash et al, 2017), and even of retroviruses (Xiong & Eickbush, 1988). However, most TEs appear as selfish elements that replicate, land in a new genomic region, then start to decay and finally disappear in the midst of the genome, turning into genomic ‘dark matter’ (Vitte et al, 2007). The mutations (single point, deletion, recombination, and so on) that occur during this slow death erase some of their most notable features and signature sequences, rendering them completely unrecognizable after a few million years. Numerous TE detection tools have tried to optimize their detection (Goerner-Potvin & Bourque, 2018), but further improvement is definitely challenging. This is what Baud et al. (2021) accomplished in their paper. They used a simple, elegant and efficient k-mer based approach to find small signatures that, when accumulated, allow identifying very old TEs. Using this method, called Duster, they improved the amount of annotated TEs in the model plant Arabidopsis thaliana by 20%, pushing the part of this genome occupied by TEs up from 40 to almost 50%. They further observed that these very old Duster-specific TEs (i.e., TEs that are only detected by Duster) are, among other properties, close to genes (much more than recent TEs), not targeted by small RNA pathways, and highly associated with conserved regions across the rosid family. In addition, they are highly associated with flowering or stress response genes, and may be involved through exaptation in the evolution of responses to environmental changes. TEs are not just selfish elements: more and more studies have shown their key role in the evolution of their hosts, and tools such as Duster will help us better understand their impact. References Baud, A., Wan, M., Nouaud, D., Francillonne, N., Anxolabéhère, D. and Quesneville, H. (2021). Traces of transposable elements in genome dark matter co-opted by flowering gene regulation networks. bioRxiv, 547877, ver. 5 peer-reviewed and recommended by PCI Genomics.doi: https://doi.org/10.1101/547877 | Traces of transposable element in genome dark matter co-opted by flowering gene regulation networks | Agnes Baud, Mariene Wan, Danielle Nouaud, Nicolas Francillonne, Dominique Anxolabehere, Hadi Quesneville | <p>Transposable elements (TEs) are mobile, repetitive DNA sequences that make the largest contribution to genome bulk. They thus contribute to the so-called 'dark matter of the genome', the part of the genome in which nothing is immediately recogn... | | Bioinformatics, Evolutionary genomics, Functional genomics, Plants, Structural genomics, Viruses and transposable elements | Francois Sabot | Anonymous, Josep Casacuberta | 2020-04-07 17:12:12 | |
06 May 2022

A deep dive into genome assemblies of non-vertebrate animalsDiving, and even digging, into the wild jungle of annotation pathways for non-vertebrate animalsRecommended by Francois Sabot based on reviews by Yann Bourgeois, Cécile Monat, Valentina Peona and Benjamin Istace
In their paper, Guiglielmoni et al. propose we pick up our snorkels and palms and take "A deep dive into genome assemblies of non-vertebrate animals" (1). Indeed, while numerous assembly-related tools were developed and tested for human genomes (or at least vertebrates such as mice), very few were tested on non-vertebrate animals so far. Moreover, most of the benchmarks are aimed at raw assembly tools, and very few offer a guide from raw reads to an almost finished assembly, including quality control and phasing. This huge and exhaustive review starts with an overview of the current sequencing technologies, followed by the theory of the different approaches for assembly and their implementation. For each approach, the authors present some of the most representative tools, as well as the limits of the approach. The authors additionally present all the steps required to obtain an almost complete assembly at a chromosome-scale, with all the different technologies currently available for scaffolding, QC, and phasing, and the way these tools can be applied to non-vertebrates animals. Finally, they propose some useful advice on the choice of the different approaches (but not always tools, see below), and advocate for a robust genome database with all information on the way the assembly was obtained. This review is a very complete one for now and is a very good starting point for any student or scientist interested to start working on genome assembly, from either model or non-model organisms. However, the authors do not provide a list of tools or a benchmark of them as a recommendation. Why? Because such a proposal may be obsolete in less than a year.... Indeed, with the explosion of the 3rd generation of sequencing technology, assembly tools (from different steps) are constantly evolving, and their relative performance increases on a monthly basis. In addition, some tools are really efficient at the time of a review or of an article, but are not further developed later on, and thus will not evolve with the technology. We have all seen it with wonderful tools such as Chiron (2) or TopHat (3), which were very promising ones, but cannot be developed further due to the stop of the project, the end of the contract of the post-doc in charge of the development, or the decision of the developer to switch to another paradigm. Such advice would, therefore, need to be constantly updated. Thus, the manuscript from Guiglielmoni et al will be an almost intemporal one (up to the next sequencing revolution at last), and as they advocated for a more informed genome database, I think we should consider a rolling benchmarking system (tools, genome and sequence dataset) allowing to keep the performance of the tools up-to-date, and to propose the best set of assembly tools for a given type of genome. References 1. Guiglielmoni N, Rivera-Vicéns R, Koszul R, Flot J-F (2022) A Deep Dive into Genome Assemblies of Non-vertebrate Animals. Preprints, 2021110170, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.20944/preprints202111.0170 2. Teng H, Cao MD, Hall MB, Duarte T, Wang S, Coin LJM (2018) Chiron: translating nanopore raw signal directly into nucleotide sequence using deep learning. GigaScience, 7, giy037. https://doi.org/10.1093/gigascience/giy037 3. Trapnell C, Pachter L, Salzberg SL (2009) TopHat: discovering splice junctions with RNA-Seq. Bioinformatics, 25, 1105–1111. https://doi.org/10.1093/bioinformatics/btp120 | A deep dive into genome assemblies of non-vertebrate animals | Nadège Guiglielmoni, Ramón Rivera-Vicéns, Romain Koszul, Jean-François Flot | <p style="text-align: justify;">Non-vertebrate species represent about ∼95% of known metazoan (animal) diversity. They remain to this day relatively unexplored genetically, but understanding their genome structure and function is pivotal for expan... | | Bioinformatics, Evolutionary genomics | Francois Sabot | Valentina Peona, Benjamin Istace, Cécile Monat, Yann Bourgeois | 2021-11-10 17:47:31 | |
14 Sep 2023
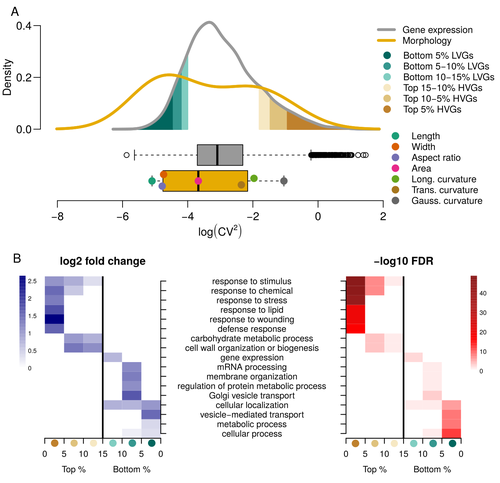
Expression of cell-wall related genes is highly variable and correlates with sepal morphologyThe same but different: How small scale hidden variations can have large effectsRecommended by Francois Sabot based on reviews by Sandra Corjito and 1 anonymous reviewer
For ages, we considered only single genes, or just a few, in order to understand the relationship between phenotype and genotype in response to environmental challenges. Recently, the use of meaningful groups of genes, e.g. gene regulatory networks, or modules of co-expression, allowed scientists to have a larger view of gene regulation. However, all these findings were based on contrasted genotypes, e.g. between wild-types and mutants, as the implicit assumption often made is that there is little transcriptomic variability within the same genotype context. Hartasànchez and collaborators (2023) decided to challenge both views: they used a single genotype instead of two, the famous A. thaliana Col0, and numerous plants, and considered whole gene networks related to sepal morphology and its variations. They used a clever approach, combining high-level phenotyping and gene expression to better understand phenomena and regulations underlying sepal morphologies. Using multiple controls, they showed that basic variations in the expression of genes related to the cell wall regulation, as well as the ones involved in chloroplast metabolism, influenced the global transcriptomic pattern observed in sepal while being in near-identical genetic background and controlling for all other experimental conditions. The paper of Hartasànchez et al. is thus a tremendous call for humility in biology, as we saw in their work that we just understand the gross machinery. However, the Devil is in the details: understanding those very small variations that may have a large influence on phenotypes, and thus on local adaptation to environmental challenges, is of great importance in these times of climatic changes. References Hartasánchez DA, Kiss A, Battu V, Soraru C, Delgado-Vaquera A, Massinon F, Brasó-Vives M, Mollier C, Martin-Magniette M-L, Boudaoud A, Monéger F. 2023. Expression of cell-wall related genes is highly variable and correlates with sepal morphology. bioRxiv, ver. 4, peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.26.489498 | Expression of cell-wall related genes is highly variable and correlates with sepal morphology | Diego A. Hartasánchez, Annamaria Kiss, Virginie Battu, Charline Soraru, Abigail Delgado-Vaquera, Florian Massinon, Marina Brasó-Vives, Corentin Mollier, Marie-Laure Martin-Magniette, Arezki Boudaoud, Françoise Monéger | <p style="text-align: justify;">Control of organ morphology is a fundamental feature of living organisms. There is, however, observable variation in organ size and shape within a given genotype. Taking the sepal of Arabidopsis as a model, we inves... | | Bioinformatics, Epigenomics, Plants | Francois Sabot | 2023-03-14 19:10:15 | ||
20 Nov 2023
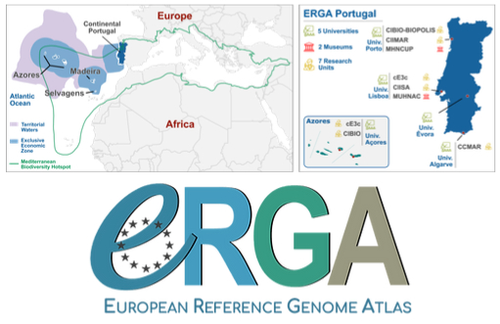
Building a Portuguese Coalition for Biodiversity GenomicsThe Portuguese genomics community teams up with iconic species to understand the destruction of biodiversityRecommended by Fernando Racimo based on reviews by Svein-Ole Mikalsen and 1 anonymous reviewerThis manuscript describes the ongoing work and plans of Biogenome Portugal: a new network of researchers in the Portuguese biodiversity genomics community. The aims of this network are to jointly train scientists in ecology and evolution, generate new knowledge and understanding of Portuguese biodiversity, and better engage with the public and with international researchers, so as to advance conservation efforts in the region. In collaboration across disciplines and institutions, they are also contributing to the European Reference Genome Atlas (ERGA): a massive scientific effort, seeking to eventually produce reference-quality genomes for all species in the European continent (Mc Cartney et al. 2023). The manuscript centers around six iconic and/or severely threatened species, whose range extends across parts of what is today considered Portuguese territory. Via the Portugal chapter of ERGA (ERGA-Portugal), the researchers will generate high-quality genome sequences from these species. The species are the Iberian hare, the Azores laurel, the Black wheatear, the Portuguese crowberry, the Cave ground beetle and the Iberian minnowcarp. In ignorance of human-made political borders, some of these species also occupy large parts of the rest of the Iberian peninsula, highlighting the importance of transnational collaboration in biodiversity efforts. The researchers extracted samples from members of each of these species, and are building reference genome sequences from them. In some cases, these sequences will also be co-analyzed with additional population genomic data from the same species or genetic data from cohabiting species. The researchers aim to answer a variety of ecological and evolutionary questions using this information, including how genetic diversity is being affected by the destruction of their habitat, and how they are being forced to adapt as a consequence of the climate emergency. The authors did a very good job in providing a justification for the choice of pilot species, a thorough methodological overview of current work, and well thought-out plans for future analyses once the genome sequences are available for study. The authors also describe plans for networking and training activities to foster a well-connected Portuguese biodiversity genomics community. Applying a genomic analysis lens is important for understanding the ever faster process of devastation of our natural world. Governments and corporations around the globe are destroying nature at ever larger scales (Diaz et al. 2019). They are also destabilizing the climatic conditions on which life has existed for thousands of years (Trisos et al. 2020). Thus, genetic diversity is decreasing faster than ever in human history, even when it comes to non-threatened species (Exposito-Alonso et al. 2022), and these decreases are disrupting ecological processes worldwide (Richardson et al. 2023). This, in turn, is threatening the conditions on which the stability of our societies rest (Gardner and Bullock 2021). The efforts of Biogenome Portal and ERGA-Portugal will go a long way in helping us understand in greater detail how this process is unfolding in Portuguese territories.
References Díaz, Sandra, et al. "Pervasive human-driven decline of life on Earth points to the need for transformative change." Science 366.6471 (2019): eaax3100. https://doi.org/10.1126/science.aax3100 Exposito-Alonso, Moises, et al. "Genetic diversity loss in the Anthropocene." Science 377.6613 (2022): 1431-1435. https://doi.org/10.1126/science.abn5642 Gardner, Charlie J., and James M. Bullock. "In the climate emergency, conservation must become survival ecology." Frontiers in Conservation Science 2 (2021): 659912. https://doi.org/10.3389/fcosc.2021.659912 Mc Cartney, Ann M., et al. "The European Reference Genome Atlas: piloting a decentralised approach to equitable biodiversity genomics." bioRxiv (2023): 2023-09, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.32942/X20W3Q Richardson, Katherine, et al. "Earth beyond six of nine planetary boundaries." Science Advances 9.37 (2023): eadh2458. https://doi.org/10.1126/sciadv.adh2458 Trisos, Christopher H., Cory Merow, and Alex L. Pigot. "The projected timing of abrupt ecological disruption from climate change." Nature 580.7804 (2020): 496-501. https://doi.org/10.1038/s41586-020-2189-9 | Building a Portuguese Coalition for Biodiversity Genomics | João Pedro Marques, Paulo Célio Alves, Isabel R. Amorim, Ricardo J. Lopes, Mónica Moura, Gene Meyers, Manuela Sim-Sim, Carla Sousa-Santos, Maria Judite Alves, Paulo AV Borges, Thomas Brown, Miguel Carneiro, Carlos Carrapato, Luís Ceríaco, Claudio ... | <p style="text-align: justify;">The diverse physiography of the Portuguese land and marine territory, spanning from continental Europe to the Atlantic archipelagos, has made it an important repository of biodiversity throughout the Pleistocene gla... | | ERGA, ERGA Pilot | Fernando Racimo | 2023-07-14 11:24:22 | ||
06 Jul 2021
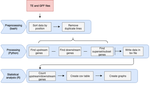
A pipeline to detect the relationship between transposable elements and adjacent genes in host genomesA new tool to cross and analyze TE and gene annotationsRecommended by Emmanuelle Lerat based on reviews by 2 anonymous reviewersTransposable elements (TEs) are important components of genomes. Indeed, they are now recognized as having a major role in gene and genome evolution (Biémont 2010). In particular, several examples have shown that the presence of TEs near genes may influence their functioning, either by recruiting particular epigenetic modifications (Guio et al. 2018) or by directly providing new regulatory sequences allowing new expression patterns (Chung et al. 2007; Sundaram et al. 2014). Therefore, the study of the interaction between TEs and their host genome requires tools to easily cross-annotate both types of entities. In particular, one needs to be able to identify all TEs located in the close vicinity of genes or inside them. Such task may not always be obvious for many biologists, as it requires informatics knowledge to develop their own script codes. In their work, Meguerdichian et al. (2021) propose a command-line pipeline that takes as input the annotations of both genes and TEs for a given genome, then detects and reports the positional relationships between each TE insertion and their closest genes. The results are processed into an R script to provide tables displaying some statistics and graphs to visualize these relationships. This tool has the potential to be very useful for performing preliminary analyses before studying the impact of TEs on gene functioning, especially for biologists. Indeed, it makes it possible to identify genes close to TE insertions. These identified genes could then be specifically considered in order to study in more detail the link between the presence of TEs and their functioning. For example, the identification of TEs close to genes may allow to determine their potential role on gene expression. References Biémont C (2010). A brief history of the status of transposable elements: from junk DNA to major players in evolution. Genetics, 186, 1085–1093. https://doi.org/10.1534/genetics.110.124180 Chung H, Bogwitz MR, McCart C, Andrianopoulos A, ffrench-Constant RH, Batterham P, Daborn PJ (2007). Cis-regulatory elements in the Accord retrotransposon result in tissue-specific expression of the Drosophila melanogaster insecticide resistance gene Cyp6g1. Genetics, 175, 1071–1077. https://doi.org/10.1534/genetics.106.066597 Guio L, Vieira C, González J (2018). Stress affects the epigenetic marks added by natural transposable element insertions in Drosophila melanogaster. Scientific Reports, 8, 12197. https://doi.org/10.1038/s41598-018-30491-w Meguerditchian C, Ergun A, Decroocq V, Lefebvre M, Bui Q-T (2021). A pipeline to detect the relationship between transposable elements and adjacent genes in host genomes. bioRxiv, 2021.02.25.432867, ver. 4 peer-reviewed and recommended by Peer Community In Genomics. https://doi.org/10.1101/2021.02.25.432867 Sundaram V, Cheng Y, Ma Z, Li D, Xing X, Edge P, Snyder MP, Wang T (2014). Widespread contribution of transposable elements to the innovation of gene regulatory networks. Genome Research, 24, 1963–1976. https://doi.org/10.1101/gr.168872.113 | A pipeline to detect the relationship between transposable elements and adjacent genes in host genomes | Caroline Meguerditchian, Ayse Ergun, Veronique Decroocq, Marie Lefebvre, Quynh-Trang Bui | <p>Understanding the relationship between transposable elements (TEs) and their closest positional genes in the host genome is a key point to explore their potential role in genome evolution. Transposable elements can regulate and affect gene expr... | | Bioinformatics, Viruses and transposable elements | Emmanuelle Lerat | 2021-03-03 15:08:34 | ||
11 Sep 2023
COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequencesA pipeline to select SARS-CoV-2 sequences for reliable phylodynamic analysesRecommended by Emmanuelle Lerat based on reviews by Gabriel Wallau and Bastien BoussauPhylodynamic approaches enable viral genetic variation to be tracked over time, providing insight into pathogen phylogenetic relationships and epidemiological dynamics. These are important methods for monitoring viral spread, and identifying important parameters such as transmission rate, geographic origin and duration of infection [1]. This knowledge makes it possible to adjust public health measures in real-time and was important in the case of the COVID-19 pandemic [2]. However, these approaches can be complicated to use when combining a very large number of sequences. This was particularly true during the COVID-19 pandemic, when sequencing data representing millions of entire viral genomes was generated, with associated metadata enabling their precise identification. Danesh et al. [3] present a bioinformatics pipeline, CovFlow, for selecting relevant sequences according to user-defined criteria to produce files that can be used directly for phylodynamic analyses. The selection of sequences first involves a quality filter on the size of the sequences and the absence of unresolved bases before being able to make choices based on the associated metadata. Once the sequences are selected, they are aligned and a time-scaled phylogenetic tree is inferred. An output file in a format directly usable by BEAST 2 [4] is finally generated. To illustrate the use of the pipeline, Danesh et al. [3] present an analysis of the Delta variant in two regions of France. They observed a delay in the start of the epidemic depending on the region. In addition, they identified genetic variation linked to the start of the school year and the extension of vaccination, as well as the arrival of a new variant. This tool will be of major interest to researchers analysing SARS-CoV-2 sequencing data, and a number of future developments are planned by the authors. References [1] Baele G, Dellicour S, Suchard MA, Lemey P, Vrancken B. 2018. Recent advances in computational phylodynamics. Curr Opin Virol. 31:24-32. https://doi.org/10.1016/j.coviro.2018.08.009 [2] Attwood SW, Hill SC, Aanensen DM, Connor TR, Pybus OG. 2022. Phylogenetic and phylodynamic approaches to understanding and combating the early SARS-CoV-2 pandemic. Nat Rev Genet. 23:547-562. https://doi.org/10.1038/s41576-022-00483-8 [3] Danesh G, Boennec C, Verdurme L, Roussel M, Trombert-Paolantoni S, Visseaux B, Haim-Boukobza S, Alizon S. 2023. COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences. bioRxiv, ver. 7 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.06.17.496544 [4] Bouckaert R, Heled J, Kühnert D, Vaughan T, Wu C-H et al. 2014. BEAST 2: a software platform for Bayesian evolutionary analysis. PLoS Comput Biol 10: e1003537. https://doi.org/10.1371/journal.pcbi.1003537 | COVFlow: phylodynamics analyses of viruses from selected SARS-CoV-2 genome sequences | Gonché Danesh, Corentin Boennec, Laura Verdurme, Mathilde Roussel, Sabine Trombert-Paolantoni, Benoit Visseaux, Stephanie Haim-Boukobza, Samuel Alizon | <p style="text-align: justify;">Phylodynamic analyses generate important and timely data to optimise public health response to SARS-CoV-2 outbreaks and epidemics. However, their implementation is hampered by the massive amount of sequence data and... | | Bioinformatics, Evolutionary genomics | Emmanuelle Lerat | 2022-12-12 09:04:01 | ||
24 Jan 2024

High quality genome assembly of the brown hare (Lepus europaeus) with chromosome-level scaffoldingA high quality reference genome of the brown hareRecommended by Ed Hollox based on reviews by Merce Montoliu-Nerin and 1 anonymous reviewer
The brown hare, or European hare, Lupus europaeus, is a widespread mammal whose natural range spans western Eurasia. At the northern limit of its range, it hybridises with the mountain hare (L. timidis), and humans have introduced it into other continents. It represents a particularly interesting mammal to study for its population genetics, extensive hybridisation zones, and as an invasive species. This study (Michell et al. 2024) has generated a high-quality assembly of a genome from a brown hare from Finland using long PacBio HiFi sequencing reads and Hi-C scaffolding. The contig N50 of this new genome is 43 Mb, and completeness, assessed using BUSCO, is 96.1%. The assembly comprises 23 autosomes, and an X chromosome and Y chromosome, with many chromosomes including telomeric repeats, indicating the high level of completeness of this assembly. While the genome of the mountain hare has previously been assembled, its assembly was based on a short-read shotgun assembly, with the rabbit as a reference genome. The new high-quality brown hare genome assembly allows a direct comparison with the rabbit genome assembly. For example, the assembly addresses the karyotype difference between the hare (n=24) and the rabbit (n=22). Chromosomes 12 and 17 of the hare are equivalent to chromosome 1 of the rabbit, and chromosomes 13 and 16 of the hare are equivalent to chromosome 2 of the rabbit. The new assembly also provides a hare Y-chromosome, as the previous mountain hare genome was from a female. This new genome assembly provides an important foundation for population genetics and evolutionary studies of lagomorphs. References Michell, C., Collins, J., Laine, P. K., Fekete, Z., Tapanainen, R., Wood, J. M. D., Goffart, S., Pohjoismäki, J. L. O. (2024). High quality genome assembly of the brown hare (Lepus europaeus) with chromosome-level scaffolding. bioRxiv, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.08.29.555262 | High quality genome assembly of the brown hare (*Lepus europaeus*) with chromosome-level scaffolding | Craig Michell, Joanna Collins, Pia K. Laine, Zsofia Fekete, Riikka Tapanainen, Jonathan M. D. Wood, Steffi Goffart, Jaakko L. O. Pohjoismaki | <p style="text-align: justify;">We present here a high-quality genome assembly of the brown hare (Lepus europaeus Pallas), based on a fibroblast cell line of a male specimen from Liperi, Eastern Finland. This brown hare genome represents the first... | | ERGA Pilot, Vertebrates | Ed Hollox | 2023-10-16 20:46:39 | ||
07 Aug 2023
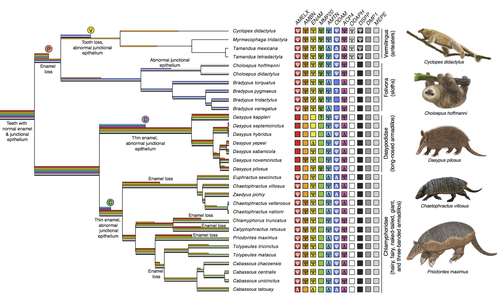
Genomic data suggest parallel dental vestigialization within the xenarthran radiationWhat does dental gene decay tell us about the regressive evolution of teeth in South American mammals?Recommended by Didier Casane based on reviews by Juan C. Opazo, Régis Debruyne and Nicolas PolletA group of mammals, Xenathra, evolved and diversified in South America during its long period of isolation in the early to mid Cenozoic era. More recently, as a result of the Great Faunal Interchange between South America and North America, many xenarthran species went extinct. The thirty-one extant species belong to three groups: armadillos, sloths and anteaters. They share dental degeneration. However, the level of degeneration is variable. Anteaters entirely lack teeth, sloths have intermediately regressed teeth and most armadillos have a toothless premaxilla, as well as peg-like, single-rooted teeth that lack enamel in adult animals (Vizcaíno 2009). This diversity raises a number of questions about the evolution of dentition in these mammals. Unfortunately, the fossil record is too poor to provide refined information on the different stages of regressive evolution in these clades. In such cases, the identification of loss-of-function mutations and/or relaxed selection in genes related to a character regression can be very informative (Emerling and Springer 2014; Meredith et al. 2014; Policarpo et al. 2021). Indeed, shared and unique pseudogenes/relaxed selection can tell us to what extent regression has occurred in common ancestors and whether some changes are lineage-specific. In addition, the distribution of pseudogenes/relaxed selection on the branches of a phylogenetic tree is related to the evolutionary processes involved. A much higher density of pseudogenes in the most internal branches indicates that degeneration took place early and over a short period of time, consistent with selection against the presence of the morphological character with which they are associated, while pseudogenes distributed evenly in many internal and external branches suggest a more gradual process over many millions of years, in line with relaxed selection and fixation of loss-of-function mutations by genetic drift. In this paper (Emerling et al. 2023), the authors examined the dynamics of decay of 11 dental genes that may parallel teeth regression. The analyses of the data reported in this paper clearly point to xenarthran teeth having repeatedly regressed in parallel in the three clades. In fact, no loss-of-function mutation is shared by all species examined. However, more genes should be studied to confirm the hypothesis that the common ancestor of extant xenarthrans had normal dentition. There are distinct patterns of gene loss in different lineages that are associated with the variation in dentition observed across the clades. These patterns of gene loss suggest that regressive evolution took place both gradually and in relatively rapid, discrete phases during the diversification of xenarthrans. This study underscores the utility of using pseudogenes to reconstruct evolutionary history of morphological characters when fossils are sparse. References Emerling CA, Gibb GC, Tilak M-K, Hughes JJ, Kuch M, Duggan AT, Poinar HN, Nachman MW, Delsuc F. 2023. Genomic data suggest parallel dental vestigialization within the xenarthran radiation. bioRxiv, 2022.12.09.519446, ver 2, peer-reviewed and recommended by PCI Genomics. https://doi.org/10.1101/2022.12.09.519446 Emerling CA, Springer MS. 2014. Eyes underground: Regression of visual protein networks in subterranean mammals. Molecular Phylogenetics and Evolution 78: 260-270. https://doi.org/10.1016/j.ympev.2014.05.016 Meredith RW, Zhang G, Gilbert MTP, Jarvis ED, Springer MS. 2014. Evidence for a single loss of mineralized teeth in the common avian ancestor. Science 346: 1254390. https://doi.org/10.1126/science.1254390 Policarpo M, Fumey J, Lafargeas P, Naquin D, Thermes C, Naville M, Dechaud C, Volff J-N, Cabau C, Klopp C, et al. 2021. Contrasting gene decay in subterranean vertebrates: insights from cavefishes and fossorial mammals. Molecular Biology and Evolution 38: 589-605. https://doi.org/10.1093/molbev/msaa249 Vizcaíno SF. 2009. The teeth of the “toothless”: novelties and key innovations in the evolution of xenarthrans (Mammalia, Xenarthra). Paleobiology 35: 343-366. https://doi.org/10.1666/0094-8373-35.3.343 | Genomic data suggest parallel dental vestigialization within the xenarthran radiation | Christopher A Emerling, Gillian C Gibb, Marie-Ka Tilak, Jonathan J Hughes, Melanie Kuch, Ana T Duggan, Hendrik N Poinar, Michael W Nachman, Frederic Delsuc | <p style="text-align: justify;">The recent influx of genomic data has provided greater insights into the molecular basis for regressive evolution, or vestigialization, through gene loss and pseudogenization. As such, the analysis of gene degradati... | | Evolutionary genomics, Vertebrates | Didier Casane | 2022-12-12 16:01:57 | ||
06 Apr 2021
Evidence for shared ancestry between Actinobacteria and Firmicutes bacteriophagesViruses of bacteria: phages evolution across phylum boundariesRecommended by Denis Tagu based on reviews by 3 anonymous reviewersBacteria and phages have coexisted and coevolved for a long time. Phages are bacteria-infecting viruses, with a symbiotic status sensu lato, meaning they can be pathogenic, commensal or mutualistic. Thus, the association between bacteria phages has probably played a key role in the high adaptability of bacteria to most - if not all – of Earth’s ecosystems, including other living organisms (such as eukaryotes), and also regulate bacterial community size (for instance during bacterial blooms). As genetic entities, phages are submitted to mutations and natural selection, which changes their DNA sequence. Therefore, comparative genomic analyses of contemporary phages can be useful to understand their evolutionary dynamics. International initiatives such as SEA-PHAGES have started to tackle the issue of history of phage-bacteria interactions and to describe the dynamics of the co-evolution between bacterial hosts and their associated viruses. Indeed, the understanding of this cross-talk has many potential implications in terms of health and agriculture, among others. The work of Koert et al. (2021) deals with one of the largest groups of bacteria (Actinobacteria), which are Gram-positive bacteria mainly found in soil and water. Some soil-born Actinobacteria develop filamentous structures reminiscent of the mycelium of eukaryotic fungi. In this study, the authors focused on the Streptomyces clade, a large genus of Actinobacteria colonized by phages known for their high level of genetic diversity. The authors tested the hypothesis that large exchanges of genetic material occurred between Streptomyces and diverse phages associated with bacterial hosts. Using public datasets, their comparative phylogenomic analyses identified a new cluster among Actinobacteria–infecting phages closely related to phages of Firmicutes. Moreover, the GC content and codon-usage biases of this group of phages of Actinobacteria are similar to those of Firmicutes. This work demonstrates for the first time the transfer of a bacteriophage lineage from one bacterial phylum to another one. The results presented here suggest that the age of the described transfer is probably recent since several genomic characteristics of the phage are not fully adapted to their new hosts. However, the frequency of such transfer events remains an open question. If frequent, such exchanges would mean that pools of bacteriophages are regularly fueled by genetic material coming from external sources, which would have important implications for the co-evolutionary dynamics of phages and bacteria. References Koert, M., López-Pérez, J., Courtney Mattson, C., Caruso, S. and Erill, I. (2021) Evidence for shared ancestry between Actinobacteria and Firmicutes bacteriophages. bioRxiv, 842583, version 5 peer-reviewed and recommended by Peer community in Genomics. doi: https://doi.org/10.1101/842583 | Evidence for shared ancestry between Actinobacteria and Firmicutes bacteriophages | Matthew Koert, Júlia López-Pérez, Courtney Mattson, Steven M. Caruso, Ivan Erill | <p>Bacteriophages typically infect a small set of related bacterial strains. The transfer of bacteriophages between more distant clades of bacteria has often been postulated, but remains mostly unaddressed. In this work we leverage the sequencing ... | | Evolutionary genomics | Denis Tagu | 2019-12-10 15:26:31 | ||
05 May 2021
A primer and discussion on DNA-based microbiome data and related bioinformatics analysesA hitchhiker’s guide to DNA-based microbiome analysisRecommended by Danny Ionescu based on reviews by Nicolas Pollet, Rafael Cuadrat and 1 anonymous reviewer
In the last two decades, microbial research in its different fields has been increasingly focusing on microbiome studies. These are defined as studies of complete assemblages of microorganisms in given environments and have been benefiting from increases in sequencing length, quality, and yield, coupled with ever-dropping prices per sequenced nucleotide. Alongside localized microbiome studies, several global collaborative efforts have emerged, including the Human Microbiome Project [1], the Earth Microbiome Project [2], the Extreme Microbiome Project, and MetaSUB [3]. Coupled with the development of sequencing technologies and the ever-increasing amount of data output, multiple standalone or online bioinformatic tools have been designed to analyze these data. Often these tools have been focusing on either of two main tasks: 1) Community analysis, providing information on the organisms present in the microbiome, or 2) Functionality, in the case of shotgun metagenomic data, providing information on the metabolic potential of the microbiome. Bridging between the two types of data, often extracted from the same dataset, is typically a daunting task that has been addressed by a handful of tools only. The extent of tools and approaches to analyze microbiome data is great and may be overwhelming to researchers new to microbiome or bioinformatic studies. In their paper “A primer and discussion on DNA-based microbiome data and related bioinformatics analyses”, Douglas and Langille [4] guide us through the different sequencing approaches useful for microbiome studies. alongside their advantages and caveats and a selection of tools to analyze these data, coupled with examples from their own field of research. Standing out in their primer-style review is the emphasis on the coupling between taxonomic/phylogenetic identification of the organisms and their functionality. This type of analysis, though highly important to understand the role of different microorganisms in an environment as well as to identify potential functional redundancy, is often not conducted. For this, the authors identify two approaches. The first, using shotgun metagenomics, has higher chances of attributing a function to the correct taxon. The second, using amplicon sequencing of marker genes, allows for a deeper coverage of the microbiome at a lower cost, and extrapolates the amplicon data to close relatives with a sequenced genome. As clearly stated, this approach makes the leap between taxonomy and functionality and has been shown to be erroneous in cases where the core genome of the bacterial genus or family does not encompass the functional diversity of the different included species. This practice was already common before the genomic era, but its accuracy is improving thanks to the increasing availability of sequenced reference genomes from cultures, environmentally picked single cells or metagenome-assembled genome. In addition to their description of standalone tools useful for linking taxonomy and functionality, one should mention the existence of online tools that may appeal to researchers who do not have access to adequate bioinformatics infrastructure. Among these are the Integrated Microbial Genomes and Microbiomes (IMG) from the Joint Genome Institute [5], KBase [6] and MG-RAST [7]. A second important point arising from this review is the need for standardization in microbiome data analyses and the complexity of achieving this. As Douglas and Langille [4] state, this has been previously addressed, highlighting the variability in results obtained with different tools. It is often the case that papers describing new bioinformatic tools display their superiority relative to existing alternatives, potentially misleading newcomers to the field that the newest tool is the best and only one to be used. This is often not the case, and while benchmarking against well-defined datasets serves as a powerful testing tool, “real-life” samples are often not comparable. Thus, as done here, future primer-like reviews should highlight possible cross-field caveats, encouraging researchers to employ and test several approaches and validate their results whenever possible. In summary, Douglas and Langille [4] offer both the novice and experienced researcher a detailed guide along the paths of microbiome data analysis, accompanied by informative background information, suggested tools with which analyses can be started, and an insightful view on where the field should be heading. References [1] Turnbaugh PJ, Ley RE, Hamady M, Fraser-Liggett CM, Knight R, Gordon JI (2007) The Human Microbiome Project. Nature, 449, 804–810. https://doi.org/10.1038/nature06244 [2] Gilbert JA, Jansson JK, Knight R (2014) The Earth Microbiome project: successes and aspirations. BMC Biology, 12, 69. https://doi.org/10.1186/s12915-014-0069-1 [3] Mason C, Afshinnekoo E, Ahsannudin S, Ghedin E, Read T, Fraser C, Dudley J, Hernandez M, Bowler C, Stolovitzky G, Chernonetz A, Gray A, Darling A, Burke C, Łabaj PP, Graf A, Noushmehr H, Moraes s., Dias-Neto E, Ugalde J, Guo Y, Zhou Y, Xie Z, Zheng D, Zhou H, Shi L, Zhu S, Tang A, Ivanković T, Siam R, Rascovan N, Richard H, Lafontaine I, Baron C, Nedunuri N, Prithiviraj B, Hyat S, Mehr S, Banihashemi K, Segata N, Suzuki H, Alpuche Aranda CM, Martinez J, Christopher Dada A, Osuolale O, Oguntoyinbo F, Dybwad M, Oliveira M, Fernandes A, Oliveira M, Fernandes A, Chatziefthimiou AD, Chaker S, Alexeev D, Chuvelev D, Kurilshikov A, Schuster S, Siwo GH, Jang S, Seo SC, Hwang SH, Ossowski S, Bezdan D, Udekwu K, Udekwu K, Lungjdahl PO, Nikolayeva O, Sezerman U, Kelly F, Metrustry S, Elhaik E, Gonnet G, Schriml L, Mongodin E, Huttenhower C, Gilbert J, Hernandez M, Vayndorf E, Blaser M, Schadt E, Eisen J, Beitel C, Hirschberg D, Schriml L, Mongodin E, The MetaSUB International Consortium (2016) The Metagenomics and Metadesign of the Subways and Urban Biomes (MetaSUB) International Consortium inaugural meeting report. Microbiome, 4, 24. https://doi.org/10.1186/s40168-016-0168-z [4] Douglas GM, Langille MGI (2021) A primer and discussion on DNA-based microbiome data and related bioinformatics analyses. OSF Preprints, ver. 4 peer-reviewed and recommended by Peer Community In Genomics. https://doi.org/10.31219/osf.io/3dybg [5] Chen I-MA, Markowitz VM, Chu K, Palaniappan K, Szeto E, Pillay M, Ratner A, Huang J, Andersen E, Huntemann M, Varghese N, Hadjithomas M, Tennessen K, Nielsen T, Ivanova NN, Kyrpides NC (2017) IMG/M: integrated genome and metagenome comparative data analysis system. Nucleic Acids Research, 45, D507–D516. https://doi.org/10.1093/nar/gkw929 [6] Arkin AP, Cottingham RW, Henry CS, Harris NL, Stevens RL, Maslov S, Dehal P, Ware D, Perez F, Canon S, Sneddon MW, Henderson ML, Riehl WJ, Murphy-Olson D, Chan SY, Kamimura RT, Kumari S, Drake MM, Brettin TS, Glass EM, Chivian D, Gunter D, Weston DJ, Allen BH, Baumohl J, Best AA, Bowen B, Brenner SE, Bun CC, Chandonia J-M, Chia J-M, Colasanti R, Conrad N, Davis JJ, Davison BH, DeJongh M, Devoid S, Dietrich E, Dubchak I, Edirisinghe JN, Fang G, Faria JP, Frybarger PM, Gerlach W, Gerstein M, Greiner A, Gurtowski J, Haun HL, He F, Jain R, Joachimiak MP, Keegan KP, Kondo S, Kumar V, Land ML, Meyer F, Mills M, Novichkov PS, Oh T, Olsen GJ, Olson R, Parrello B, Pasternak S, Pearson E, Poon SS, Price GA, Ramakrishnan S, Ranjan P, Ronald PC, Schatz MC, Seaver SMD, Shukla M, Sutormin RA, Syed MH, Thomason J, Tintle NL, Wang D, Xia F, Yoo H, Yoo S, Yu D (2018) KBase: The United States Department of Energy Systems Biology Knowledgebase. Nature Biotechnology, 36, 566–569. https://doi.org/10.1038/nbt.4163 [7] Wilke A, Bischof J, Gerlach W, Glass E, Harrison T, Keegan KP, Paczian T, Trimble WL, Bagchi S, Grama A, Chaterji S, Meyer F (2016) The MG-RAST metagenomics database and portal in 2015. Nucleic Acids Research, 44, D590–D594. https://doi.org/10.1093/nar/gkv1322 | A primer and discussion on DNA-based microbiome data and related bioinformatics analyses | Gavin M. Douglas and Morgan G. I. Langille | <p style="text-align: justify;">The past decade has seen an eruption of interest in profiling microbiomes through DNA sequencing. The resulting investigations have revealed myriad insights and attracted an influx of researchers to the research are... | | Bioinformatics, Metagenomics | Danny Ionescu | 2021-02-17 00:26:46 |




