
Latest recommendations

| Id | Title * | Authors * | Abstract * | Picture * | Thematic fields * | Recommender▲ | Reviewers | Submission date | |
|---|---|---|---|---|---|---|---|---|---|
20 Nov 2023
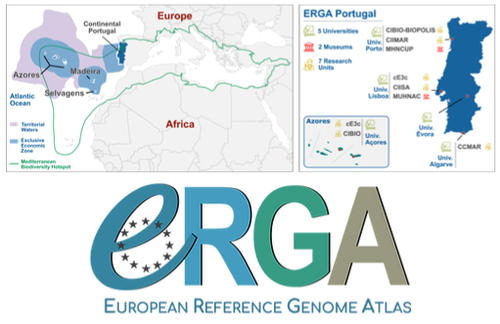
Building a Portuguese Coalition for Biodiversity GenomicsThe Portuguese genomics community teams up with iconic species to understand the destruction of biodiversityRecommended by Fernando Racimo based on reviews by Svein-Ole Mikalsen and 1 anonymous reviewerThis manuscript describes the ongoing work and plans of Biogenome Portugal: a new network of researchers in the Portuguese biodiversity genomics community. The aims of this network are to jointly train scientists in ecology and evolution, generate new knowledge and understanding of Portuguese biodiversity, and better engage with the public and with international researchers, so as to advance conservation efforts in the region. In collaboration across disciplines and institutions, they are also contributing to the European Reference Genome Atlas (ERGA): a massive scientific effort, seeking to eventually produce reference-quality genomes for all species in the European continent (Mc Cartney et al. 2023). The manuscript centers around six iconic and/or severely threatened species, whose range extends across parts of what is today considered Portuguese territory. Via the Portugal chapter of ERGA (ERGA-Portugal), the researchers will generate high-quality genome sequences from these species. The species are the Iberian hare, the Azores laurel, the Black wheatear, the Portuguese crowberry, the Cave ground beetle and the Iberian minnowcarp. In ignorance of human-made political borders, some of these species also occupy large parts of the rest of the Iberian peninsula, highlighting the importance of transnational collaboration in biodiversity efforts. The researchers extracted samples from members of each of these species, and are building reference genome sequences from them. In some cases, these sequences will also be co-analyzed with additional population genomic data from the same species or genetic data from cohabiting species. The researchers aim to answer a variety of ecological and evolutionary questions using this information, including how genetic diversity is being affected by the destruction of their habitat, and how they are being forced to adapt as a consequence of the climate emergency. The authors did a very good job in providing a justification for the choice of pilot species, a thorough methodological overview of current work, and well thought-out plans for future analyses once the genome sequences are available for study. The authors also describe plans for networking and training activities to foster a well-connected Portuguese biodiversity genomics community. Applying a genomic analysis lens is important for understanding the ever faster process of devastation of our natural world. Governments and corporations around the globe are destroying nature at ever larger scales (Diaz et al. 2019). They are also destabilizing the climatic conditions on which life has existed for thousands of years (Trisos et al. 2020). Thus, genetic diversity is decreasing faster than ever in human history, even when it comes to non-threatened species (Exposito-Alonso et al. 2022), and these decreases are disrupting ecological processes worldwide (Richardson et al. 2023). This, in turn, is threatening the conditions on which the stability of our societies rest (Gardner and Bullock 2021). The efforts of Biogenome Portal and ERGA-Portugal will go a long way in helping us understand in greater detail how this process is unfolding in Portuguese territories.
References Díaz, Sandra, et al. "Pervasive human-driven decline of life on Earth points to the need for transformative change." Science 366.6471 (2019): eaax3100. https://doi.org/10.1126/science.aax3100 Exposito-Alonso, Moises, et al. "Genetic diversity loss in the Anthropocene." Science 377.6613 (2022): 1431-1435. https://doi.org/10.1126/science.abn5642 Gardner, Charlie J., and James M. Bullock. "In the climate emergency, conservation must become survival ecology." Frontiers in Conservation Science 2 (2021): 659912. https://doi.org/10.3389/fcosc.2021.659912 Mc Cartney, Ann M., et al. "The European Reference Genome Atlas: piloting a decentralised approach to equitable biodiversity genomics." bioRxiv (2023): 2023-09, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.32942/X20W3Q Richardson, Katherine, et al. "Earth beyond six of nine planetary boundaries." Science Advances 9.37 (2023): eadh2458. https://doi.org/10.1126/sciadv.adh2458 Trisos, Christopher H., Cory Merow, and Alex L. Pigot. "The projected timing of abrupt ecological disruption from climate change." Nature 580.7804 (2020): 496-501. https://doi.org/10.1038/s41586-020-2189-9 | Building a Portuguese Coalition for Biodiversity Genomics | João Pedro Marques, Paulo Célio Alves, Isabel R. Amorim, Ricardo J. Lopes, Mónica Moura, Gene Meyers, Manuela Sim-Sim, Carla Sousa-Santos, Maria Judite Alves, Paulo AV Borges, Thomas Brown, Miguel Carneiro, Carlos Carrapato, Luís Ceríaco, Claudio ... | <p style="text-align: justify;">The diverse physiography of the Portuguese land and marine territory, spanning from continental Europe to the Atlantic archipelagos, has made it an important repository of biodiversity throughout the Pleistocene gla... | | ERGA, ERGA Pilot | Fernando Racimo | 2023-07-14 11:24:22 | ||
18 Feb 2021
Traces of transposable element in genome dark matter co-opted by flowering gene regulation networksUsing small fragments to discover old TE remnants: the Duster approach empowers the TE detectionRecommended by Francois Sabot based on reviews by Josep Casacuberta and 1 anonymous reviewer based on reviews by Josep Casacuberta and 1 anonymous reviewer
Transposable elements are the raw material of the dark matter of the genome, the foundation of the next generation of genes and regulation networks". This sentence could be the essence of the paper of Baud et al. (2021). Transposable elements (TEs) are endogenous mobile genetic elements found in almost all genomes, which were discovered in 1948 by Barbara McClintock (awarded in 1983 the only unshared Medicine Nobel Prize so far). TEs are present everywhere, from a single isolated copy for some elements to more than millions for others, such as Alu. They are founders of major gene lineages (HET-A, TART and telomerases, RAG1/RAG2 proteins from mammals immune system; Diwash et al, 2017), and even of retroviruses (Xiong & Eickbush, 1988). However, most TEs appear as selfish elements that replicate, land in a new genomic region, then start to decay and finally disappear in the midst of the genome, turning into genomic ‘dark matter’ (Vitte et al, 2007). The mutations (single point, deletion, recombination, and so on) that occur during this slow death erase some of their most notable features and signature sequences, rendering them completely unrecognizable after a few million years. Numerous TE detection tools have tried to optimize their detection (Goerner-Potvin & Bourque, 2018), but further improvement is definitely challenging. This is what Baud et al. (2021) accomplished in their paper. They used a simple, elegant and efficient k-mer based approach to find small signatures that, when accumulated, allow identifying very old TEs. Using this method, called Duster, they improved the amount of annotated TEs in the model plant Arabidopsis thaliana by 20%, pushing the part of this genome occupied by TEs up from 40 to almost 50%. They further observed that these very old Duster-specific TEs (i.e., TEs that are only detected by Duster) are, among other properties, close to genes (much more than recent TEs), not targeted by small RNA pathways, and highly associated with conserved regions across the rosid family. In addition, they are highly associated with flowering or stress response genes, and may be involved through exaptation in the evolution of responses to environmental changes. TEs are not just selfish elements: more and more studies have shown their key role in the evolution of their hosts, and tools such as Duster will help us better understand their impact. References Baud, A., Wan, M., Nouaud, D., Francillonne, N., Anxolabéhère, D. and Quesneville, H. (2021). Traces of transposable elements in genome dark matter co-opted by flowering gene regulation networks. bioRxiv, 547877, ver. 5 peer-reviewed and recommended by PCI Genomics.doi: https://doi.org/10.1101/547877 | Traces of transposable element in genome dark matter co-opted by flowering gene regulation networks | Agnes Baud, Mariene Wan, Danielle Nouaud, Nicolas Francillonne, Dominique Anxolabehere, Hadi Quesneville | <p>Transposable elements (TEs) are mobile, repetitive DNA sequences that make the largest contribution to genome bulk. They thus contribute to the so-called 'dark matter of the genome', the part of the genome in which nothing is immediately recogn... | | Bioinformatics, Evolutionary genomics, Functional genomics, Plants, Structural genomics, Viruses and transposable elements | Francois Sabot | Anonymous, Josep Casacuberta | 2020-04-07 17:12:12 | |
06 May 2022

A deep dive into genome assemblies of non-vertebrate animalsDiving, and even digging, into the wild jungle of annotation pathways for non-vertebrate animalsRecommended by Francois Sabot based on reviews by Yann Bourgeois, Cécile Monat, Valentina Peona and Benjamin Istace
In their paper, Guiglielmoni et al. propose we pick up our snorkels and palms and take "A deep dive into genome assemblies of non-vertebrate animals" (1). Indeed, while numerous assembly-related tools were developed and tested for human genomes (or at least vertebrates such as mice), very few were tested on non-vertebrate animals so far. Moreover, most of the benchmarks are aimed at raw assembly tools, and very few offer a guide from raw reads to an almost finished assembly, including quality control and phasing. This huge and exhaustive review starts with an overview of the current sequencing technologies, followed by the theory of the different approaches for assembly and their implementation. For each approach, the authors present some of the most representative tools, as well as the limits of the approach. The authors additionally present all the steps required to obtain an almost complete assembly at a chromosome-scale, with all the different technologies currently available for scaffolding, QC, and phasing, and the way these tools can be applied to non-vertebrates animals. Finally, they propose some useful advice on the choice of the different approaches (but not always tools, see below), and advocate for a robust genome database with all information on the way the assembly was obtained. This review is a very complete one for now and is a very good starting point for any student or scientist interested to start working on genome assembly, from either model or non-model organisms. However, the authors do not provide a list of tools or a benchmark of them as a recommendation. Why? Because such a proposal may be obsolete in less than a year.... Indeed, with the explosion of the 3rd generation of sequencing technology, assembly tools (from different steps) are constantly evolving, and their relative performance increases on a monthly basis. In addition, some tools are really efficient at the time of a review or of an article, but are not further developed later on, and thus will not evolve with the technology. We have all seen it with wonderful tools such as Chiron (2) or TopHat (3), which were very promising ones, but cannot be developed further due to the stop of the project, the end of the contract of the post-doc in charge of the development, or the decision of the developer to switch to another paradigm. Such advice would, therefore, need to be constantly updated. Thus, the manuscript from Guiglielmoni et al will be an almost intemporal one (up to the next sequencing revolution at last), and as they advocated for a more informed genome database, I think we should consider a rolling benchmarking system (tools, genome and sequence dataset) allowing to keep the performance of the tools up-to-date, and to propose the best set of assembly tools for a given type of genome. References 1. Guiglielmoni N, Rivera-Vicéns R, Koszul R, Flot J-F (2022) A Deep Dive into Genome Assemblies of Non-vertebrate Animals. Preprints, 2021110170, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.20944/preprints202111.0170 2. Teng H, Cao MD, Hall MB, Duarte T, Wang S, Coin LJM (2018) Chiron: translating nanopore raw signal directly into nucleotide sequence using deep learning. GigaScience, 7, giy037. https://doi.org/10.1093/gigascience/giy037 3. Trapnell C, Pachter L, Salzberg SL (2009) TopHat: discovering splice junctions with RNA-Seq. Bioinformatics, 25, 1105–1111. https://doi.org/10.1093/bioinformatics/btp120 | A deep dive into genome assemblies of non-vertebrate animals | Nadège Guiglielmoni, Ramón Rivera-Vicéns, Romain Koszul, Jean-François Flot | <p style="text-align: justify;">Non-vertebrate species represent about ∼95% of known metazoan (animal) diversity. They remain to this day relatively unexplored genetically, but understanding their genome structure and function is pivotal for expan... | | Bioinformatics, Evolutionary genomics | Francois Sabot | Valentina Peona, Benjamin Istace, Cécile Monat, Yann Bourgeois | 2021-11-10 17:47:31 | |
14 Sep 2023
Expression of cell-wall related genes is highly variable and correlates with sepal morphologyThe same but different: How small scale hidden variations can have large effectsRecommended by Francois Sabot based on reviews by Sandra Corjito and 1 anonymous reviewer
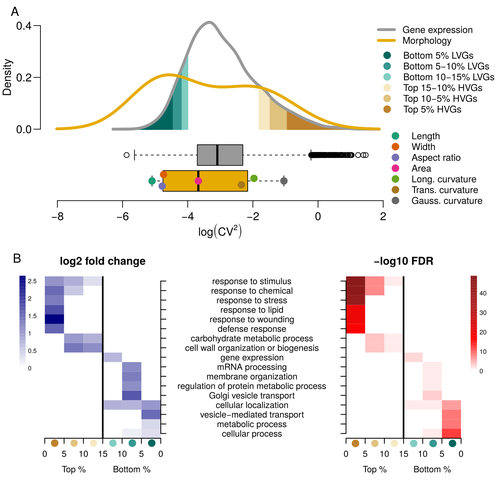
For ages, we considered only single genes, or just a few, in order to understand the relationship between phenotype and genotype in response to environmental challenges. Recently, the use of meaningful groups of genes, e.g. gene regulatory networks, or modules of co-expression, allowed scientists to have a larger view of gene regulation. However, all these findings were based on contrasted genotypes, e.g. between wild-types and mutants, as the implicit assumption often made is that there is little transcriptomic variability within the same genotype context. Hartasànchez and collaborators (2023) decided to challenge both views: they used a single genotype instead of two, the famous A. thaliana Col0, and numerous plants, and considered whole gene networks related to sepal morphology and its variations. They used a clever approach, combining high-level phenotyping and gene expression to better understand phenomena and regulations underlying sepal morphologies. Using multiple controls, they showed that basic variations in the expression of genes related to the cell wall regulation, as well as the ones involved in chloroplast metabolism, influenced the global transcriptomic pattern observed in sepal while being in near-identical genetic background and controlling for all other experimental conditions. The paper of Hartasànchez et al. is thus a tremendous call for humility in biology, as we saw in their work that we just understand the gross machinery. However, the Devil is in the details: understanding those very small variations that may have a large influence on phenotypes, and thus on local adaptation to environmental challenges, is of great importance in these times of climatic changes. References Hartasánchez DA, Kiss A, Battu V, Soraru C, Delgado-Vaquera A, Massinon F, Brasó-Vives M, Mollier C, Martin-Magniette M-L, Boudaoud A, Monéger F. 2023. Expression of cell-wall related genes is highly variable and correlates with sepal morphology. bioRxiv, ver. 4, peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.04.26.489498 | Expression of cell-wall related genes is highly variable and correlates with sepal morphology | Diego A. Hartasánchez, Annamaria Kiss, Virginie Battu, Charline Soraru, Abigail Delgado-Vaquera, Florian Massinon, Marina Brasó-Vives, Corentin Mollier, Marie-Laure Martin-Magniette, Arezki Boudaoud, Françoise Monéger | <p style="text-align: justify;">Control of organ morphology is a fundamental feature of living organisms. There is, however, observable variation in organ size and shape within a given genotype. Taking the sepal of Arabidopsis as a model, we inves... | | Bioinformatics, Epigenomics, Plants | Francois Sabot | 2023-03-14 19:10:15 | ||
01 Jul 2024
Contextualising samples: Supporting reference genomes of European biodiversity through sample and associated metadata collectionTo avoid biases and to be FAIR, we need to CARE and share biodiversity metadataRecommended by Francois Sabot based on reviews by Julian Osuji and 1 anonymous reviewer
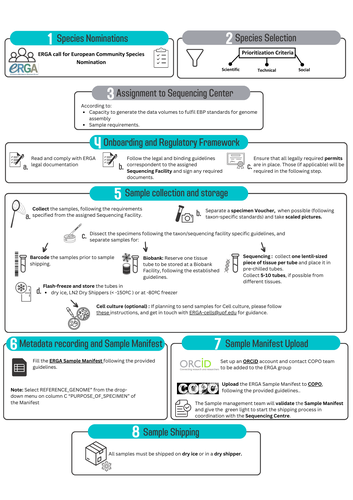
Böhne et al. (2024) do not present a classical scientific paper per se but a report on how the European Reference Genome Atlas (ERGA) aims to deal with sampling and sample information, i.e. metadata. As the goal of ERGA is to provide an almost fully representative set of reference genomes representative of European biodiversity to serve many research areas in biology, they have to be really exhaustive. In this regard, in addition to providing sample metadata recording guidelines, they also discuss the biases existing in sampling and sequencing projects. The first task for such a project is to be sure that the data they generate will be usable and available in the future (“[in] perpetuity", Böhne et al. 2024). The authors deployed a very efficient pipeline for conserving information on sampling: location, physical information, copies of tissues and of DNA, shipping, legal/ethical aspects regarding the Nagoya Protocol, etc., alongside a best-practice manual. This effort is linked to practical guides for the DNA extraction of specific taxa. More generally, these details enable “Findable, Accessible, Interoperable, and Reusable” (FAIR) principles (Wilkinson et al. 2016) to be followed. An important aspect of this paper, in addition to practical points, is the reflection upon the different biases inherent to the choice of sequenced samples. Acknowledging their own biases with regards to DNA extraction protocol efficiency, small genome size choice, as well as the availability of material (Nagoya Protocol aspects) and material transfer efficiency, the authors recommend in the future to not survey biodiversity by selecting one’s favorite samples or species, but also considering "orphan" taxa. Some of these "orphan" taxonomic groups belong to non-arthropod invertebrates but internal disparities are also prominent within other taxa. Finally, the implementation of the "Collective benefit, Authority to control, Responsibility, and Ethics" (CARE) principles (Carroll et al. 2021) will allow Indigenous rights to be considered when prioritizing samples, and to enable their "knowledge systems to permeate throughout the process of reference genome production and beyond" (Böhne et al. 2024). Last, but not least, as ERGA, including its Sampling and Sample Processing committee, is a large collective effort, it is very refreshing to read a paper starting with the acknowledgements and the roles of each member.
References Böhne A, Fernández R, Leonard JA, McCartney AM, McTaggart S, Melo-Ferreira J, Monteiro R, Oomen RA, Pettersson OV, Struck TH (2024) Contextualising samples: Supporting reference genomes of European biodiversity through sample and associated metadata collection. bioRxiv, ver. 3 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.28.546652 Carroll SR, Herczog E, Hudson M, Russell K, Stall S (2021) Operationalizing the CARE and FAIR Principles for Indigenous data futures. Scientific Data, 8, 108. https://doi.org/10.1038/s41597-021-00892-0 Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE, Bouwman J, Brookes AJ, Clark T, Crosas M, Dillo I, Dumon O, Edmunds S, Evelo CT, Finkers R, Gonzalez-Beltran A, Gray AJG, Groth P, Goble C, Grethe JS, Heringa J, ’t Hoen PAC, Hooft R, Kuhn T, Kok R, Kok J, Lusher SJ, Martone ME, Mons A, Packer AL, Persson B, Rocca-Serra P, Roos M, van Schaik R, Sansone S-A, Schultes E, Sengstag T, Slater T, Strawn G, Swertz MA, Thompson M, van der Lei J, van Mulligen E, Velterop J, Waagmeester A, Wittenburg P, Wolstencroft K, Zhao J, Mons B (2016) The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18 | Contextualising samples: Supporting reference genomes of European biodiversity through sample and associated metadata collection | Astrid Böhne, Rosa Fernández, Jennifer A. Leonard, Ann M. McCartney, Seanna McTaggart, José Melo-Ferreira, Rita Monteiro, Rebekah A. Oomen, Olga Vinnere Pettersson, Torsten H. Struck | <p>The European Reference Genome Atlas (ERGA) consortium aims to generate a reference genome catalogue for all of Europe's eukaryotic biodiversity. The biological material underlying this mission, the specimens and their derived samples, are provi... | | ERGA, ERGA BGE, ERGA Pilot, Evolutionary genomics | Francois Sabot | Julian Osuji, Francois Sabot, Anonymous | 2023-07-03 10:39:36 | |
07 Feb 2023
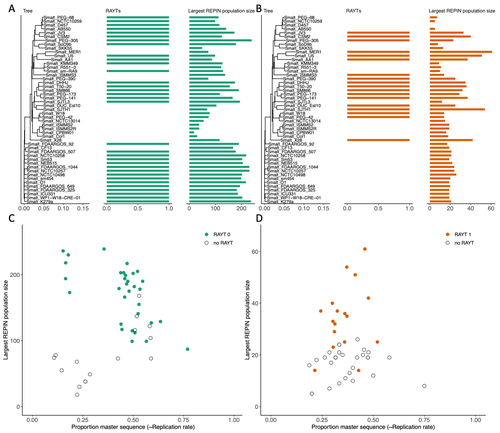
RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomesA workflow for studying enigmatic non-autonomous transposable elements across bacteriaRecommended by Gavin Douglas based on reviews by Sophie Abby and 1 anonymous reviewer
Repetitive extragenic palindromic sequences (REPs) are common repetitive elements in bacterial genomes (Gilson et al., 1984; Stern et al., 1984). In 2011, Bertels and Rainey identified that REPs are overrepresented in pairs of inverted repeats, which likely form hairpin structures, that they referred to as “REP doublets forming hairpins” (REPINs). Based on bioinformatics analyses, they argued that REPINs are likely selfish elements that evolved from REPs flanking particular transposes (Bertels and Rainey, 2011). These transposases, so-called REP-associated tyrosine transposases (RAYTs), were known to be highly associated with the REP content in a genome and to have characteristic upstream and downstream flanking REPs (Nunvar et al., 2010). The flanking REPs likely enable RAYT transposition, and their horizontal replication is physically linked to this process. In contrast, Bertels and Rainey hypothesized that REPINs are selfish elements that are highly replicated due to the similarity in arrangement to these RAYT-flanking REPs, but independent of RAYT transposition and generally with no impact on bacterial fitness (Bertels and Rainey, 2011). This last point was especially contentious, as REPINs are highly conserved within species (Bertels and Rainey, 2023), which is unusual for non-beneficial bacterial DNA (Mira et al., 2001). Bertels and Rainey have since refined their argument to be that REPINs must provide benefits to host cells, but that there are nonetheless signatures of intragenomic conflict in genomes associated with these elements (Bertels and Rainey, 2023). These signatures reflect the divergent levels of selections driving REPIN distribution: selection at the level of each DNA element and selection on each individual bacterium. I found this observation particularly interesting as I and my colleague recently argued that these divergent levels of selection, and the interaction between them, is key to understanding bacterial pangenome diversity (Douglas and Shapiro, 2021). REPINs could be an excellent system for investigating these levels of selection across bacteria more generally. The problem is that REPINs have not been widely characterized in bacterial genomes, partially because no bioinformatic workflow has been available for this purpose. To address this problem, Fortmann-Grote et al. (2023) developed RAREFAN, which is a web server for identifying RAYTs and associated REPINs in a set of input genomes. The authors showcase their tool by applying it to 49 Stenotrophomonas maltophilia genomes and providing examples of how to identify and assess RAYT-REPIN hits. The workflow requires several manual steps, but nonetheless represents a straightforward and standardized approach. Overall, this workflow should enable RAYTs and REPINs to be identified across diverse bacterial species, which will facilitate further investigation into the mechanisms driving their maintenance and spread. References Bertels F, Rainey PB (2023) Ancient Darwinian replicators nested within eubacterial genomes. BioEssays, 45, 2200085. https://doi.org/10.1002/bies.202200085 Bertels F, Rainey PB (2011) Within-Genome Evolution of REPINs: a New Family of Miniature Mobile DNA in Bacteria. PLOS Genetics, 7, e1002132. https://doi.org/10.1371/journal.pgen.1002132 Douglas GM, Shapiro BJ (2021) Genic Selection Within Prokaryotic Pangenomes. Genome Biology and Evolution, 13, evab234. https://doi.org/10.1093/gbe/evab234 Fortmann-Grote C, Irmer J von, Bertels F (2023) RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes. bioRxiv, 2022.05.22.493013, ver. 4 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.05.22.493013 Gilson E, Clément J m., Brutlag D, Hofnung M (1984) A family of dispersed repetitive extragenic palindromic DNA sequences in E. coli. The EMBO Journal, 3, 1417–1421. https://doi.org/10.1002/j.1460-2075.1984.tb01986.x Mira A, Ochman H, Moran NA (2001) Deletional bias and the evolution of bacterial genomes. Trends in Genetics, 17, 589–596. https://doi.org/10.1016/S0168-9525(01)02447-7 Nunvar J, Huckova T, Licha I (2010) Identification and characterization of repetitive extragenic palindromes (REP)-associated tyrosine transposases: implications for REP evolution and dynamics in bacterial genomes. BMC Genomics, 11, 44. https://doi.org/10.1186/1471-2164-11-44 Stern MJ, Ames GF-L, Smith NH, Clare Robinson E, Higgins CF (1984) Repetitive extragenic palindromic sequences: A major component of the bacterial genome. Cell, 37, 1015–1026. https://doi.org/10.1016/0092-8674(84)90436-7 | RAREFAN: A webservice to identify REPINs and RAYTs in bacterial genomes | Frederic Bertels, Julia von Irmer, Carsten Fortmann-Grote | <p style="text-align: justify;">Compared to eukaryotes, repetitive sequences are rare in bacterial genomes and usually do not persist for long. Yet, there is at least one class of persistent prokaryotic mobile genetic elements: REPINs. REPINs are ... | | Bacteria and archaea, Bioinformatics, Evolutionary genomics, Viruses and transposable elements | Gavin Douglas | 2022-06-07 08:21:34 | ||
15 Sep 2022
EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotesEukProt enables reproducible Eukaryota-wide protein sequence analysesRecommended by Gavin Douglas based on reviews by 2 anonymous reviewers
Comparative genomics is a general approach for understanding how genomes differ, which can be considered from many angles. For instance, this approach can delineate how gene content varies across organisms, which can lead to novel hypotheses regarding what those organisms do. It also enables investigations into the sequence-level divergence of orthologous DNA, which can provide insight into how evolutionary forces differentially shape genome content and structure across lineages. Burki F, Roger AJ, Brown MW, Simpson AGB (2020) The New Tree of Eukaryotes. Trends in Ecology & Evolution, 35, 43–55. https://doi.org/10.1016/j.tree.2019.08.008 Richter DJ, Berney C, Strassert JFH, Poh Y-P, Herman EK, Muñoz-Gómez SA, Wideman JG, Burki F, Vargas C de (2022) EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes. bioRxiv, 2020.06.30.180687, ver. 5 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2020.06.30.180687 Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE, Bouwman J, Brookes AJ, Clark T, Crosas M, Dillo I, Dumon O, Edmunds S, Evelo CT, Finkers R, Gonzalez-Beltran A, Gray AJG, Groth P, Goble C, Grethe JS, Heringa J, ’t Hoen PAC, Hooft R, Kuhn T, Kok R, Kok J, Lusher SJ, Martone ME, Mons A, Packer AL, Persson B, Rocca-Serra P, Roos M, van Schaik R, Sansone S-A, Schultes E, Sengstag T, Slater T, Strawn G, Swertz MA, Thompson M, van der Lei J, van Mulligen E, Velterop J, Waagmeester A, Wittenburg P, Wolstencroft K, Zhao J, Mons B (2016) The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18 | EukProt: A database of genome-scale predicted proteins across the diversity of eukaryotes | Daniel J. Richter, Cédric Berney, Jürgen F. H. Strassert, Yu-Ping Poh, Emily K. Herman, Sergio A. Muñoz-Gómez, Jeremy G. Wideman, Fabien Burki, Colomban de Vargas | <p style="text-align: justify;">EukProt is a database of published and publicly available predicted protein sets selected to represent the breadth of eukaryotic diversity, currently including 993 species from all major supergroups as well as orpha... | | Bioinformatics, Evolutionary genomics | Gavin Douglas | 2022-06-08 14:19:28 | ||
24 Feb 2023

MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomesA unique and customizable approach for functionally annotating prokaryotic genomesRecommended by Gavin Douglas based on reviews by Kwee Boon Brandon Seah and Max Emil Schön
Macromolecular System Finder (MacSyFinder) v2 (Néron et al., 2023) is a newly updated approach for performing functional annotation of prokaryotic genomes (Abby et al., 2014). This tool parses an input file of protein sequences from a single genome (either ordered by genome location or unordered) and identifies the presence of specific cellular functions (referred to as “systems”). These systems are called based on two criteria: (1) that the "quorum" of a minimum set of core proteins involved is reached the “quorum” of a minimum set of core proteins being involved that are present, and (2) that the genes encoding these proteins are in the expected genomic organization (e.g., within the same order in an operon), when ordered data is provided. I believe the MacSyFinder approach represents an improvement over more commonly used methods exactly because it can incorporate such information on genomic organization, and also because it is more customizable. Before properly appreciating these points, it is worth noting the norms and key challenges surrounding high-throughput functional annotation of prokaryotic genomes. Genome sequences are being added to online repositories at increasing rates, which has led to an enormous amount of bacterial genome diversity available to investigate (Altermann et al., 2022). A key aspect of understanding this diversity is the functional annotation step, which enables genes to be grouped into more biologically interpretable categories. For instance, gene calls can be mapped against existing Clusters of Orthologous Genes, which are themselves grouped into general categories such as ‘Transcription’ and ‘Lipid metabolism’ (Galperin et al., 2021). This approach is valuable but is primarily used for global summaries of functional annotations within a genome: for example, it could be useful to know that a genome is particularly enriched for genes involved in lipid metabolism. However, knowing that a particular gene is involved in the general process of lipid metabolism is less likely to be actionable. In other words, the desired specificity of a gene’s functional annotation will depend on the exact question being investigated. There is no shortage of functional ontologies in genomics that can be applied for this purpose (Douglas and Langille, 2021), and researchers are often overwhelmed by the choice of which functional ontology to use. In this context, giving researchers the ability to precisely specify the gene families and operon structures they are interested in identifying across genomes provides useful control over what precise functions they are profiling. Of course, most researchers will lack the information and/or expertise to fully take advantage of MacSyFinder’s customizable features, but having this option for specialized purposes is valuable. The other MacSyFinder feature that I find especially noteworthy is that it can incorporate genomic organization (e.g., of genes ordered in operons) when calling systems. This is a rare feature among commonly used tools for functional annotation and likely results in much higher specificity. As the authors note, this capability makes the co-occurrence of paralogs, and other divergent genes that share sequence similarity, to contribute less noise (i.e., they result in fewer false positive calls). It is important to emphasize that these features are not new additions in MacSyFinder v2, but there are many other valuable changes. Most practically, this release is written in Python 3, rather than the obsolete Python 2.7, and was made more computationally efficient, which will enable MacSyFinder to be more widely used and more easily maintained moving forward. In addition, the search algorithm for analyzing individual proteins was fundamentally updated as well. The authors show that their improvements to the search algorithm result in an 8% and 20% increase in the number of identified calls for single and multi-locus secretion systems, respectively. Taken together, MacSyFinder v2 represents both practical and scientific improvements over the previous version, which will be of great value to the field. References Abby SS, Néron B, Ménager H, Touchon M, Rocha EPC (2014) MacSyFinder: A Program to Mine Genomes for Molecular Systems with an Application to CRISPR-Cas Systems. PLOS ONE, 9, e110726. https://doi.org/10.1371/journal.pone.0110726 Altermann E, Tegetmeyer HE, Chanyi RM (2022) The evolution of bacterial genome assemblies - where do we need to go next? Microbiome Research Reports, 1, 15. https://doi.org/10.20517/mrr.2022.02 Douglas GM, Langille MGI (2021) A primer and discussion on DNA-based microbiome data and related bioinformatics analyses. Peer Community Journal, 1. https://doi.org/10.24072/pcjournal.2 Galperin MY, Wolf YI, Makarova KS, Vera Alvarez R, Landsman D, Koonin EV (2021) COG database update: focus on microbial diversity, model organisms, and widespread pathogens. Nucleic Acids Research, 49, D274–D281. https://doi.org/10.1093/nar/gkaa1018 Néron B, Denise R, Coluzzi C, Touchon M, Rocha EPC, Abby SS (2023) MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes. bioRxiv, 2022.09.02.506364, ver. 2 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2022.09.02.506364 | MacSyFinder v2: Improved modelling and search engine to identify molecular systems in genomes | Bertrand Néron, Rémi Denise, Charles Coluzzi, Marie Touchon, Eduardo P. C. Rocha, Sophie S. Abby | <p style="text-align: justify;">Complex cellular functions are usually encoded by a set of genes in one or a few organized genetic loci in microbial genomes. Macromolecular System Finder (MacSyFinder) is a program that uses these properties to mod... | | Bacteria and archaea, Bioinformatics, Functional genomics | Gavin Douglas | Kwee Boon Brandon Seah, Max Emil Schön | 2022-09-09 10:30:31 | |
01 May 2024
Evolution of ion channels in cetaceans: A natural experiment in the tree of lifePositive selection acted upon cetacean ion channels during the aquatic transitionRecommended by Gavin Douglas based on reviews by 2 anonymous reviewers
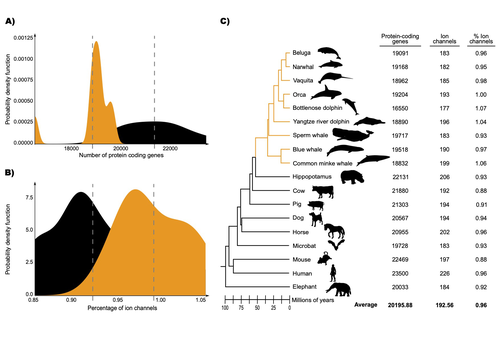
The transition of cetaceans (whales, dolphins, and porpoises) from terrestrial to aquatic lifestyles is a striking example of natural selection driving major phenotypic changes (Figure 1). For instance, cetaceans have evolved the ability to withstand high pressure and to store oxygen for long periods, among other adaptations (Das et al. 2023). Many phenotypic changes, such as shifts in organ structure, have been well-characterized through fossils (Thewissen et al. 2009). Although such phenotypic transitions are now well understood, we have only a partial understanding of the underlying genetic mechanisms. Scanning for signatures of adaptation in genes related to phenotypes of interest is one approach to better understand these mechanisms. This was the focus of Uribe and colleagues’ (2024) work, who tested for such signatures across cetacean protein-coding genes.
Figure 1: The skeletons of Ambulocetus (an early whale; top) and Pakicetus (the earliest known cetacean, which lived about 50 million years ago; bottom). Copyright: J. G. M. Thewissen. Displayed here with permission from the copyright holder.
The authors were specifically interested in investigating the evolution of ion channels, as these proteins play fundamental roles in physiological processes. An important aspect of their work was to develop a bioinformatic pipeline to identify orthologous ion channel genes across a set of genomes. After applying their bioinformatic workflow to 18 mammalian species (including nine cetaceans), they conducted tests to find out whether these genes showed signatures of positive selection in the cetacean lineage. For many ion channel genes, elevated ratios of non-synonymous to synonymous substitution rates were detected (for at least a subset of sites, and not necessarily the entire coding region of the genes). The genes concerned were enriched for several functions, including heart and nervous system-related phenotypes. One top gene hit among the putatively selected genes was SCN5A, which encodes a sodium channel expressed in the heart. Interestingly, the authors noted a specific amino acid replacement, which is associated with sensitivity to the toxin tetrodotoxin in other lineages. This substitution appears to have occurred in the common ancestor of toothed whales, and then was reversed in the ancestor of bottlenose dolphins. The authors describe known bottlenose dolphin interactions with toxin-producing pufferfish that could result in high tetrodotoxin exposure, and thus perhaps higher selection for tetrodotoxin resistance. Although this observation is intriguing, the authors emphasize it requires experimental confirmation. The authors also recapitulated the previously described observation (Yim et al. 2014; Huelsmann et al. 2019) that cetaceans have fewer protein-coding genes compared to terrestrial mammals, on average. This signal has previously been hypothesized to partially reflect adaptive gene loss. For example, specific gene loss events likely decreased the risk of developing blood clots while diving (Huelsmann et al. 2019). Uribe and colleagues also considered overall gene turnover rate, which encompasses gene copy number variation across lineages, and found the cetacean gene turnover rate to be three times higher than that of terrestrial mammals. Finally, they found that cetaceans have a higher proportion of ion channel genes (relative to all protein-coding genes in a genome) compared to terrestrial mammals. Similar investigations of the relative non-synonymous to synonymous substitution rates across cetacean and terrestrial mammal orthologs have been conducted previously, but these have primarily focused on dolphins as the sole cetacean representative (McGowen et al. 2012; Nery et al. 2013; Sun et al. 2013). These projects have also been conducted across a large proportion of orthologous genes, rather than a subset with a particular function. Performing proteome-wide investigations can be valuable in that they summarize the genome-wide signal, but can suffer from a high multiple testing burden. More generally, investigating a more targeted question, such as the extent of positive selection acting on ion channels in this case, or on genes potentially linked to cetaceans’ increased brain sizes (McGowen et al. 2011) or hypoxia tolerance (Tian et al. 2016), can be easier to interpret, as opposed to summarizing broader signals. However, these smaller-scale studies can also experience a high multiple testing burden, especially as similar tests are conducted across numerous studies, which often is not accounted for (Ioannidis 2005). In addition, integrating signals across the entire genome will ultimately be needed given that many genetic changes undoubtedly underlie cetaceans’ phenotypic diversification. As highlighted by the fact that past genome-wide analyses have produced some differing biological interpretations (McGowen et al. 2012; Nery et al. 2013; Sun et al. 2013), this is not a trivial undertaking. Nonetheless, the work performed in this preprint, and in related research, is valuable for (at least) three reasons. First, although it is a challenging task, a better understanding of the genetic basis of cetacean phenotypes could have benefits for many aspects of cetacean biology, including conservation efforts. In addition, the remarkable phenotypic shifts in cetaceans make the question of what genetic mechanisms underlie these changes intrinsically interesting to a wide audience. Last, since the cetacean fossil record is especially well-documented (Thewissen et al. 2009), cetaceans represent an appealing system to validate and further develop statistical methods for inferring adaptation from genetic data. Uribe and colleagues’ (2024) analyses provide useful insights relevant to each of these points, and have generated intriguing hypotheses for further investigation.
Das K, Sköld H, Lorenz A, Parmentier E (2023) Who are the marine mammals? In: “Marine Mammals: A Deep Dive into the World of Science”. Brennecke D, Knickmeier K, Pawliczka I, Siebert U, Wahlberg, M (editors). Springer, Cham. p. 1–14. https://doi.org/10.1007/978-3-031-06836-2_1 Huelsmann M, Hecker N, Springer MS, Gatesy J, Sharma V, Hiller M (2019) Genes lost during the transition from land to water in cetaceans highlight genomic changes associated with aquatic adaptations. Science Advances, 5, eaaw6671. https://doi.org/10.1126/sciadv.aaw6671 Ioannidis JPA (2005) Why most published research findings are false. PLOS Medicine, 2, e124. https://doi.org/10.1371/journal.pmed.0020124 McGowen MR, Montgomery SH, Clark C, Gatesy J (2011) Phylogeny and adaptive evolution of the brain-development gene microcephalin (MCPH1) in cetaceans. BMC Evolutionary Biology, 11, 98. https://doi.org/10.1186/1471-2148-11-98 McGowen MR, Grossman LI, Wildman DE (2012) Dolphin genome provides evidence for adaptive evolution of nervous system genes and a molecular rate slowdown. Proceedings of the Royal Society B: Biological Sciences, 279, 3643–3651. https://doi.org/10.1098/rspb.2012.0869 Nery MF, González DJ, Opazo JC (2013) How to make a dolphin: molecular signature of positive selection in cetacean genome. PLOS ONE, 8, e65491. https://doi.org/10.1371/journal.pone.0065491 Sun YB, Zhou WP, Liu HQ, Irwin DM, Shen YY, Zhang YP (2013) Genome-wide scans for candidate genes involved in the aquatic adaptation of dolphins. Genome Biology and Evolution, 5, 130–139. https://doi.org/10.1093/gbe/evs123 Tian R, Wang Z, Niu X, Zhou K, Xu S, Yang G (2016) Evolutionary genetics of hypoxia tolerance in cetaceans during diving. Genome Biology and Evolution, 8, 827–839. https://doi.org/10.1093/gbe/evw037 Thewissen JGM, Cooper LN, George JC, Bajpai (2009) From land to water: the origin of whales, dolphins, and porpoises. Evolution: Education and Outreach, 2, 272–288. https://doi.org/10.1007/s12052-009-0135-2 Uribe C, Nery M, Zavala K, Mardones G, Riadi G, Opazo J (2024) Evolution of ion channels in cetaceans: A natural experiment in the tree of life. bioRxiv, ver. 8 peer-reviewed and recommended by Peer Community in Genomics. https://doi.org/10.1101/2023.06.15.545160 Yim HS, Cho YS, Guang X, Kang SG, Jeong JY, Cha SS, Oh HM, Lee JH, Yang EC, Kwon KK, et al. (2014) Minke whale genome and aquatic adaptation in cetaceans. Nature Genetics, 46, 88–92. https://doi.org/10.1038/ng.2835
| Evolution of ion channels in cetaceans: A natural experiment in the tree of life | Cristóbal Uribe, Mariana F. Nery, Kattina Zavala, Gonzalo A. Mardones, Gonzalo Riadi & Juan C. Opazo | <p>Cetaceans could be seen as a natural experiment within the tree of life in which a mammalian lineage changed from terrestrial to aquatic habitats. This shift involved extensive phenotypic modifications, which represent an opportunity to explore... | | Evolutionary genomics | Gavin Douglas | 2023-07-04 20:53:46 | ||
02 Apr 2021

Semi-artificial datasets as a resource for validation of bioinformatics pipelines for plant virus detectionToward a critical assessment of virus detection in plantsRecommended by Hadi Quesneville based on reviews by Alexander Suh and 1 anonymous reviewerThe advent of High Throughput Sequencing (HTS) since the last decade has revealed previously unsuspected diversity of viruses as well as their (sometimes) unexpected presence in some healthy individuals. These results demonstrate that genomics offers a powerful tool for studying viruses at the individual level, allowing an in-depth inventory of those that are infecting an organism. Such approaches make it possible to study viromes with an unprecedented level of detail, both qualitative and quantitative, which opens new venues for analyses of viruses of humans, animals and plants. Consequently, the diagnostic field is using more and more HTS, fueling the need for efficient and reliable bioinformatics tools. Many such tools have already been developed, but in plant disease diagnostics, validation of the bioinformatics pipelines used for the detection of viruses in HTS datasets is still in its infancy. There is an urgent need for benchmarking the different tools and algorithms using well-designed reference datasets generated for this purpose. This is a crucial step to move forward and to improve existing solutions toward well-standardized bioinformatics protocols. This context has led to the creation of the Plant Health Bioinformatics Network (PHBN), a Euphresco network project aiming to build a bioinformatics community working on plant health. One of their objectives is to provide researchers with open-access reference datasets allowing to compare and validate virus detection pipelines. In this framework, Tamisier et al. [1] present real, semi-artificial, and completely artificial datasets, each aimed at addressing challenges that could affect virus detection. These datasets comprise real RNA-seq reads from virus-infected plants as well as simulated virus reads. Such a work, providing open-access datasets for benchmarking bioinformatics tools, should be encouraged as they are key to software improvement as demonstrated by the well-known success story of the protein structure prediction community: their pioneer community-wide effort, called Critical Assessment of protein Structure Prediction (CASP)[2], has been providing research groups since 1994 with an invaluable way to objectively test their structure prediction methods, thereby delivering an independent assessment of state-of-art protein-structure modelling tools. Following this success, many other bioinformatic community developed similar “competitions”, such as RNA-puzzles [3] to predict RNA structures, Critical Assessment of Function Annotation [4] to predict gene functions, Critical Assessment of Prediction of Interactions [5] to predict protein-protein interactions, Assemblathon [6] for genome assembly, etc. These are just a few examples from a long list of successful initiatives. Such efforts enable rigorous assessments of tools, stimulate the developers’ creativity, but also provide user communities with a state-of-art evaluation of available tools. Inspired by these success stories, the authors propose a “VIROMOCK challenge” [7], asking researchers in the field to test their tools and to provide feedback on each dataset through a repository. This initiative, if well followed, will undoubtedly improve the field of virus detection in plants, but also probably in many other organisms. This will be a major contribution to the field of viruses, leading to better diagnostics and, consequently, a better understanding of viral diseases, thus participating in promoting human, animal and plant health. References [1] Tamisier, L., Haegeman, A., Foucart, Y., Fouillien, N., Al Rwahnih, M., Buzkan, N., Candresse, T., Chiumenti, M., De Jonghe, K., Lefebvre, M., Margaria, P., Reynard, J.-S., Stevens, K., Kutnjak, D. and Massart, S. (2021) Semi-artificial datasets as a resource for validation of bioinformatics pipelines for plant virus detection. Zenodo, 4273791, version 4 peer-reviewed and recommended by Peer community in Genomics. doi: https://doi.org/10.5281/zenodo.4273791 [2] Critical Assessment of protein Structure Prediction” (CASP) - https://en.wikipedia.org/wiki/CASP [3] RNA-puzzles - https://www.rnapuzzles.org [4] Critical Assessment of Function Annotation (CAFA) - https://en.wikipedia.org/wiki/Critical_Assessment_of_Function_Annotation [5] Critical Assessment of Prediction of Interactions (CAPI) - https://en.wikipedia.org/wiki/Critical_Assessment_of_Prediction_of_Interactions [6] Assemblathon - https://assemblathon.org [7] VIROMOCK challenge - https://gitlab.com/ilvo/VIROMOCKchallenge | Semi-artificial datasets as a resource for validation of bioinformatics pipelines for plant virus detection | Lucie Tamisier, Annelies Haegeman, Yoika Foucart, Nicolas Fouillien, Maher Al Rwahnih, Nihal Buzkan, Thierry Candresse, Michela Chiumenti, Kris De Jonghe, Marie Lefebvre, Paolo Margaria, Jean Sébastien Reynard, Kristian Stevens, Denis Kutnjak, Séb... | <p>The widespread use of High-Throughput Sequencing (HTS) for detection of plant viruses and sequencing of plant virus genomes has led to the generation of large amounts of data and of bioinformatics challenges to process them. Many bioinformatics... | | Bioinformatics, Plants, Viruses and transposable elements | Hadi Quesneville | 2020-11-27 14:31:47 |





